os-learning
os-learning
实验任务
- 熟悉 hit-oslab 实验环境
- 修改 bootsect.s 和 setup.s 完成系统引导
- 添加两个系统调用并用于测试程序
- 基于模板 “process.c” 编写多进程的样本程序并输出日志
- 重写 switch_to 完成堆栈切换实现 TSSS
- 用信号量解决生产者—消费者问题
- Bochs 调试工具跟踪 Linux 0.11 的地址映射过程、为程序增加共享内存功能
- 修改 Linux 0.11 对键盘输入和字符显示进行控制
- 在 Linux 0.11 上实现 proc 文件系统内的 psinfo 结点
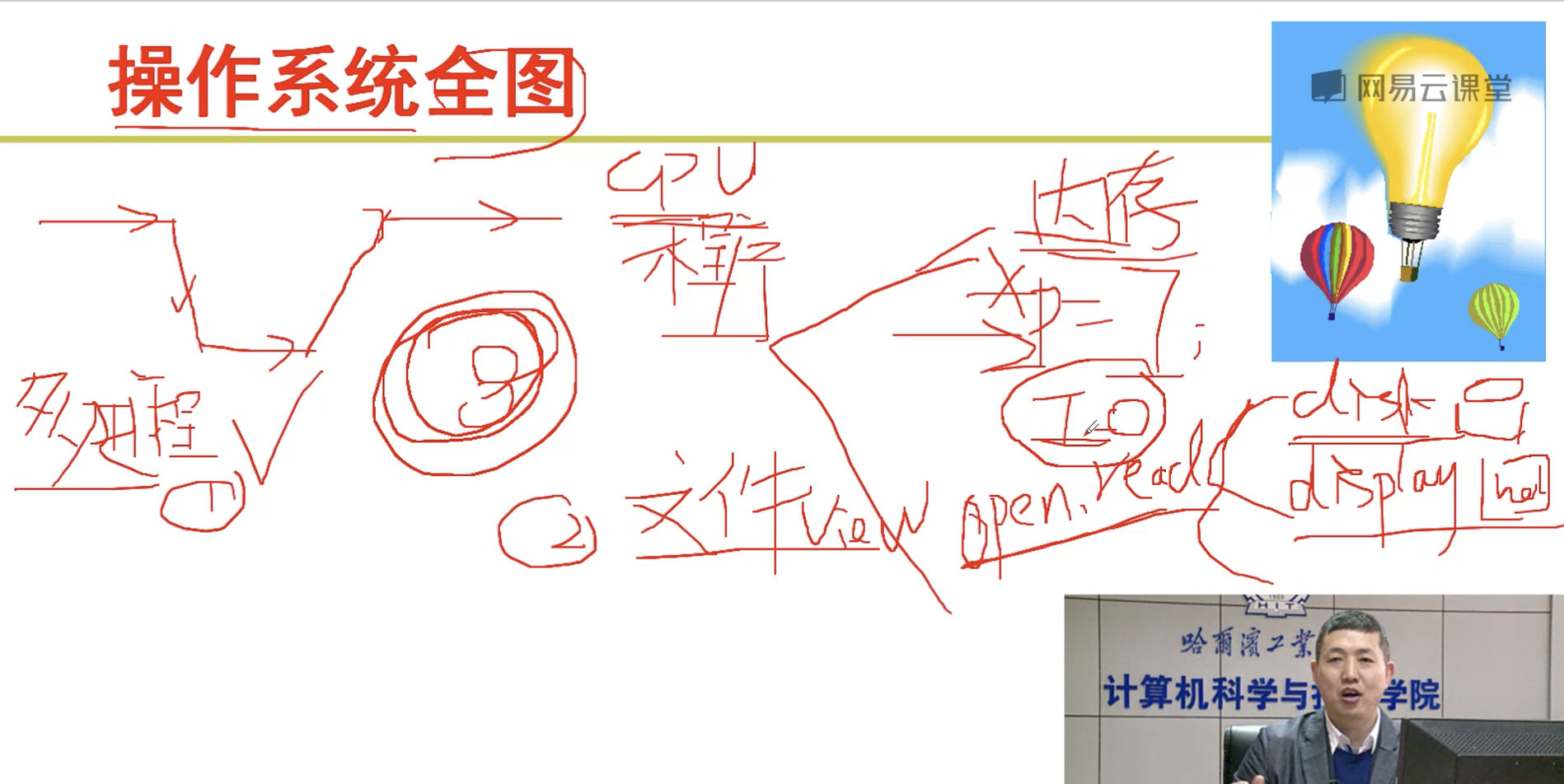
1. 操作系统基础
我们首先介绍了什么是操作系统?然后我们学习了计算机的发展。
从白纸到图灵机(只可以计算),从图灵机到通用图灵机(可以做其他工作),从通用图灵机到计算机。提出了存储计算的思想。
下面让我们来研究下操作系统是怎么启动的。
1.1 操作系统的启动
来自《Linux内核完全注释》第六章。
CS为代码段寄存器,IP为指令指针寄存器。
当 PC 的电源打开后 :
(1) x86 PC刚开机时CPU处于实模式
(2)开机时,CS=0xFFFF; IP=0x0000
(3)寻址0xFFFF0(ROM BIOS映射区)
(4)检查RAM,键盘,显示器,软硬磁盘
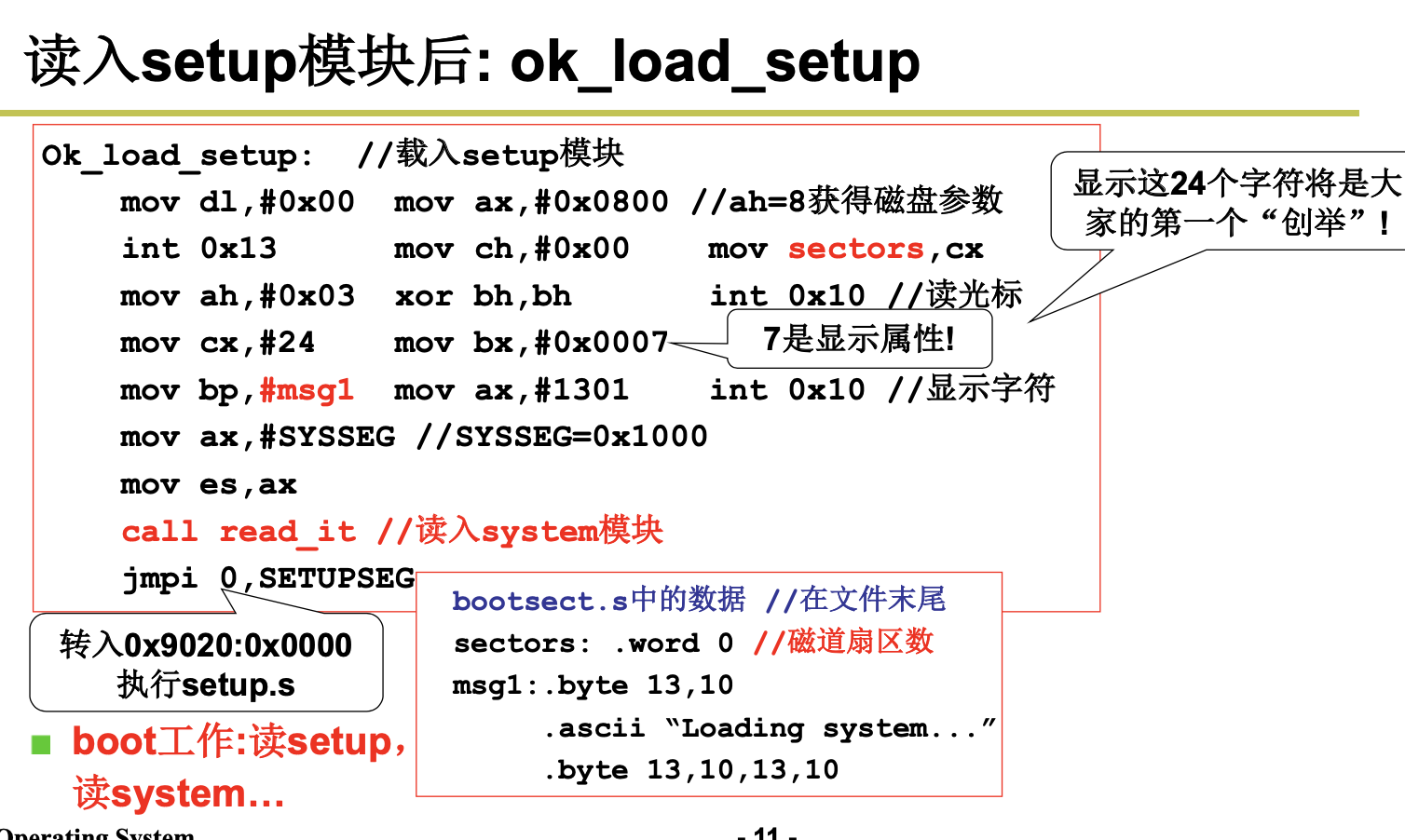
(5) 将磁盘0磁道0扇区读入0x7c00处 ,从磁盘引导扇区读入的那512个字节 ,硬盘的第一个扇区上存放着开机后执行的第一段我们可以控制的程序。
(6) 设置cs=0x07c0,ip=0x0000

1.1.1 bootsect.S
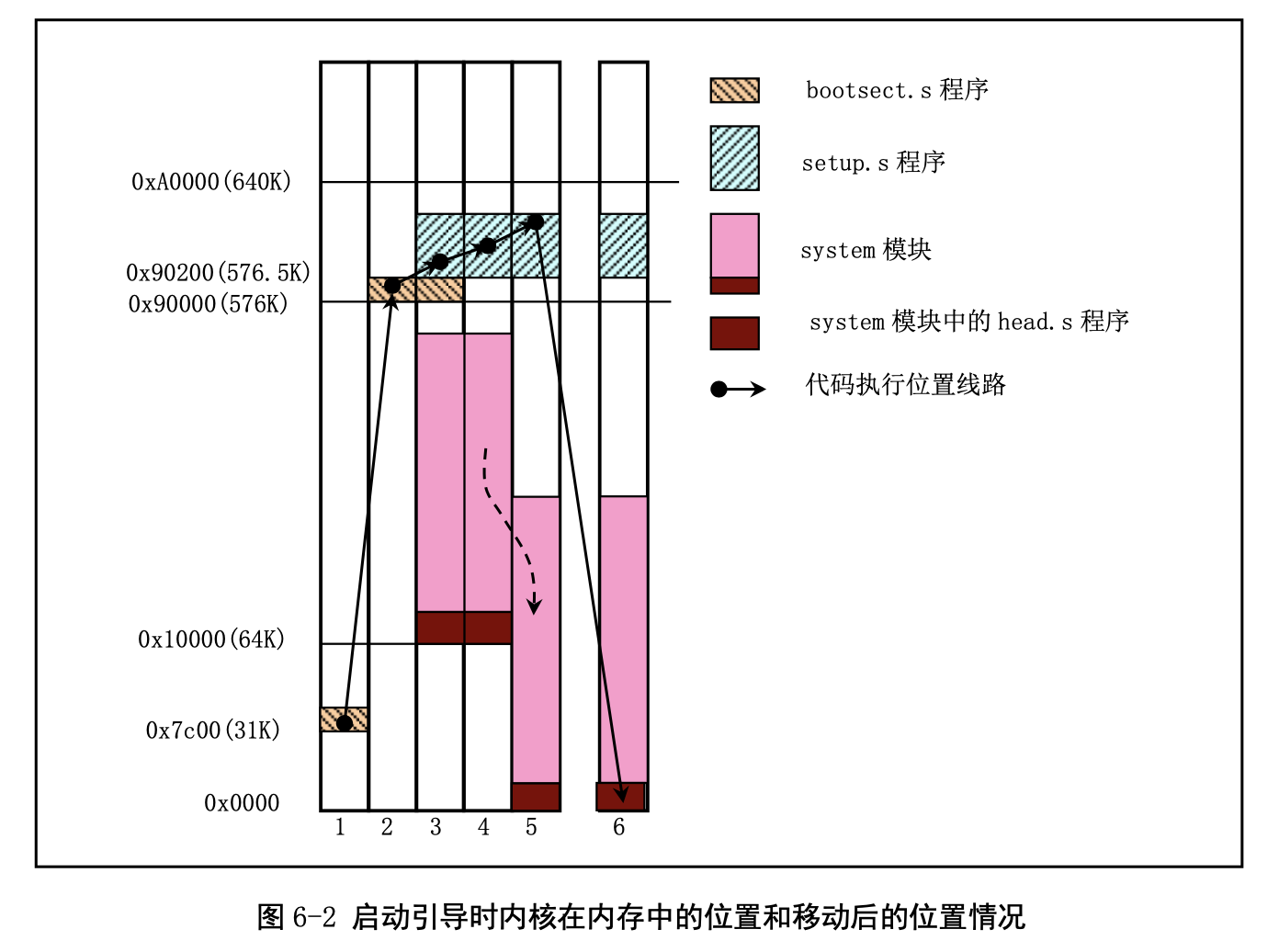
bootsect.S 代码是磁盘引导块程序,驻留在磁盘的第一个扇区中(引导扇区,0 磁道(柱面),0 磁头, 第 1 个扇区)。在 PC 机加电、ROM BIOS 自检后,ROM BIOS 会把引导扇区代码 bootsect 加载到内存地 址 0x7C00 开始处并执行之。在 bootsect 代码执行期间,它会将自己移动到内存绝对地址 0x90000 开始处 并继续执行。该程序的主要作用是首先把从磁盘第 2 个扇区开始的 4 个扇区的 setup 模块(由 setup.s 编 译而成)加载到内存紧接着 bootsect 后面位置处(0x90200),然后利用 BIOS 中断 0x13 取磁盘参数表中 当前启动引导盘的参数,接着在屏幕上显示“Loading system…”字符串。再者把磁盘上 setup 模块后面的 system 模块加载到内存 0x10000 开始的地方。随后确定根文件系统的设备号。若没有指定,则根据所保 存的引导盘的每磁道扇区数判别出盘的类型和种类(是 1.44M A 盘吗?),并保存其设备号于 root_dev (引导块的 508 地址处)中。最后长跳转到 setup 程序开始处(0x90200)去执行 setup 程序。在磁盘上, 引导块、setup 模块和 system 模块的扇区位置和大小示意图见图 6-3 所示。


1.1.2 setup.s
setup.S 是一个操作系统加载程序,它的主要作用是利用 ROM BIOS 中断读取机器系统数据,并将这 些数据保存到 0x90000 开始的位置(覆盖掉了 bootsect 程序所在的地方)。
然后 setup 程序将 system 模块从 0x10000-0x8ffff 整块向下移动到内存绝对地址 0x00000 处(当时认 为内核系统模块 system 的长度不会超过此值:512KB)。接下来加载中断描述符表寄存器(IDTR)和全局 描述符表寄存器(GDTR),开启 A20 地址线,重新设置两个中断控制芯片 8259A,将硬件中断号重新设 置为 0x20 - 0x2f。最后设置 CPU 的控制寄存器 CR0(也称机器状态字),进入 32 位保护模式运行,并跳 转到位于 system 模块最前面部分的 head.s 程序继续运行。


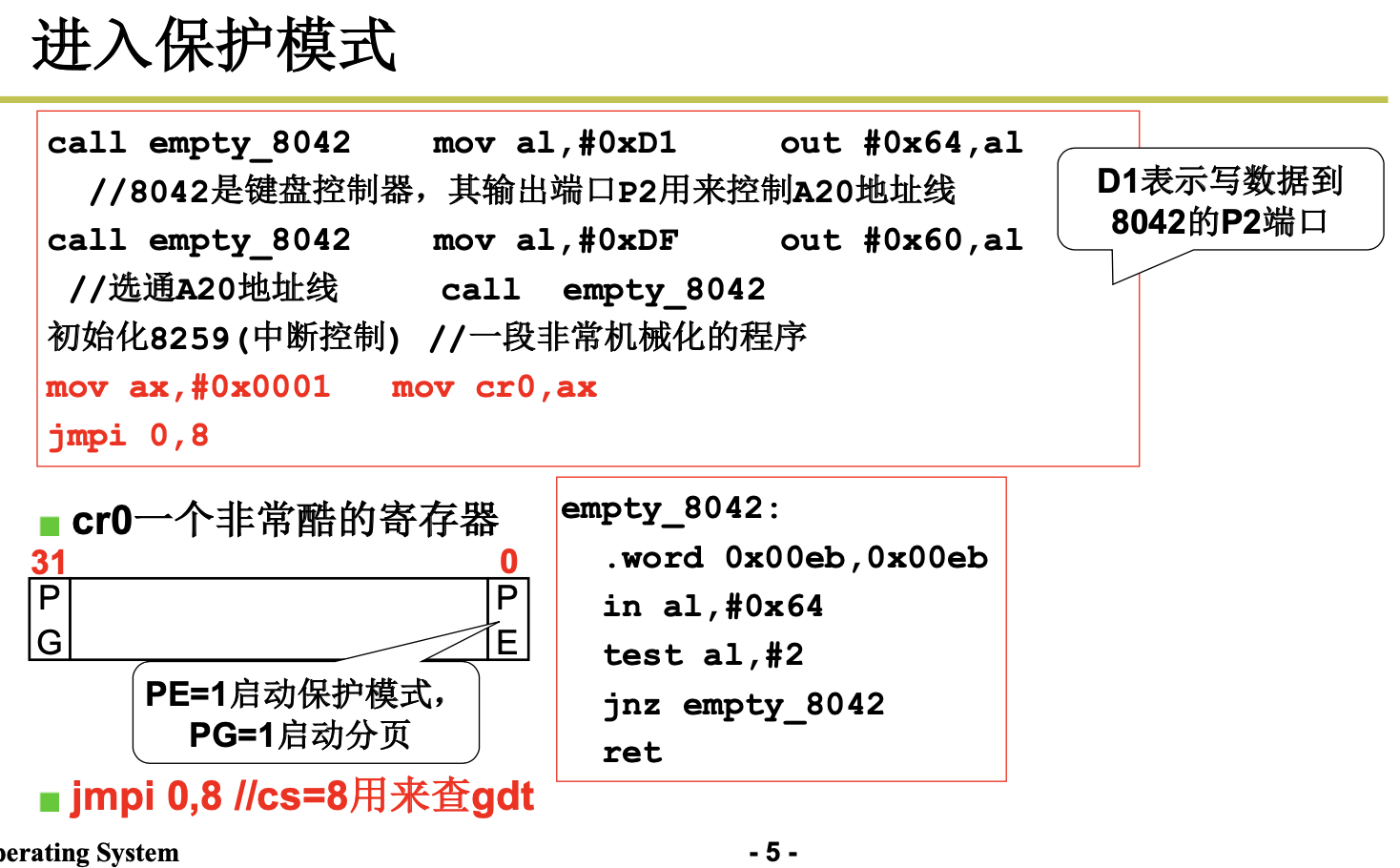

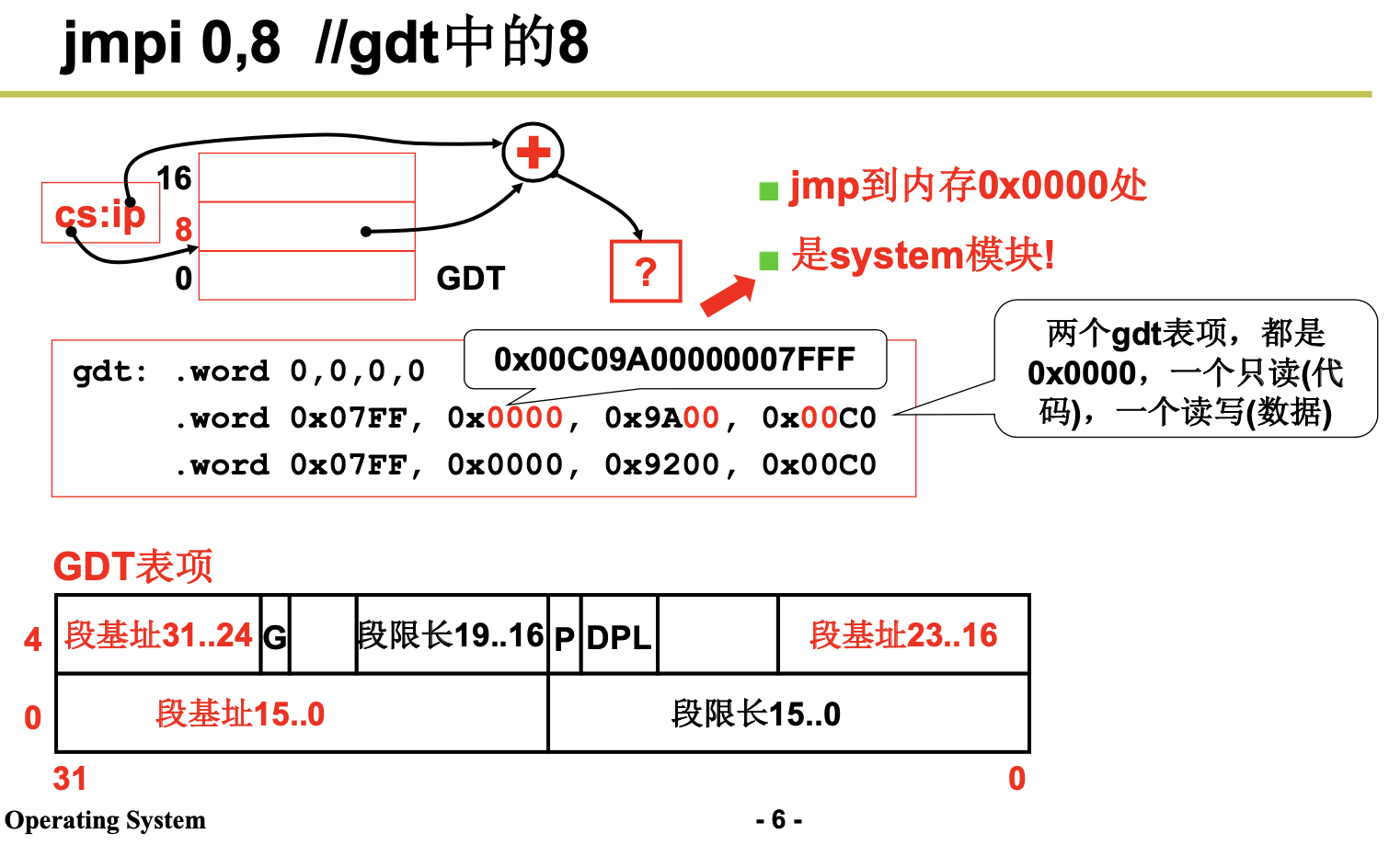
1.1.3 head.s
head.s 程序在被编译生成目标文件后会与内核其他程序的目标文件一起被链接成 system 模块,并位 于 system 模块的最前面开始部分。这也就是为什么称其为头部(head)程序的原因。system 模块将被放置 在磁盘上 setup 模块之后开始的扇区中,即从磁盘上第 6 个扇区开始放置。一般情况下 Linux 0.12 内核的 system 模块大约有 120KB 左右,因此在磁盘上大约占 240 个扇区。


这段程序实际上处于内存绝对地址 0 处开始的地方。这个程序的功能比较单一。首先它加载各个数 据段寄存器,重新设置中断描述符表 IDT,共 256 项。

接着程序设置管理内存的分页处理机制,将页目录表放在绝对物理地址 0 开始处(也是本程序所处 的物理内存位置,因此这段程序已执行部分将被覆盖掉),紧随后面会放置共可寻址 16MB 内存的 4 个 页表,并分别设置它们的表项。
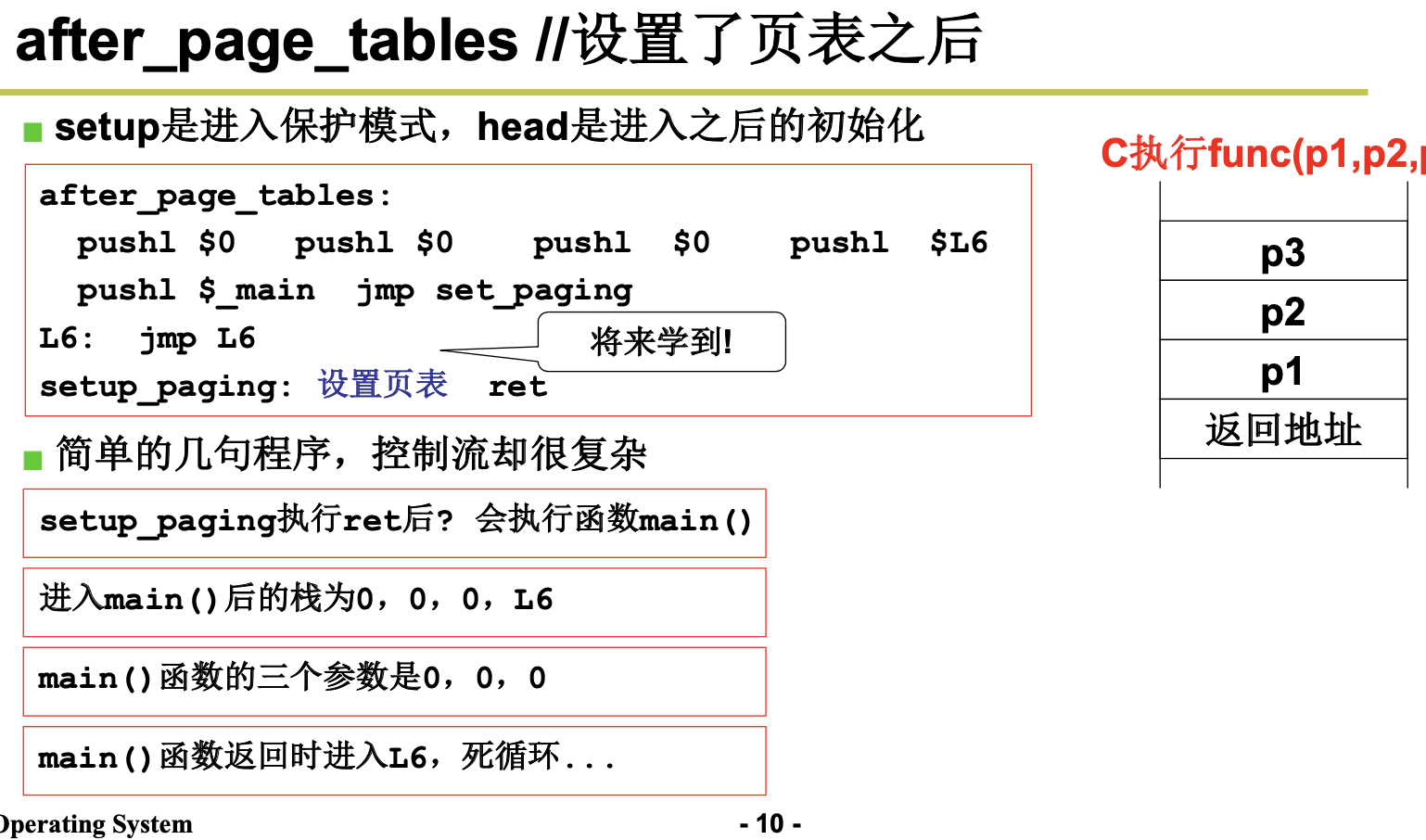
最后,head.s 程序利用返回指令将预先放置在堆栈中的/init/main.c 程序的入口地址弹出,去运行 main() 程序。

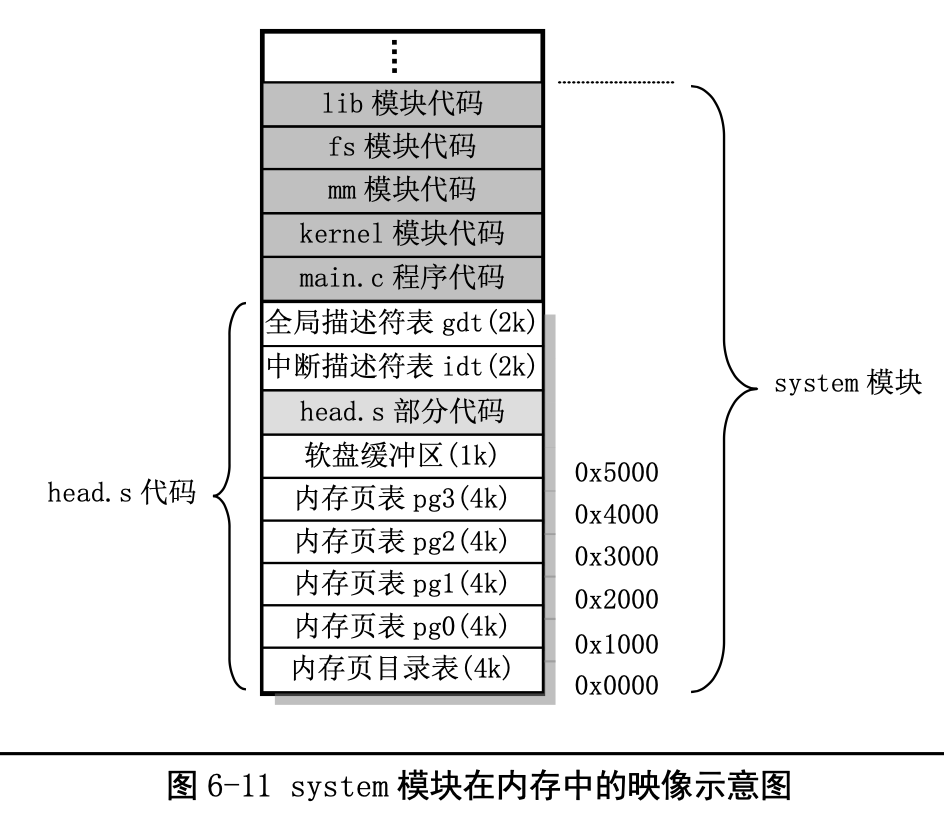
总结:引导加载程序 bootsect.S 将 setup.s 代码和 system 模块加载到内存中,并且分别把自己和 setup.s 代码 移动到物理内存 0x90000 和 0x90200 处后,就把执行权交给了 setup 程序。其中 system 模块的首部包含 有 head.s 代码。
setup 程序的主要作用是利用 ROM BIOS 的中断程序获取机器的一些基本参数,并保存在 0x90000 开始的内存块中,供后面程序使用。同时把 system 模块往下移动到物理地址 0x00000 开始处,这样,system 中的 head.s 代码就处在 0x00000 开始处了。然后加载描述符表基地址到描述符表寄存器中,为进行 32 位保护模式下的运行作好准备。接下来对中断控制硬件进行重新设置,最后通过设置机器控制寄存器 CR0 并跳转到 system 模块的 head.s 代码开始处,使 CPU 进入 32 位保护模式下运行。
Head.s 代码的主要作用是初步初始化中断描述符表中的 256 项门描述符,检查 A20 地址线是否已经 打开,测试系统是否含有数学协处理器。然后初始化内存页目录表,为内存的分页管理作好准备工作。 最后跳转到 system 模块中的初始化程序 init/main.c 中继续执行。
1.2 初始化
在内核源代码的 init/目录中只有一个 main.c 文件。系统在执行完 boot/head.s 程序后就会将执行权交 给 main.c。
main.c 程序首先利用前面 setup.s 程序取得的机器参数设置系统的根文件设备号以及一些内存全局变 量。这些内存变量指明了主内存区的开始地址、系统所拥有的内存容量和作为高速缓冲区内存的末端地 址。如果还定义了虚拟盘(RAMDISK),则主内存区将适当减少。
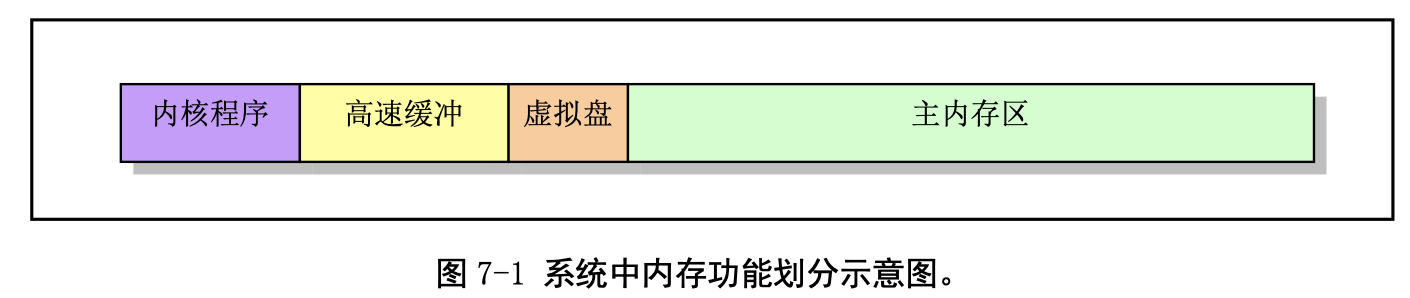
然后,内核进行各方面的硬件初始化工作。包括陷阱门、块设备、字符设备和 tty,还包括人工设置 第一个任务(task 0)。待所有初始化工作完成后,程序就设置中断允许标志以开启中断,并切换到任务 0 中运行。到此时,可以说内核已基本完成所有设置工作。接下来内核会通过任务 0 创建几个最初的任 务,运行 shell 程序并显示命令行提示符,从而 Linux 系统进入正常运行阶段。
内核初始化程序流程
在整个内核完成初始化后,内核将执行控制权切换到了用户模式(任务 0),也即 CPU 从 0 特权级 切换到了第 3 特权级。此时 main.c 的主程序就工作在任务 0 中。然后系统第一次调用进程创建函数 fork(), 创建出一个用于运行 init()的子进程(通常被称为 init 进程)。系统整个初始化过程见图 7-2 所示。
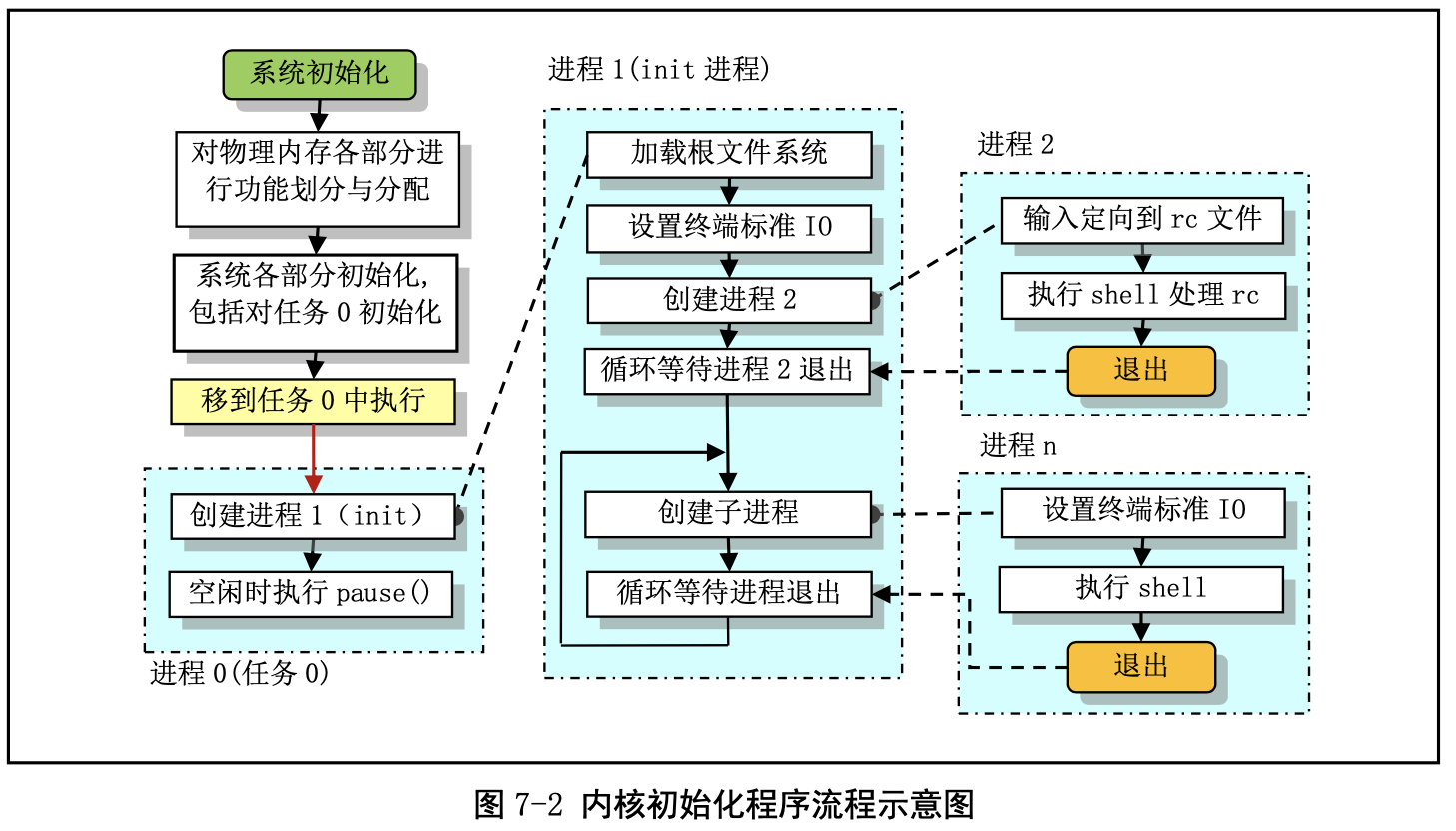
由图可见,main.c 程序首先确定如何分配使用系统物理内存,然后调用内核各部分的初始化函数分 别对内存管理、中断处理、块设备和字符设备、进程管理以及硬盘和软盘硬件进行初始化处理。在完成 了这些操作之后,系统各部分已经处于可运行状态。此后程序把自己“手工”移动到任务 0(进程 0)中 运行,并使用 fork()调用首次创建出进程 1(init 进程),并在其中调用 init()函数。在该函数中程序将继 续进行应用环境的初始化并执行 shell 登录程序。而原进程 0 则会在系统空闲时被调度执行,因此进程 0 通常也被称为 idle 进程。此时进程 0 仅执行 pause()系统调用,并又会调用调度函数。

1.3 Linux系统调用
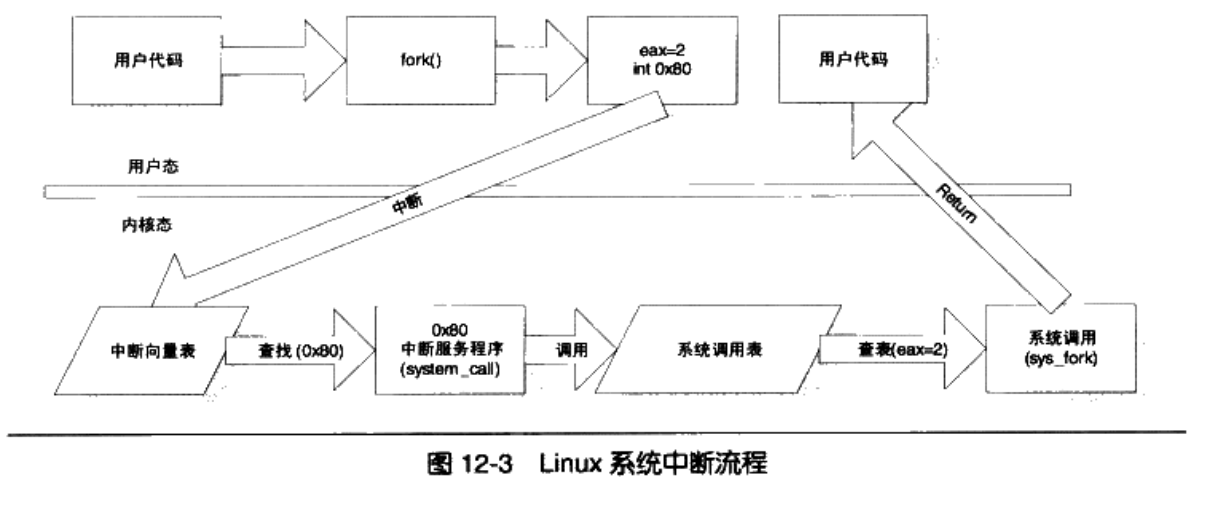
为了保护系统资源,我们 不能直接让用户程序去访问系统资源。系统调用由0x80中断完成,各个通用寄存器用于传递参数,EAX表示系统调用的接口和结果的返回值。
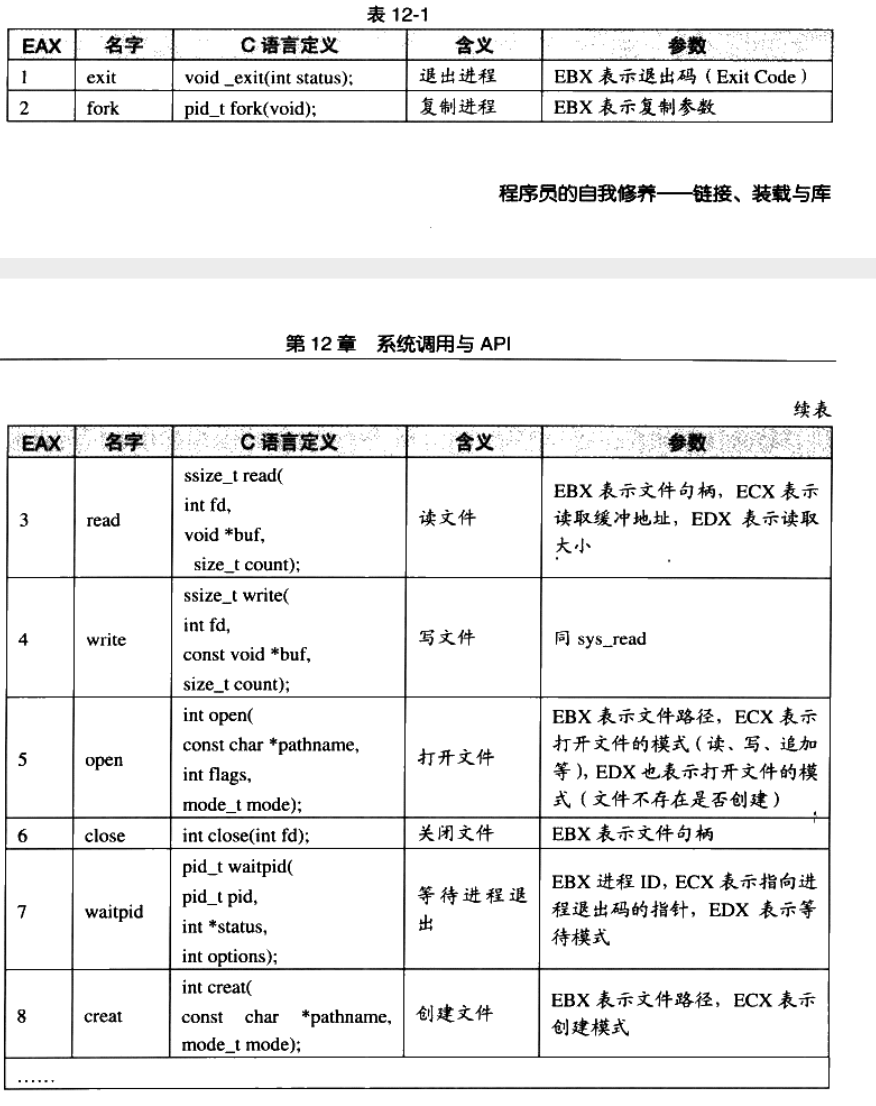
我们用中断号+系统调用号来表示一个具体的中断。一般int指令表示进入中断,0x80表示系统调用。
下面我们来看下基于int的Linux经典系统调用:
第一步是触发中断,比如
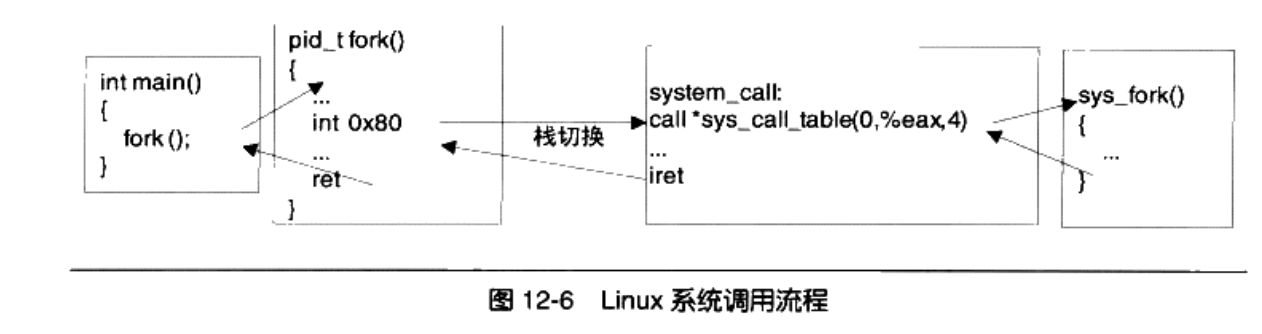
int main(){
fork();
}

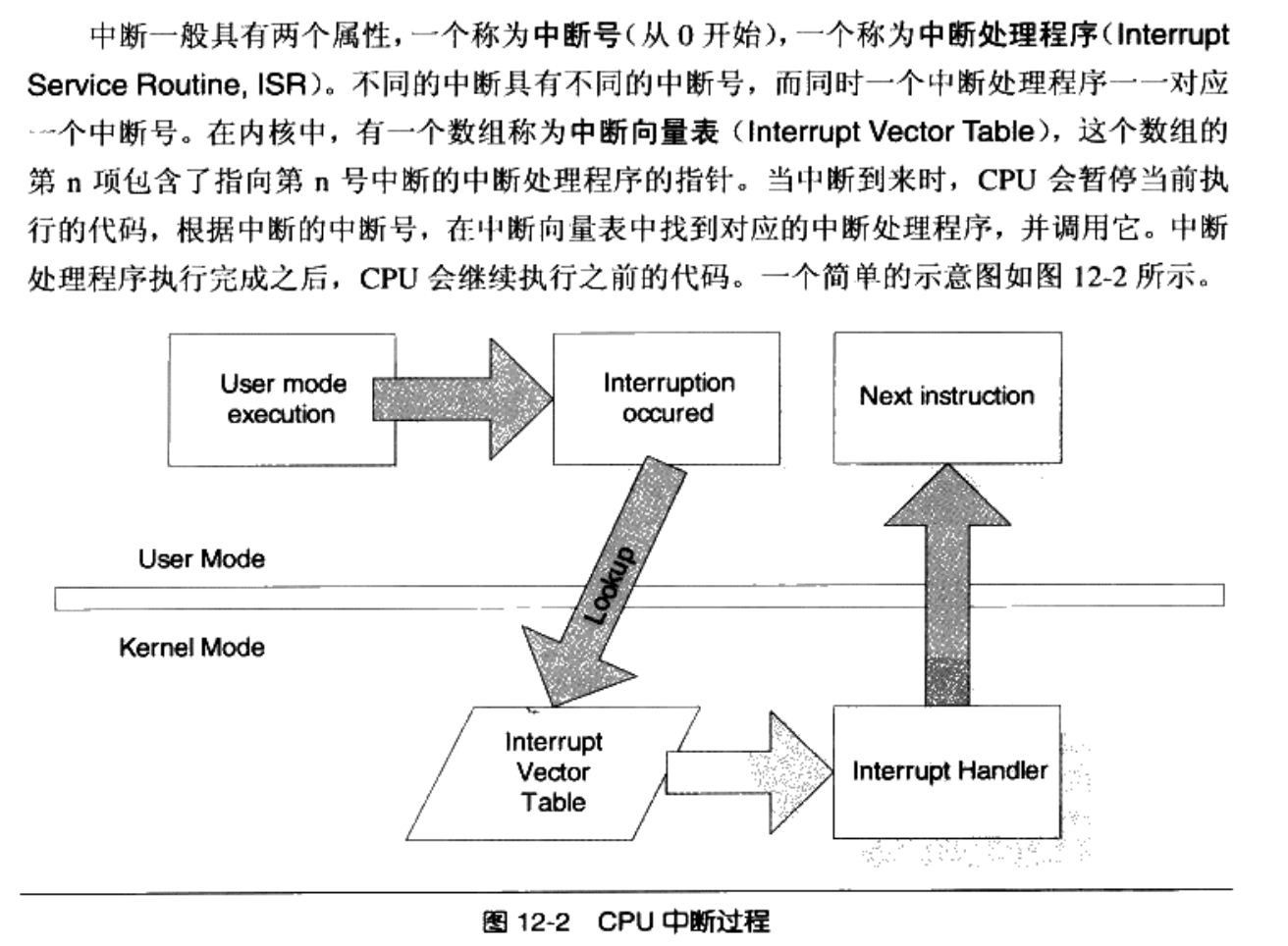
当用户调用某个系统调用的时候,实际上执行了一段汇编代码,CPU执行到int 0x80的时候,会保存现场,便于恢复,接着会将特权态切换到内核态,然后CPU会查找中断向量表中第0x80号元素。
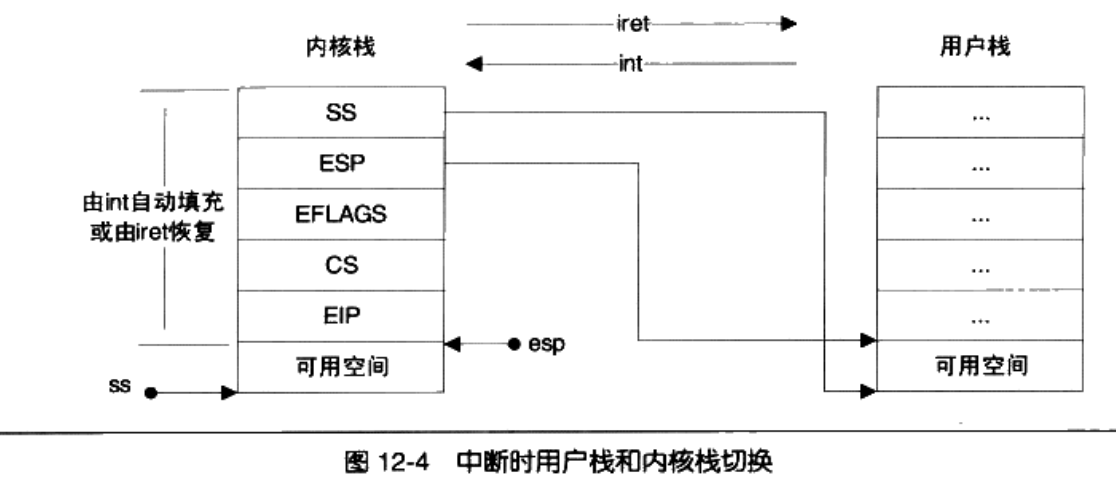
第二步是切换堆栈,体来讲,我们需要从用户态的堆栈切换到内核态的堆栈,需要如下步骤:
- 保存当前的ESP和SS的值;
- 将ESP和SS的值设置为内核栈的相应值;
- 找到当前进程的内核栈(每一个进程都有自己的内核栈)
- 在内核中依次压入用户的寄存器SS,ESP,EFLAGS,CS,EIP
- 恢复原来的ESP和SS的值(iret)
第三步是中断处理程序,
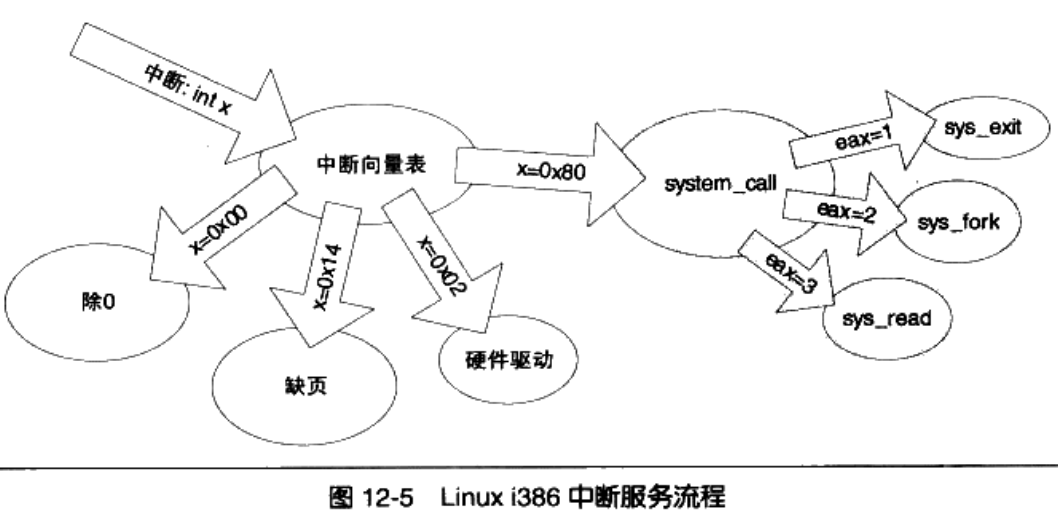
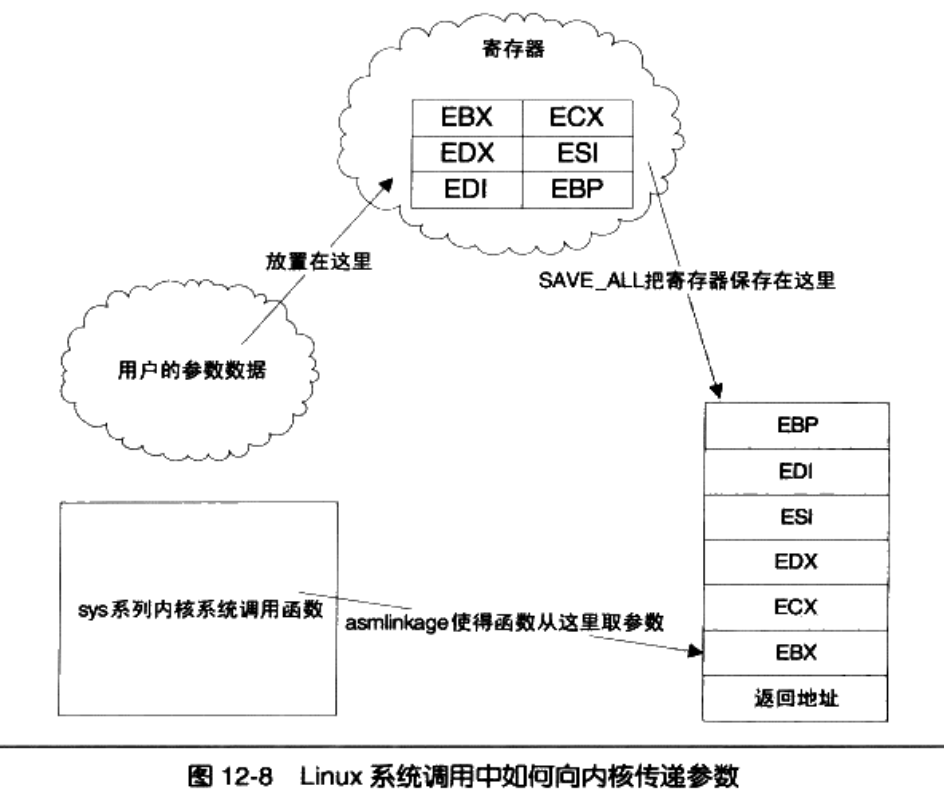
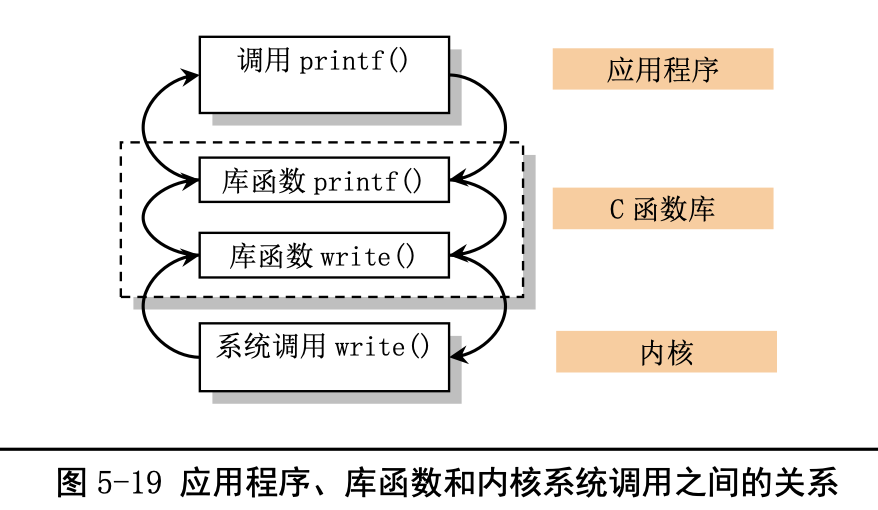
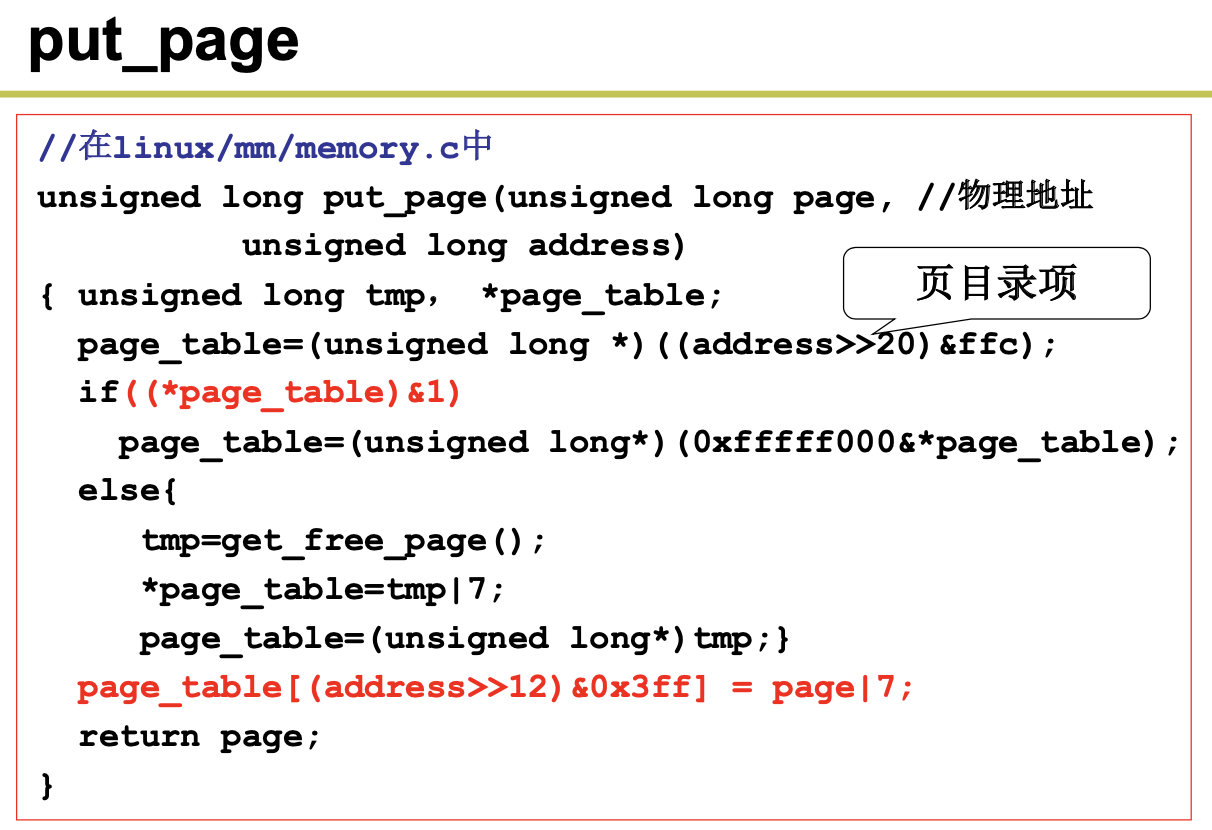
系统调用(通常称为 syscalls)是 Linux 内核与上层应用程序进行交互通信的唯一接口,参见图 5-4 所示。从对中断机制的说明可知,用户程序通过直接或间接(通过库函数)调用中断 int 0x80,并在 eax 寄存器中指定系统调用功能号,即可使用内核资源,包括系统硬件资源。不过通常应用程序都是使用具 有标准接口定义的 C 函数库中的函数间接地使用内核的系统调用,见图 5-19 所示。
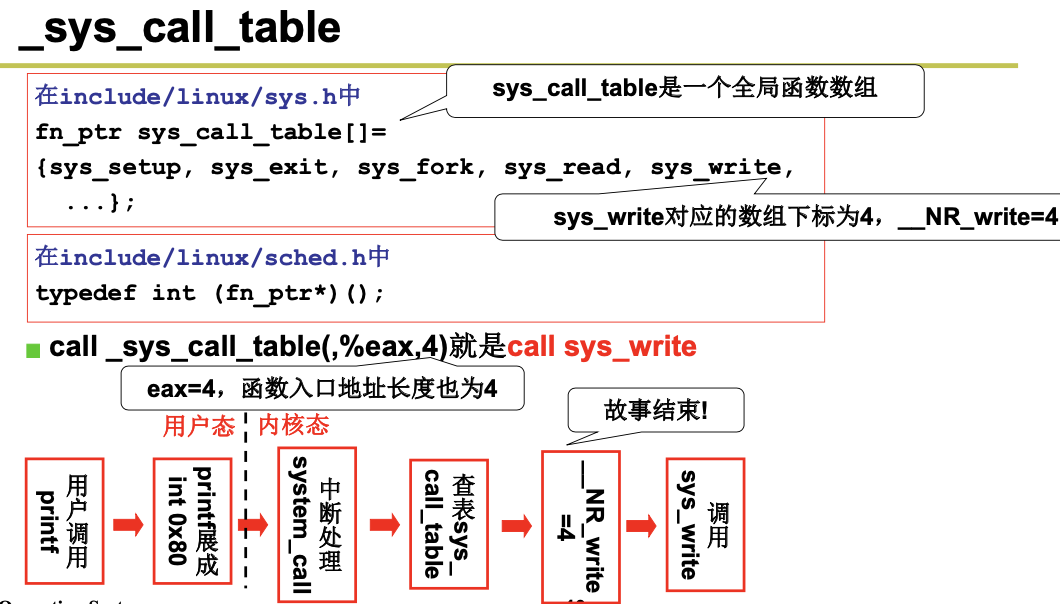
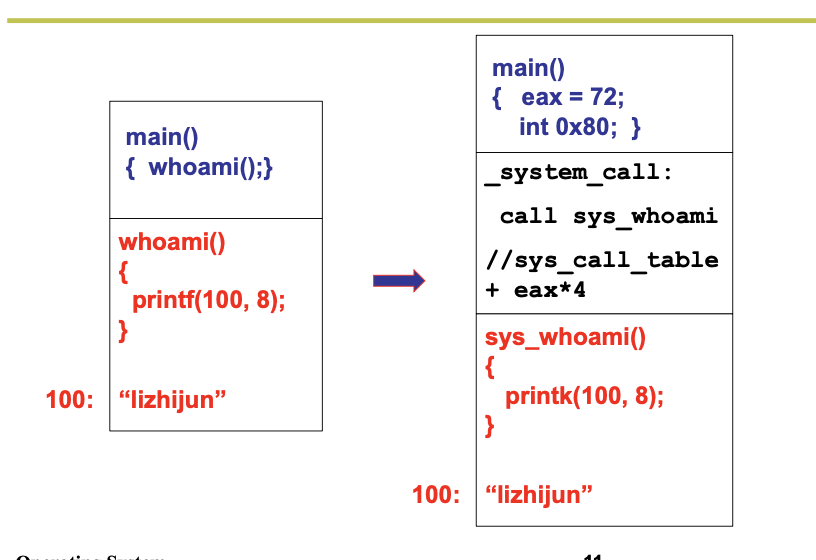
在 Linux 内核中,每个系统调用都具有唯一的一个系统调用功能号。内核 0.12 共有 87 个系统调用 功能。这些功能号定义在文件 include/unistd.h 中第 62 行开始处。例如,write 系统调用的功能号是 4,定 义为符号__NR_write。这些系统调用功能号实际上对应于 include/linux/sys.h 中定义的系统调用处理程序 指针数组表 sys_call_table[]中项的索引值。因此 write()系统调用的处理程序指针就位于该数组的项 4 处。
当我们想在自己的程序中直接使用这些系统调用符号时,需要象下面所示在包括进文件“
当应用程序经过库函数向内核发出一个中断调用int 0x80时,就开始执行一个系统调用。其中寄存 器 eax 中存放着系统调用号,而携带的参数可依次存放在寄存器 ebx、ecx 和 edx 中。因此 Linux 0.12 内 核中用户程序能够向内核最多直接传递三个参数,当然也可以不带参数。处理系统调用中断int 0x80的 过程是程序 kernel/system_call.s 中的 system_call。



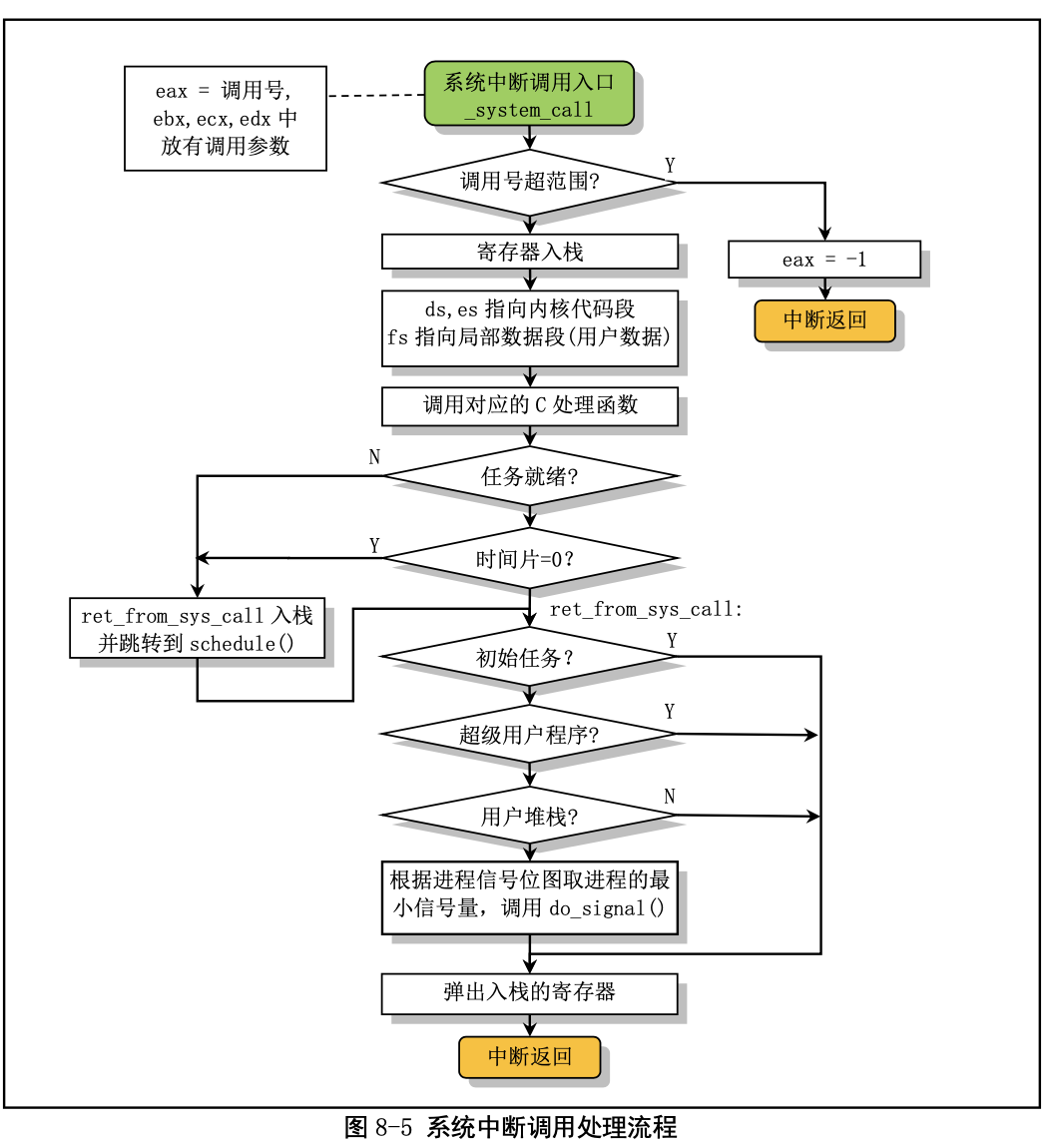
操作系统实现系统调用的基本过程是:
- 应用程序调用库函数(API);
- API将系统调用号存入EAX,然后通过中断调用使系统进入内核态;
- 内核中的中断处理函数根据系统调用号,调用对应的内核函数(系统调用);
- 系统调用完成相应功能,将返回值存入EAX,返回到中断处理函数;
- 中断处理函数返回到API中;
- API将EAX返回给应用程序。
实现一个系统调用的步骤如下:
首先,修改 include/linux/sys.h 在sys_call_table数组最后加入sys_foo,并仿照上面给出其他系统调用格式加上 extern rettype sys_foo();
其次,修改include/unistd.h
#define __NR_foo num
num为接下来使用的系统调用号
然后修改 kernel/system_call.s nr_system_calls = num,num为在原值加1 即系统调用总数目加1
接着在kernel中添加 foo.c 若需要支持内核态与用户态数据交互,则包含include/asm/segment.h,其中有put_fs_XXX get_fs_XXX函数,在foo.c实现系统调用sys_foo()
最后修改kernel的Makefile,将foo.c与内核其它代码编译链接到一起
系统调用用户界面要
#define LIBRARY
#include
_syscallN宏展开系统调用,提供用户态的系统调用接口(参数数目确定具体宏)
2. 进程与线程
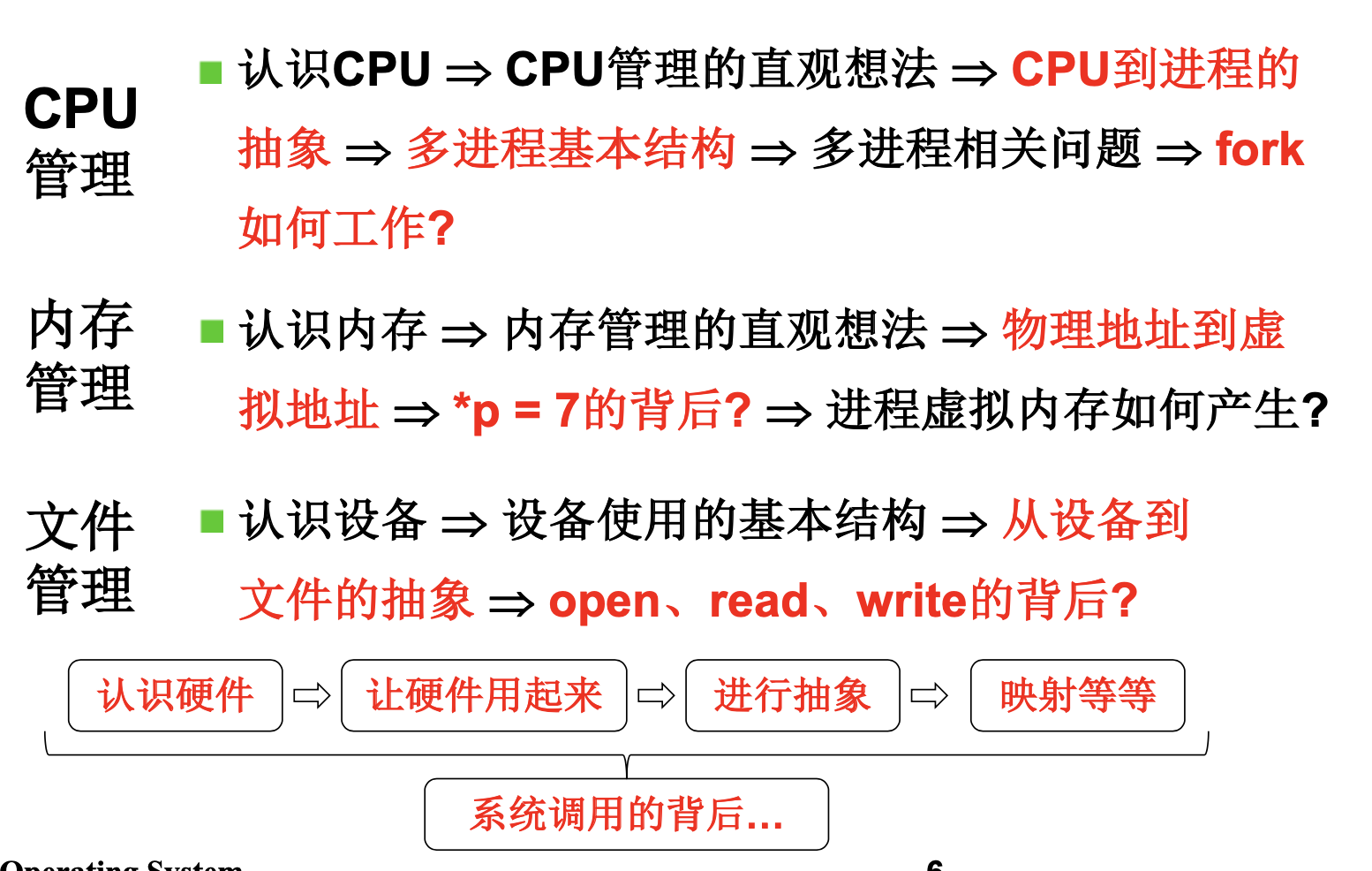
我们来区分下进程,线程和协程。进程和线程不在多说了,我们来看下协程。来看生产者消费者的场景,一个线程向队列中放数据,另外一个从队列中取数据,处理起两个线程的协作就显得很麻烦,不但需要加锁,还得做好线程的通知和等待。我们来看下这样的代码:
# 生产者
def producer(c):
#其他代码
while True:
value = ...生成数据...
c.send(value)
# 消费者
def consumer():
#其他代码
while True:
value = yield
print(value)
c = consumer()
producer(c)
- 生产者发送数据,暂停运行,不进行下一轮循环
- 消费者其实一直在value = yield 那里等待,直到数据到来,现在数据来了,取出处理(value就是生产者发送过来的数据)。
- 消费者在循环中再次yield, 暂停执行。
- 生产者继续下一轮的循环,生成新的消息,发送给消费者。
注意,这个yield和Java的yield是不同的,前者是真的让程序暂停了。后者只是让出CPU进入了就绪状态。等待下次调度运行。干了操作系统的事情。这样的程序叫做协程,完全在用户态,比线程更加轻量级。协程是依赖于线程的。
我们来研究下一个话题?为什么需要线程池?
既然线程是属于进程的,可以共享进程的资源, 那创建一个线程应该很轻松啊,为什么要有线程池这个东西呢?
虽然线程是个轻量级的东西, 但是对于互联网应用来说,如果每个用户的请求都创建一个线程,那会非常得多,服务器也是难于承受, 再说了,众多的线程去竞争CPU,不断切换,也会让CPU调度不堪重负,很多线程将不得不等待。所以前辈们的思路就是(1)用少量的线程 (2) 让线程保持忙碌。
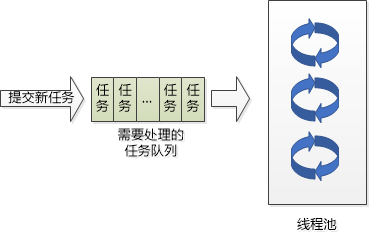
只创建一定数量的线程,让这些线程去处理所有的任务,任务执行完了以后,线程并不结束,而是回到线程池中去,等待接受下一个任务。
我们设置可以预先创建线程,任务来了就不用临时再创建了,立刻开始服务。当线程池的线程刚创建时,让他们进入阻塞状态:等待某个任务的到来。 如果任务来了,那就好办,唤醒其中一个线程,让它拿到任务去执行即可。
我们可以借助于BlockingQueue技术:
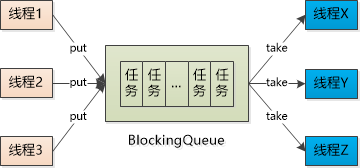
BlockingQueue其实很简单,就是一个线程调用它的take()方法取数据时, 如果这个Queue中没有数据,该线程会阻塞;同样,一个线程调用它的put方法放数据时,如果Queue满了, 也会阻塞。
线程池中每个线程的run()方法中,要设置一个循环,每次都尝试从BlockingQueue中获取任务,如果Queue是空的,就阻塞等待, 如果有任务来了,就会通知到线程池的某一个线程去处理,处理完了以后,依然试图从BlockingQueue中获取任务,就这么依次循环下去。
先简单的实现下:
线程池中的Worker线程:
public class WorkerThread extends Thread {
private BlockingQueue<Task> taskQueue = null;
private boolean isStopped = false;
//持有一个BlockingQueue的实例
public WorkerThread(BlockingQueue<Task> queue){
taskQueue = queue;
}
public void run(){
while(!isStopped()){
try{
Task task = taskQueue.take();
task.execute();
} catch(Exception e){
//log or otherwise report exception,
//but keep pool thread alive.
}
}
}
......略......
}
事实上,Doug Lea大师写了ExecutorService,如下所示:
ExecutorService executorService = Executors.newFixedThreadPool(10);
executorService.execute(new Runnable() {
public void run() {
System.out.println("Asynchronous task");
}
});
executorService.shutdown();
下面我们来看ThreadLocal,
2.1 进程运行轨迹
2.1.1 fork.c
fork()系统调用用于创建子进程。Linux 中所有进程都是进程 0(任务 0)的子进程。fork.c 程序是 sys_fork()(在 kernel/sys_call.s 中从 222 行开始)系统调用的辅助处理函数集。它给出了 sys_fork()系统 调用中使用的两个 C 语言函数:find_empty_process()和 copy_process()。还包括进程内存区域验证与内存 分配函数 verify_area()和 copy_mem()。
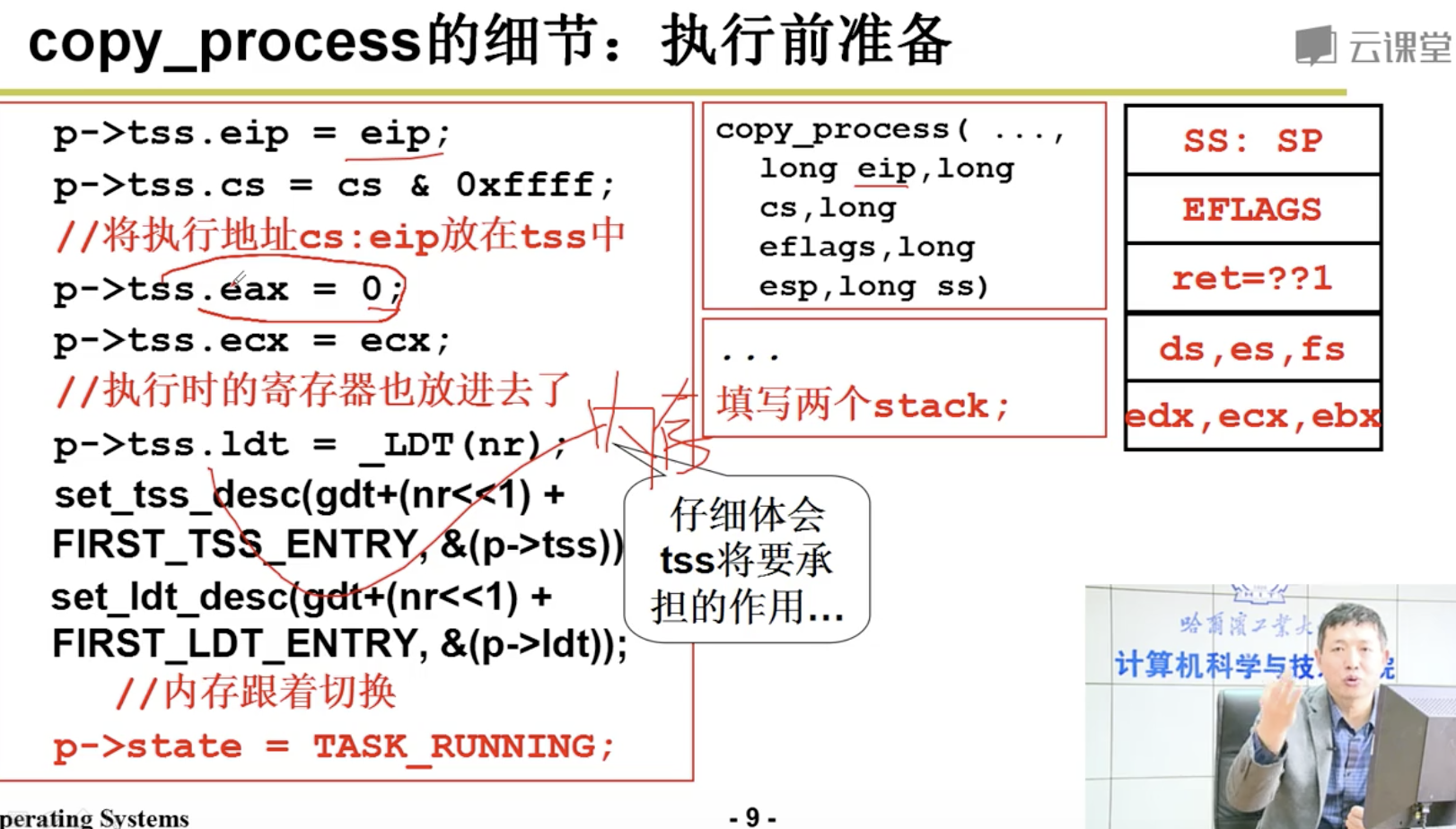
copy_process()用于创建并复制进程的代码段和数据段以及环境。在进程复制过程中,工作主要牵涉 到进程数据结构中信息的设置。系统首先为新建进程在主内存区中申请一页内存来存放其任务数据结构 信息,并复制当前进程任务数据结构中的所有内容作为新进程任务数据结构的模板。
随后程序对已复制的任务数据结构内容进行修改。首先,代码把当前进程设置为新进程的父进程, 清除信号位图并复位新进程各统计值。接着根据当前进程环境设置新进程任务状态段(TSS)中各寄存 器的值。由于创建进程时新进程返回值应为 0,所以需要设置 tss.eax = 0。新建进程内核态堆栈指针 tss.esp0 被设置成新进程任务数据结构所在内存页面的顶端,而堆栈段 tss.ss0 被设置成内核数据段选择符。tss.ldt 被设置为局部表描述符在 GDT 中的索引值。如果当前进程使用了协处理器,则还需要把协处理器的完 整状态保存到新进程的 tss.i387 结构中。
此后系统设置新任务代码段和数据段的基址和段限长,并复制当前进程内存分页管理的页目录项和 页表项。如果父进程中有文件是打开的,则子进程中相应的文件也是打开着的,因此需要将对应文件的 打开次数增 1。接着在 GDT 中设置新任务的 TSS 和 LDT 描述符项,其中基地址信息指向新进程任务结 构中的 tss 和 ldt。最后再将新任务设置成可运行状态,并向当前进程返回新进程号。
图 8-13 是内存验证函数 verify_area()中验证内存的起始位置和范围的调整示意图。因为内存写验证 函数 write_verify()需要以内存页面为单位(4096 字节)进行操作,因此在调用 write_verify()之前,需要 把验证的起始位置调整为页面起始位置,同时对验证范围作相应调整。
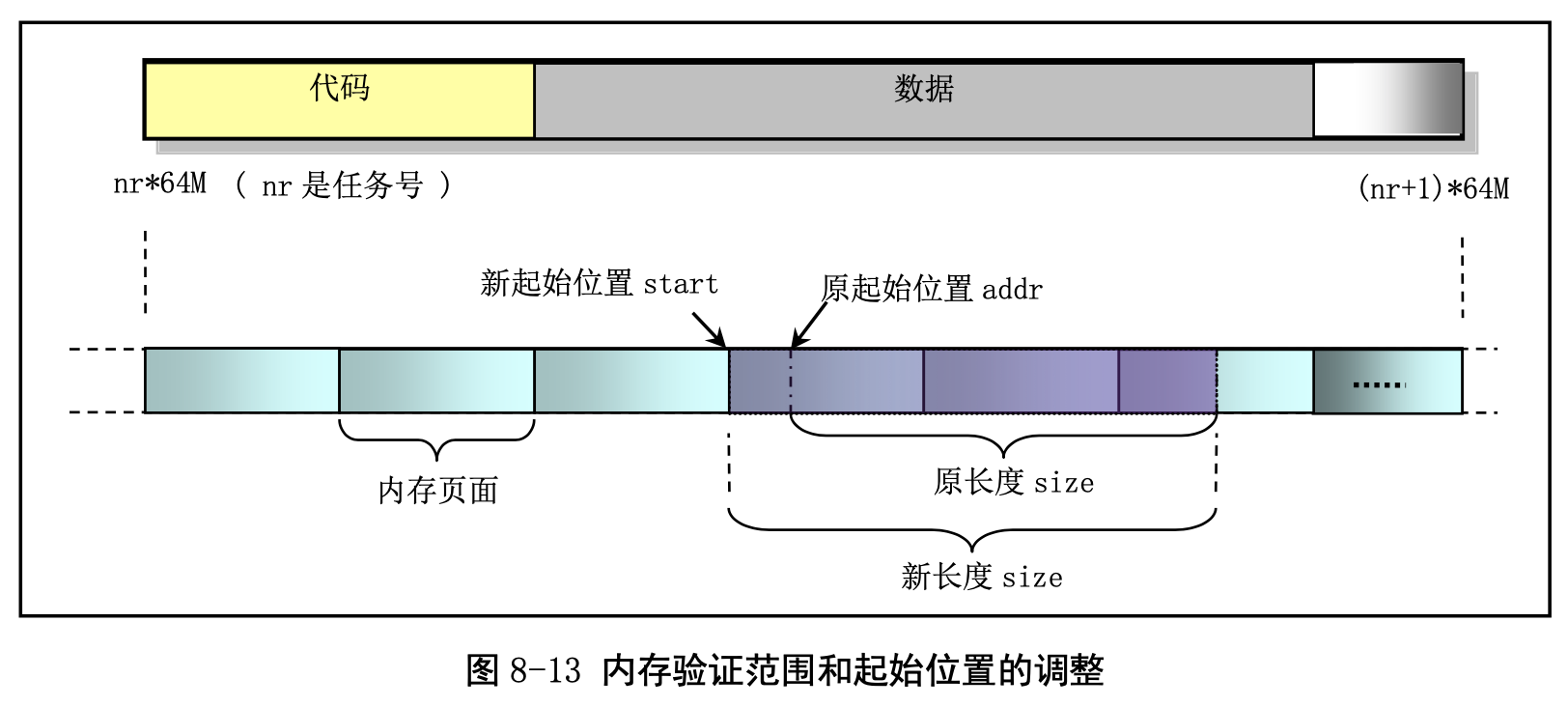
上面根据 fork.c 程序中各函数的功能简单描述了 fork()的作用。这里我们从总体上再对其稍加说明。 总的来说 fork()首先会为新进程申请一页内存页用来复制父进程的任务数据结构(也称进程控制块,PCB) 信息,然后会为新进程修改复制的任务数据结构的某些字段值,包括利用系统调用中断发生时逐步压入 堆栈的寄存器信息(即 copy_process()的参数)重新设置任务结构中的 TSS 结构的各字段值,让新进程的状态保持父进程即将进入中断过程前的状态。然后为新进程确定在线性地址空间中的起始位置(nr * 64MB)。对于 CPU 的分段机制,Linux 0.12 的代码段和数据段在线性地址空间中的位置和长度完全相同。 接着系统会为新进程复制父进程的页目录项和页表项。对于Linux 0.12内核来说,所有程序共用一个位 于物理内存开始位置处的页目录表,而新进程的页表则需另行申请一页内存来存放。
在 fork()的执行过程中,内核并不会立刻为新进程分配代码和数据内存页。新进程将与父进程共同 使用父进程已有的代码和数据内存页面。只有当以后执行过程中如果其中有一个进程以写方式访问内存 时被访问的内存页面才会在写操作前被复制到新申请的内存页面中。

2.1.2 sched.c
sched.c 文件是内核中有关任务(进程)调度管理的程序。其中包括几个有关调度的基本函数 (sleep_on()、wakeup()、schedule()等),以及一些简单的系统调用函数(如 getpid())。系统时钟中断服务 过程中调用的定时函数 do_timer()也被放置在本程序中。另外,为了便于软盘驱动器定时处理编程,Linus 先生也将有关软盘定时操作的几个函数放到了这里。
调度函数 schedule()负责选择系统中下一个要运行的任务(进程)。它首先对所有任务进行检测,唤 醒任何一个已经得到信号的任务。具体方法是针对任务数组中的每个任务,检查其报警定时值 alarm。 如果任务的 alarm 时间已经过期(alarm<jiffies),则在它的信号位图中设置 SIGALRM 信号,然后清 alarm 值。jiffies 是系统从开机计算起的滴答数(10ms/滴答,在 sched.h 中定义)。如果进程的信号位图中除 去被阻塞的信号外还有其他信号,并且任务处于可中断睡眠状态(TASK_INTERRUPTIBLE),则置任 务为就绪状态(TASK_RUNNING)。
随后是调度函数的核心处理部分。这部分代码根据进程的时间片和优先权调度机制,来选择随后要 执行的任务。它首先循环检查任务数组中的所有任务,根据每个就绪态任务剩余执行时间的值 counter, 选取该值最大的一个任务,并利用 switch_to()函数切换到该任务。
若所有就绪态任务的 counter 值都等于零,表示此刻所有任务的时间片都已经运行完,于是就根据任 务的优先权值 priority,重置每个任务的运行时间片值 counter,再重新循环检查所有任务的执行时间片值。
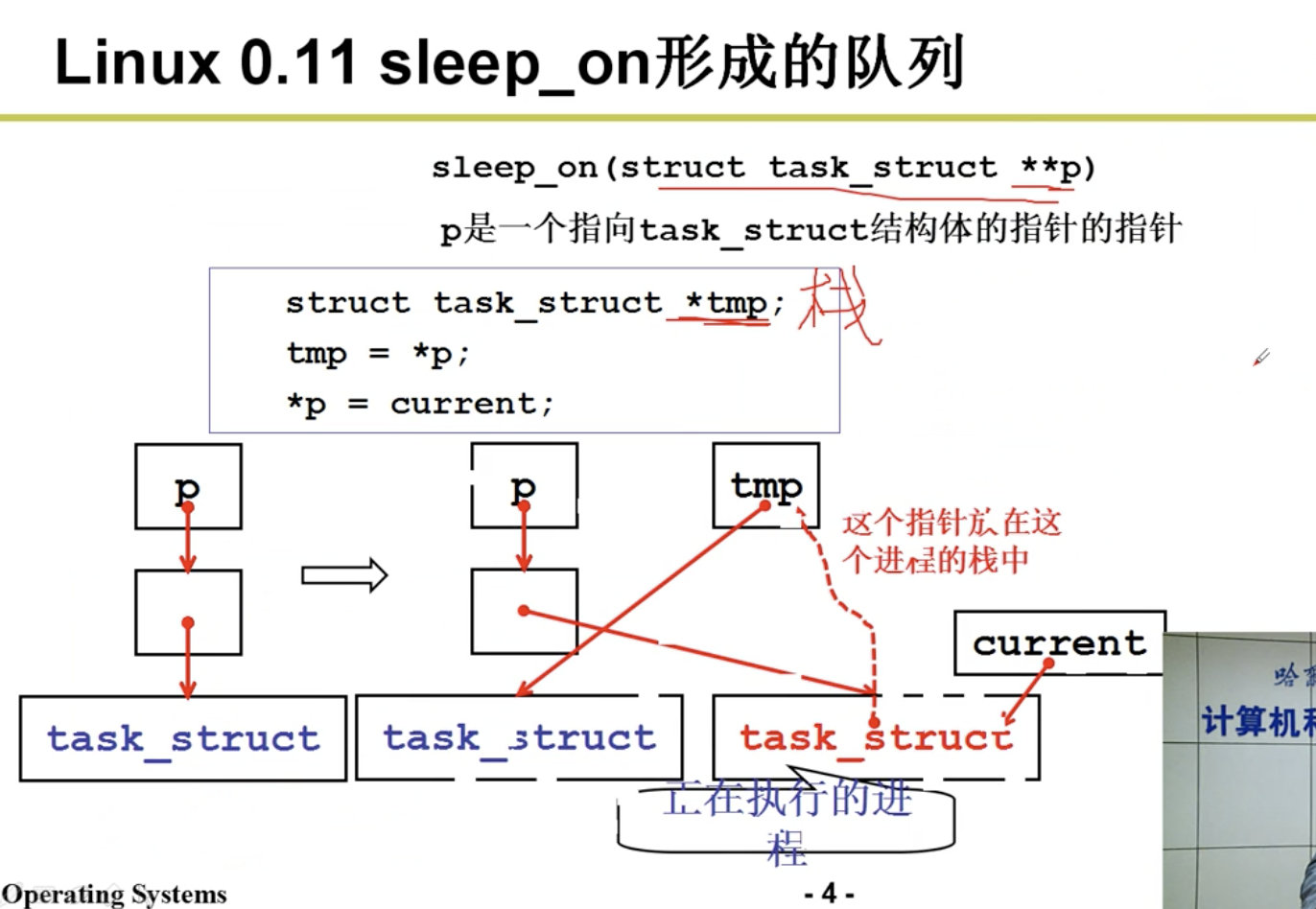
自动进入睡眠函数 sleep_on()和唤醒函数 wake_up()。这两个函数虽然很短, 却要比 schedule()函数难理解。在看代码之前我们先用图示的方式作一些解释。简单地说,sleep_on()函 数的主要功能是当一个进程(或任务)所请求的资源正被占用或不在内存中时暂时先把该进程切换出去, 放在等待队列中等待一段时间。当切换回来后再继续运行。放入等待队列的方式利用了函数中的 tmp 指 针作为各个正在等待任务的联系。
函数中共牵涉到对三个任务指针的操作:p、tmp 和 current。p 是等待队列头指针,如文件系统内 存 i 节点的 i_wait 指针、内存缓冲操作中的 buffer_wait 指针等;tmp 是在函数堆栈上建立的临时指针, 存储在当前任务内核态堆栈上;current 是当前任务指针。对于这些指针在内存中的变化情况我们可以用 图 8-6 的示意图说明。图中的长条表示内存字节序列。
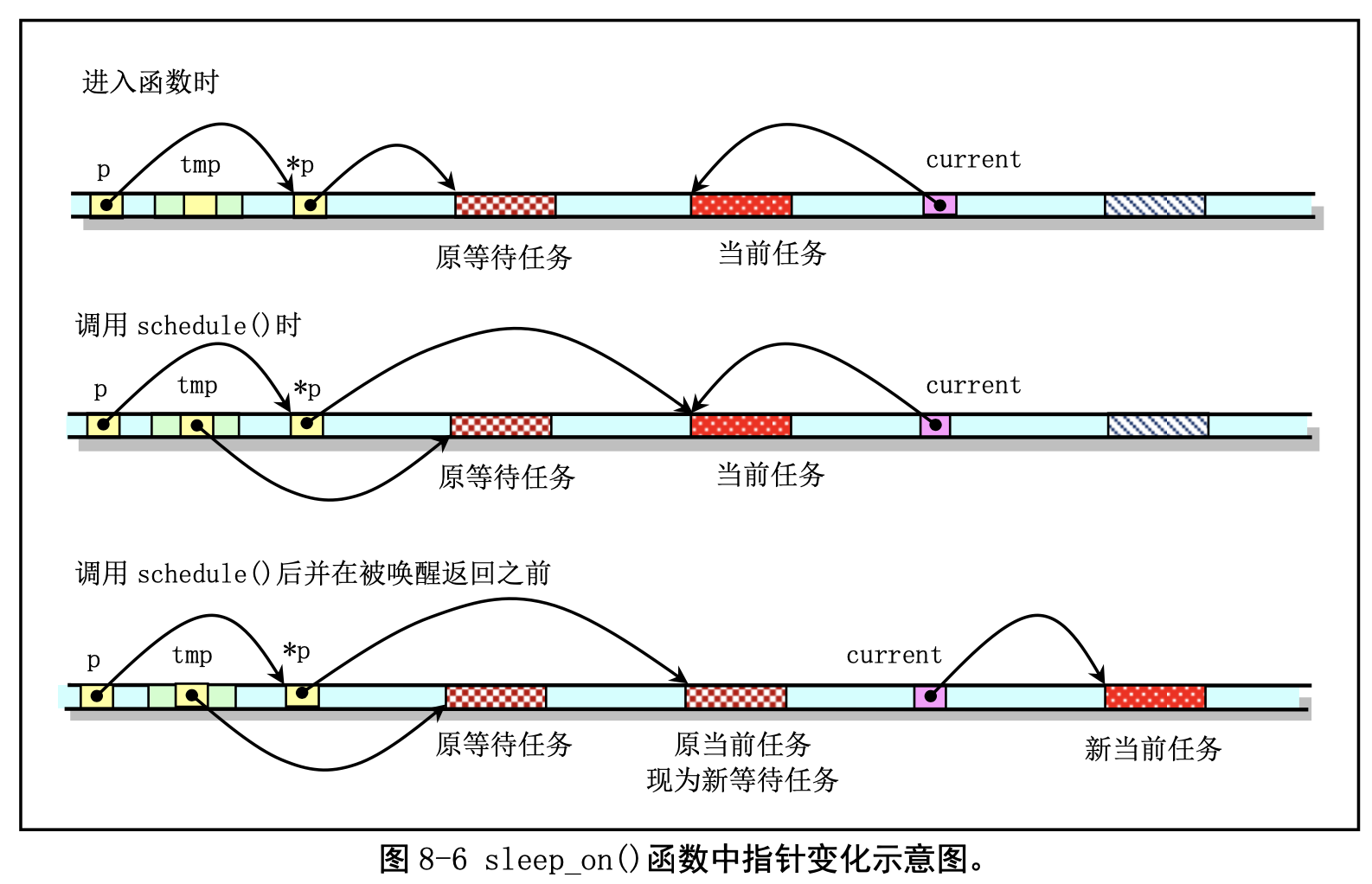
当刚进入该函数时,队列头指针p 指向已经在等待队列中等待的任务结构(进程描述符)。当然, 在系统刚开始执行时,等待队列上无等待任务。因此上图中原等待任务在刚开始时不存在,此时p 指向 NULL。通过指针操作,在调用调度程序之前,队列头指针指向了当前任务结构,而函数中的临时指针 tmp 指向了原等待任务。在执行调度程序并在本任务被唤醒重新返回执行之前,当前任务指针被指向新 的当前任务,并且 CPU 切换到该新的任务中执行。这样本次 sleep_on()函数的执行使得 tmp 指针指向队 列中队列头指针指向的原等待任务,而队列头指针则指向此次新加入的等待任务,即调用本函数的任务。
从而通过堆栈上该临时指针 tmp 的链接作用,在几个进程为等待同一资源而多次调用该函数时,内核程 序就隐式地构筑出一个等待队列,参见图 8-7 中的等待队列示意图。图中示出了当向队列头部插入第三 个任务时的情况。从图中我们可以更容易理解 sleep_on()函数的等待队列形成过程。
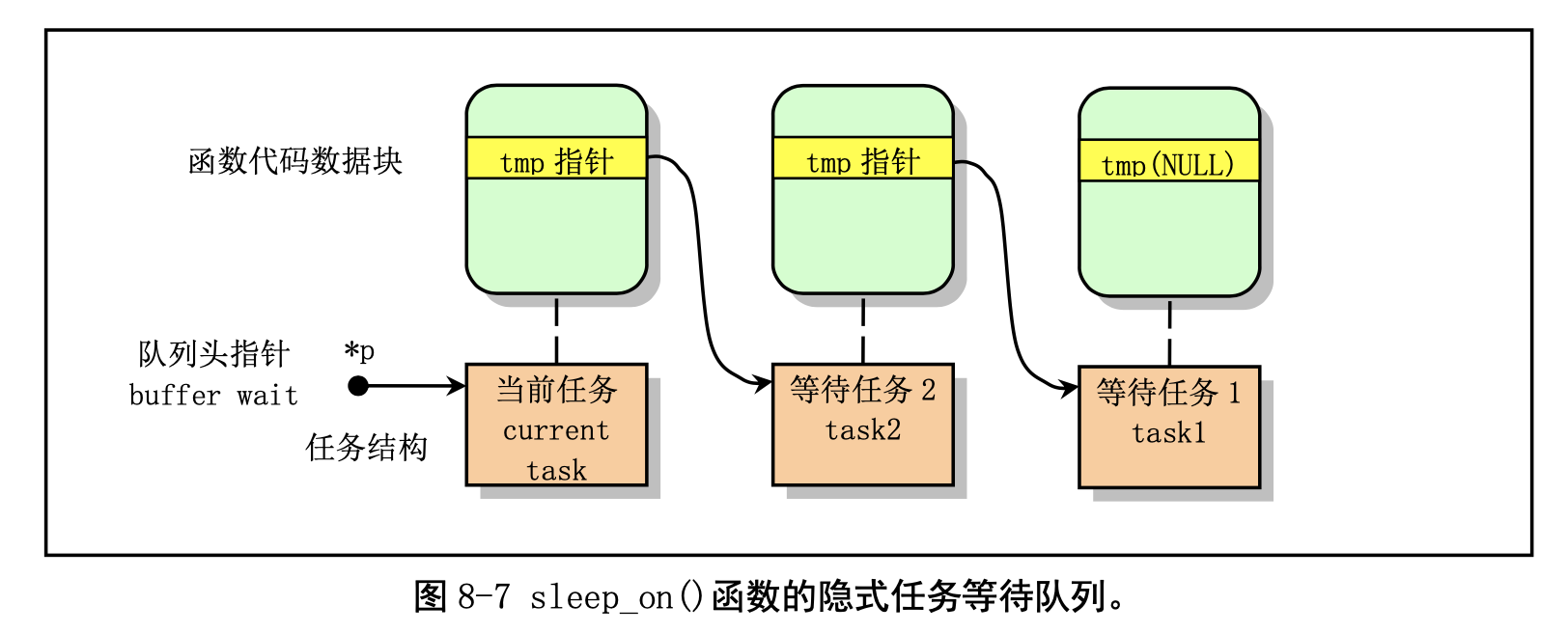
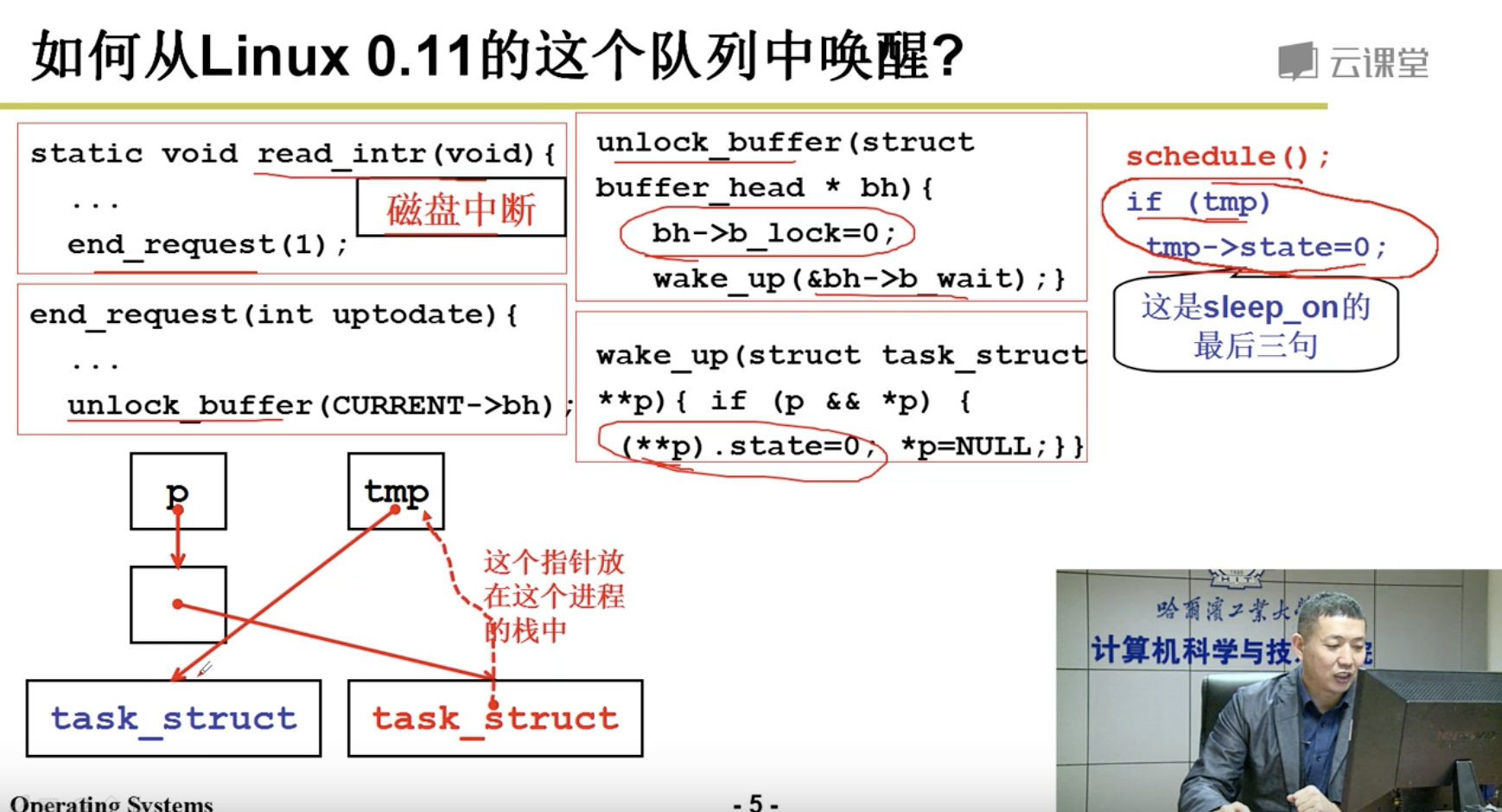
在把进程插入等待队列后,sleep_on()函数就会调用 schedule()函数去执行别的进程。当进程被唤醒 而重新执行时就会执行后续的语句,把比它早进入等待队列的一个进程唤醒。注意,这里所谓的唤醒并 不是指进程处于执行状态,而是处于可以被调度执行的就绪状态。
唤醒函数 wake_up()用于把正在等待可用资源的指定任务置为就绪状态。该函数是一个通用唤醒函 数。在有些情况下,例如读取磁盘上的数据块,由于等待队列中的任何一个任务都可能被先唤醒,因此 还需要把被唤醒任务结构的指针置空。这样,在其后进入睡眠的进程被唤醒而又重新执行 sleep_on()时, 就无需唤醒该进程了。
还有一个函数 interruptible_sleep_on(),它的结构与 sleep_on()的基本类似,只是在进行调度之前是把 当前任务置成了可中断等待状态,并在本任务被唤醒后还需要判断队列上是否有后来的等待任务。若有, 则调度它们先运行。在内核 0.12 开始,这两个函数被合二为一,仅用任务的状态作为参数来区分这两种 情况。
在阅读本文件的代码时,最好同时参考包含文件 include/linux/sched.h 文件中的注释,以便更全面地 了解内核的调度机理。
2.1.3 exit.c
exit.c 程序主要实现进程终止和退出的相关处理事宜。其中包括进程释放、会话(进程组)终止和程序退出处理函数,以及杀死进程、终止进程、挂起进程等系统调用函数,还包括进程信号发送函数 send_sig() 和通知父进程子进程终止的函数 tell_father()。
释放进程函数 release()根据指定的任务数据结构(任务描述符)指针,在任务数组中删除指定的任 务指针、释放相关内存页,并立刻让内核重新调度任务运行。
进程组终止函数 kill_session()用于向会话号与当前进程号相同的进程发送挂断进程的信号。
系统调用 sys_kill()用于向进程发送任何指定的信号。根据进程号参数 pid 不同数值,该系统调用会 向不同的进程或进程组发送信号。程序注释中列出了在各种不同情况下的处理方式。
程序退出处理函数do_exit()会在exit系统调用的中断处理程序中被调用。它首先会释放当前进程 的代码段和数据段所占用的内存页面。如果当前进程有子进程,就将子进程的 father 字段置为 1,即把 子进程的父进程改为进程 1(init 进程)。如果该子进程已经处于僵死状态,则向进程 1 发送子进程终止 信号 SIGCHLD。接着关闭当前进程打开的所有文件、释放使用的终端设备、协处理器设备。若当前进程 是进程组的首进程,则还需要终止所有相关进程。随后把当前进程置为僵死状态,设置退出码,并向其 父进程发送子进程终止信号 SIGCHLD。最后让内核重新调度任务运行。
系统调用 waitpid()用于挂起当前进程,直到 pid 指定的子进程退出(终止)或者收到要求终止该进 程的信号,或者是需要调用一个信号句柄(信号处理程序)。如果 pid 所指的子进程早已退出(已成所谓 的僵死进程),则本调用将立刻返回。子进程使用的所有资源将释放。该函数的具体操作也要根据其参数 进行不同的处理。详见代码中的相关注释。
2.2 基于内核栈切换的进程切换
OS-level threads vs Green Threads
For clarity, I usually say “OS-level threads” or “native threads” instead of “Kernel-level threads” (which I confused with “kernel threads” in my original answer below.) OS-level threads are created and managed by the OS. Most languages have support for them. (C, recent Java, etc) They are extremely hard to use because you are 100% responsible for preventing problems. In some languages, even the native data structures (such as Hashes or Dictionaries) will break without extra locking code.
The opposite of an OS-thread is a green thread that is managed by your language. These threads are given various names depending on the language (coroutines in C, goroutines in Go, fibers in Ruby, etc). These threads only exist inside your language and not in your OS. Because the language chooses context switches (i.e. at the end of a statement), it prevents TONS of subtle race conditions (such as seeing a partially-copied structure, or needing to lock most data structures). The programmer sees “blocking” calls (i.e. data = file.read() ), but the language translates it into async calls to the OS. The language then allows other green threads to run while waiting for the result.
Green threads are much simpler for the programmer, but their performance varies: If you have a LOT of threads, green threads can be better for both CPU and RAM. On the other hand, most green thread languages can’t take advantage of multiple cores. (You can’t even buy a single-core computer or phone anymore!). And a bad library can halt the entire language by doing a blocking OS call.
The best of both worlds is to have one OS thread per CPU, and many green threads that are magically moved around onto OS threads. Languages like Go and Erlang can do this.
system calls and other uses not available to user-level threads
This is only half true. Yes, you can easily cause problems if you call the OS yourself (i.e. do something that’s blocking.) But the language usually has replacements, so you don’t even notice. These replacements do call the kernel, just slightly differently than you think.
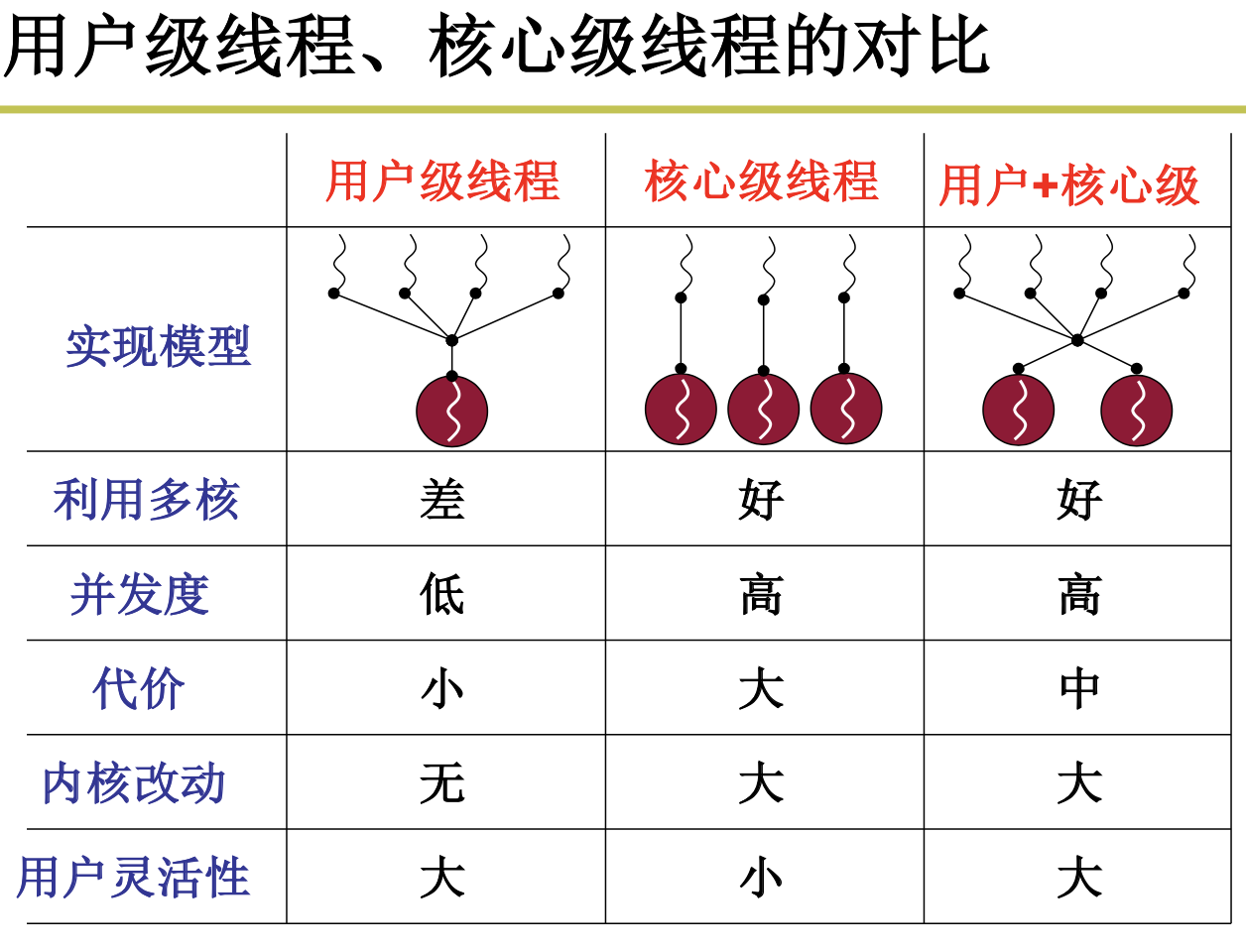
我们本来是需要去学习进程的切换,但是进程的切换包括指令和资源的切换,我们把资源的切换放到内存里面去学习,先来学习指令的切换,也即线程的切换,线程的切换分为用户级线程和内核级线程。
2.2.1 用户级线程
正如我们前面所学习到的那样,进程是十分占用资源的,进程 = 资源 + 指令执行序列。那么我们很容易想到,为了优化性能,我们可不可以:将资源和指令执行分开 ,一个资源 + 多个指令执行序列。
所以我们提出了线程的概念:
线程的实质是映射表不变而PC指针变。
下面我们尝试实现这一一个浏览器:
-
一个线程用来从服务器接收数据
-
一个线程用来显示文本
- 一个线程用来处理图片(如解压缩)
- 一个线程用来显示图片
我们开始实现这个浏览器:

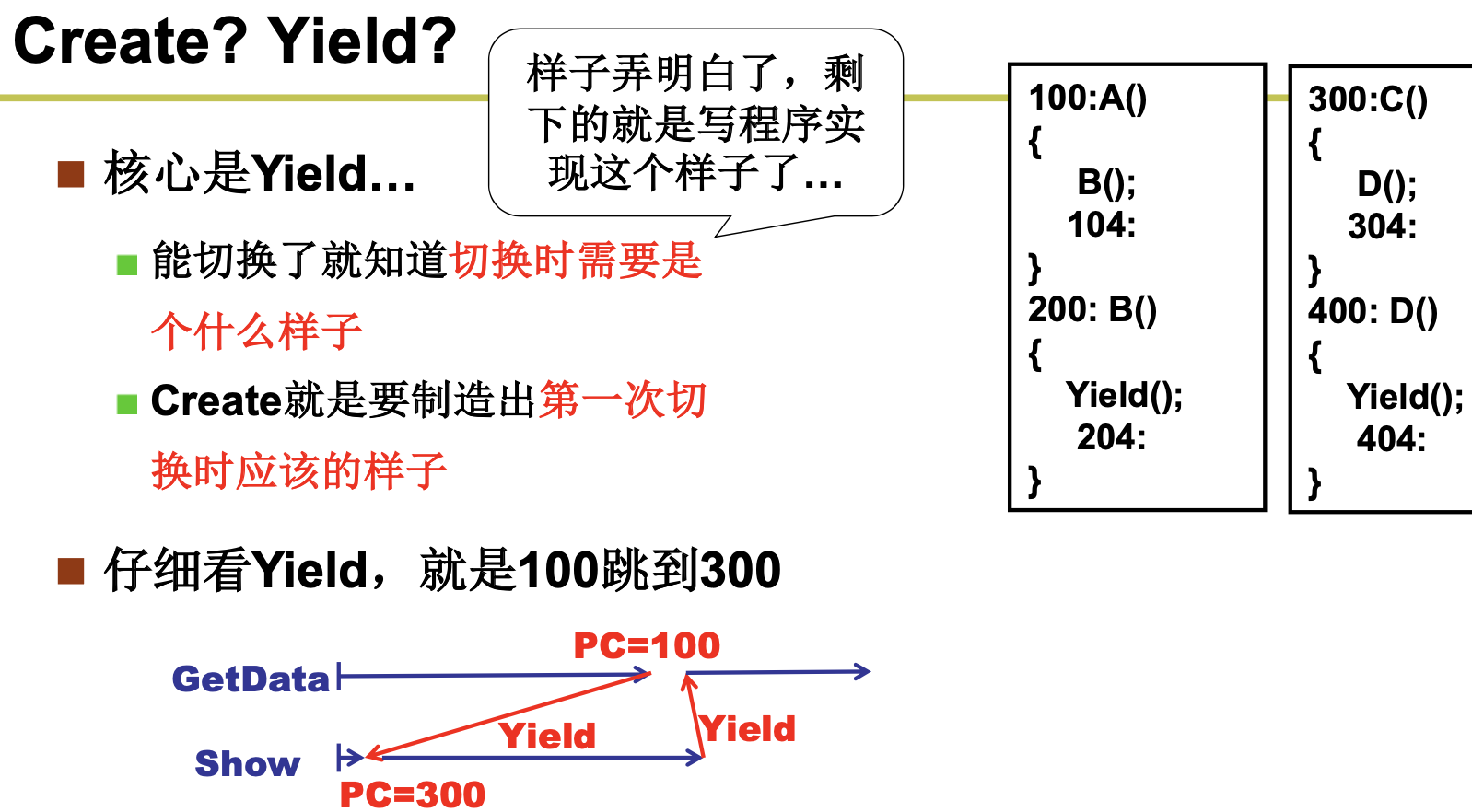
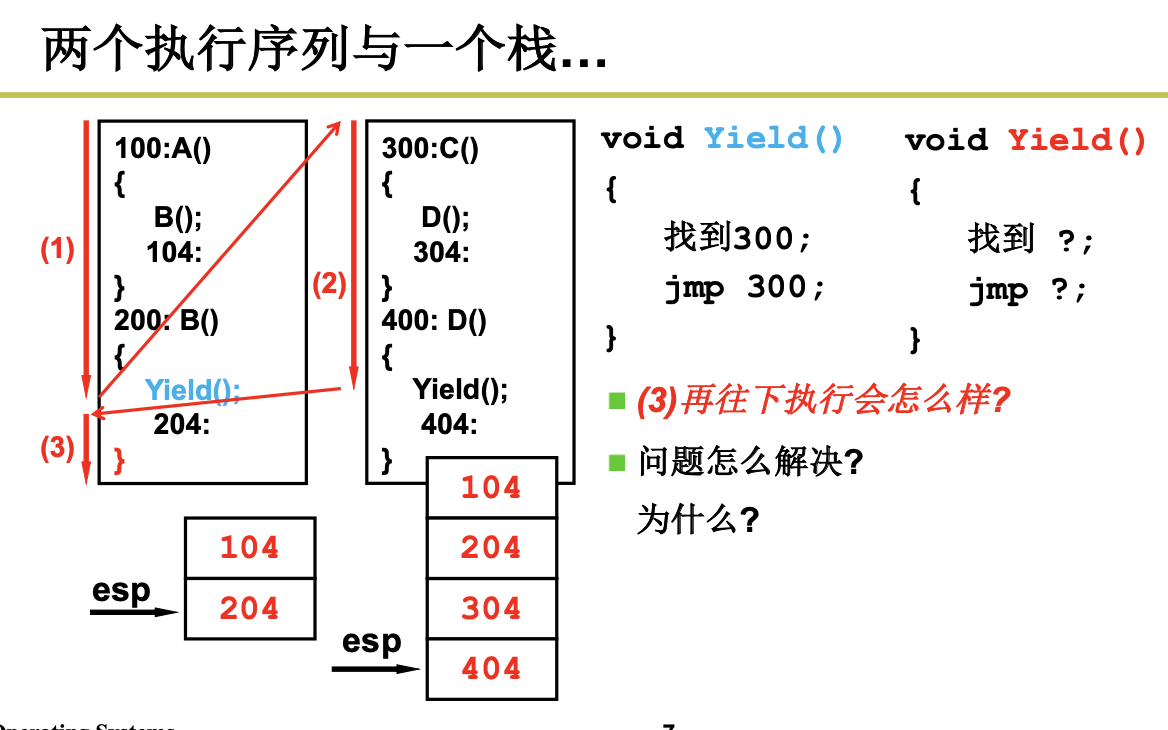
发现没有,如果2个线程只有1个栈,就会出现问题,当第二个Yield被执行的时候,应该204出栈,但是这个时候确是404出栈,这个时候出现了问题。


2.2.2 内核级线程的样子
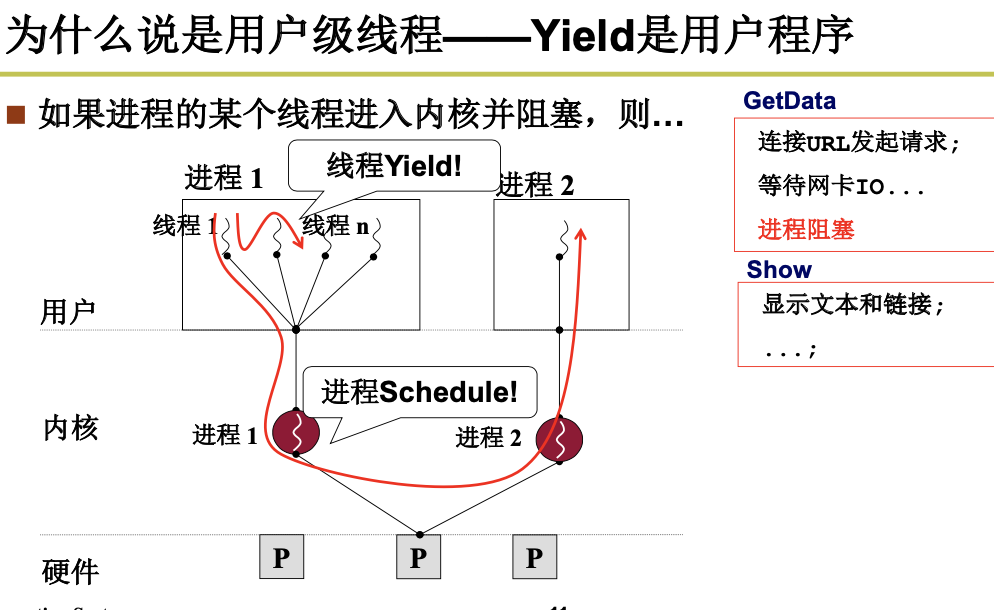

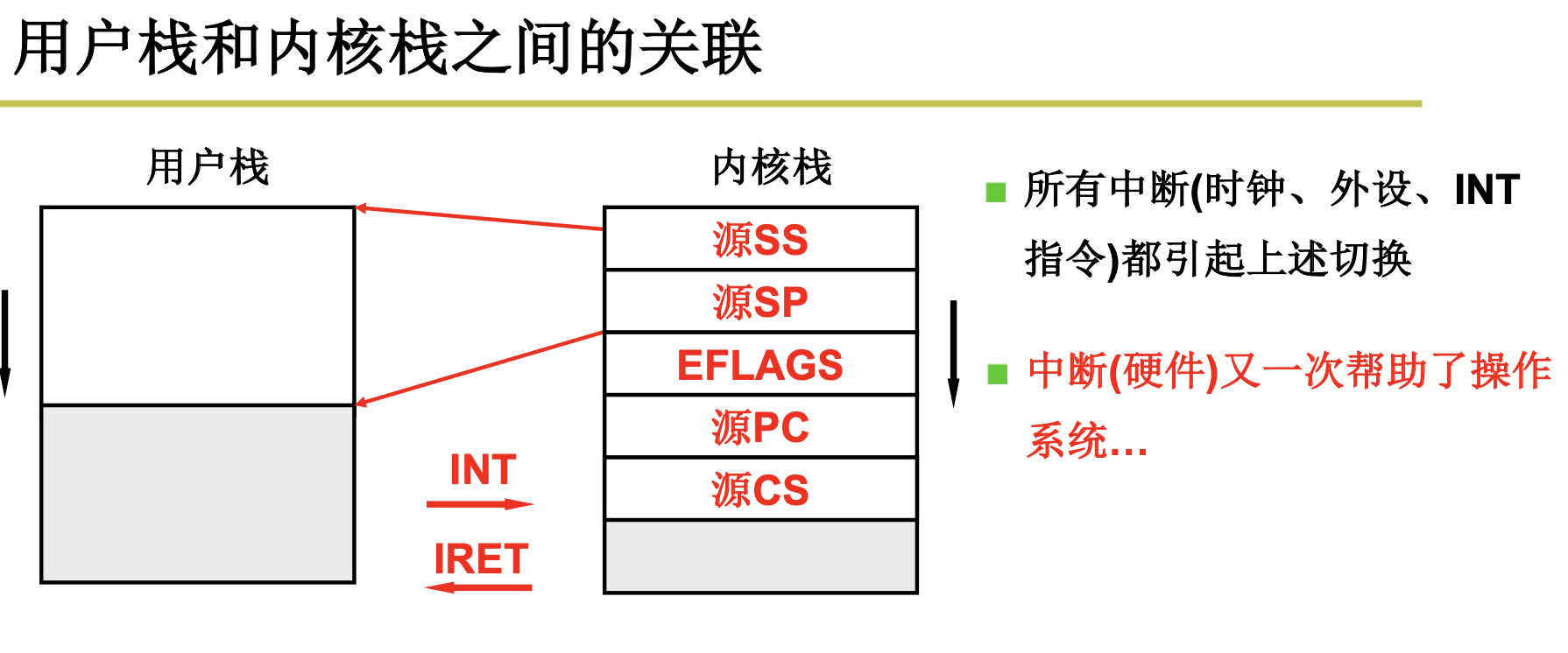
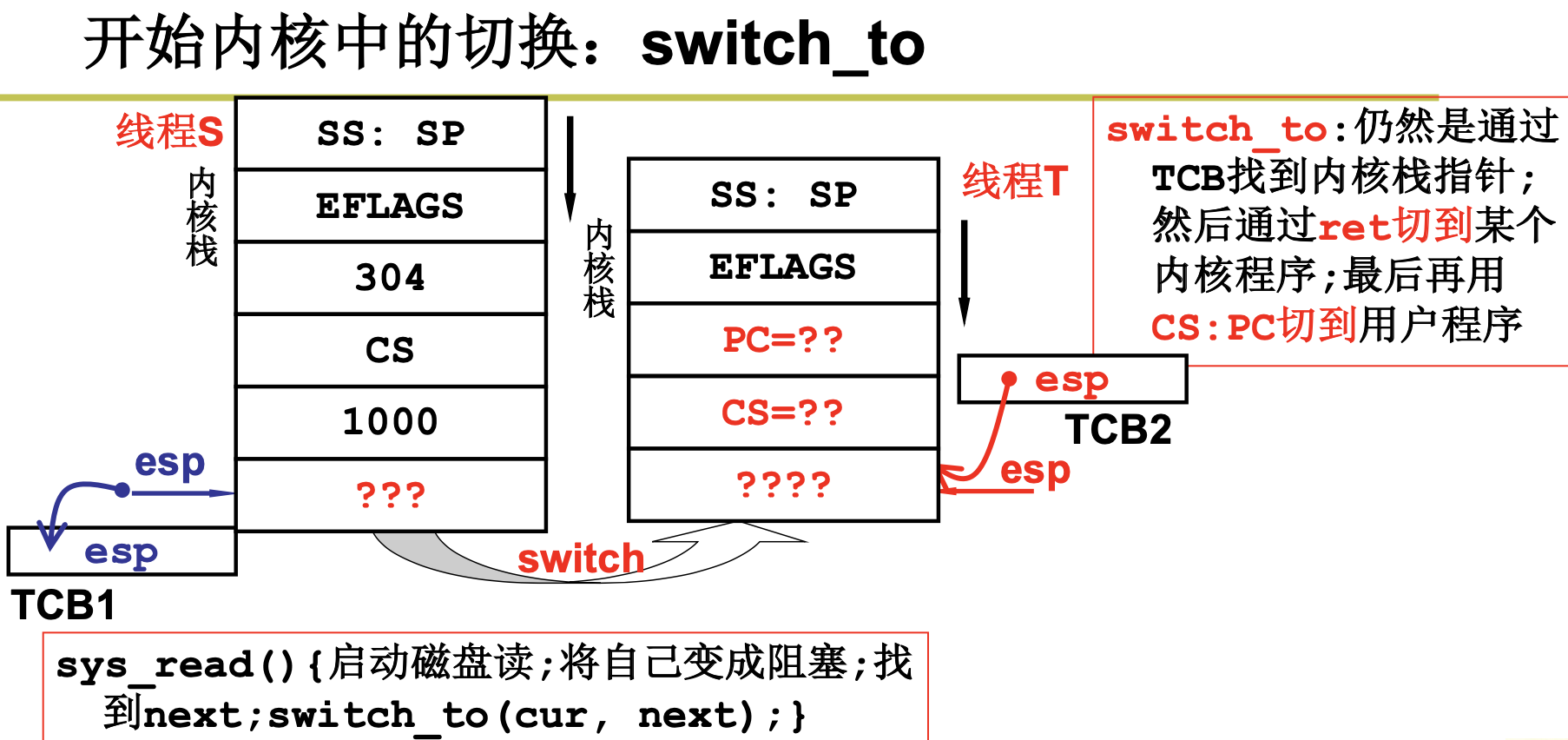

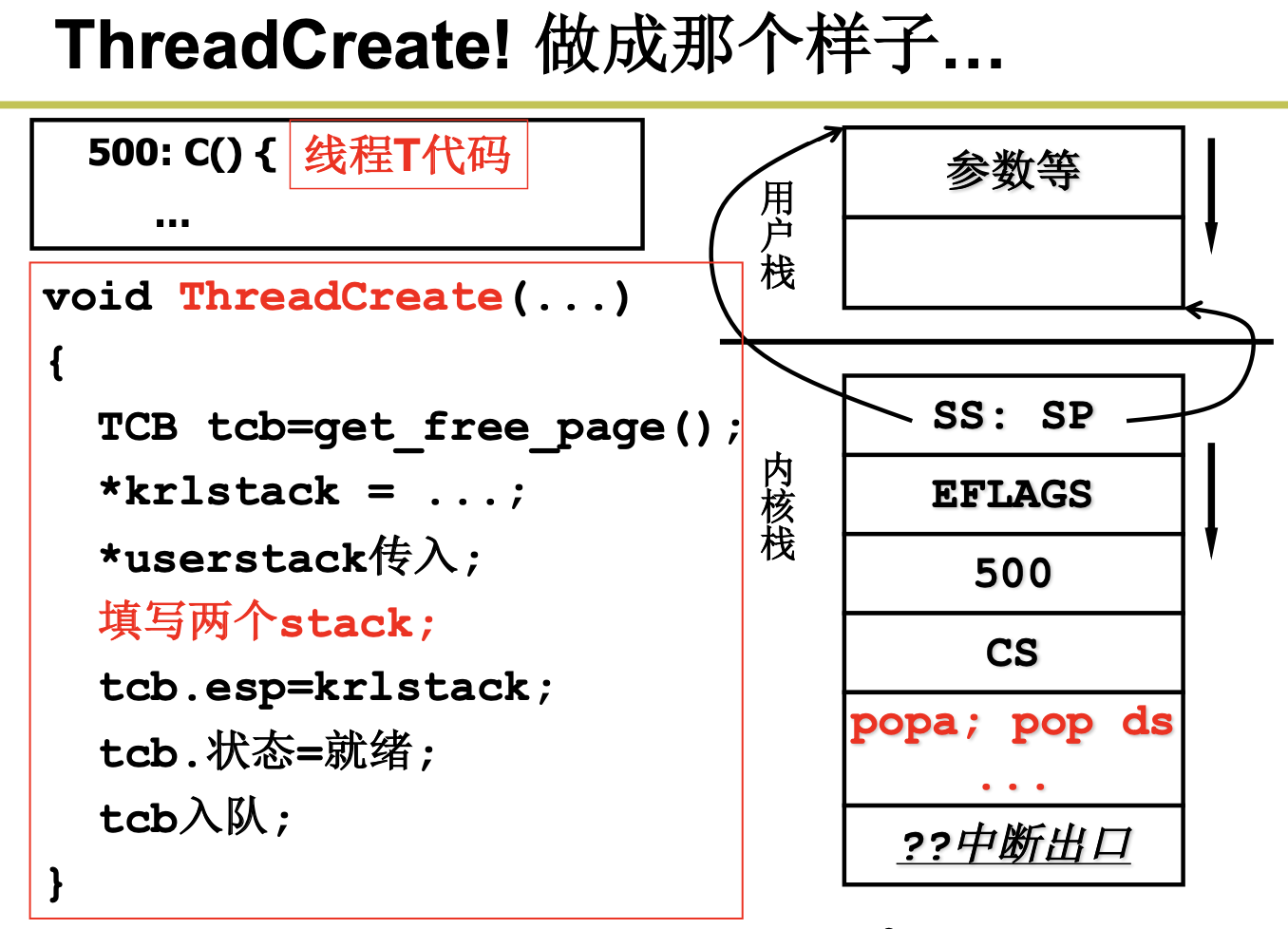
2.2.3 内核级线程的实现


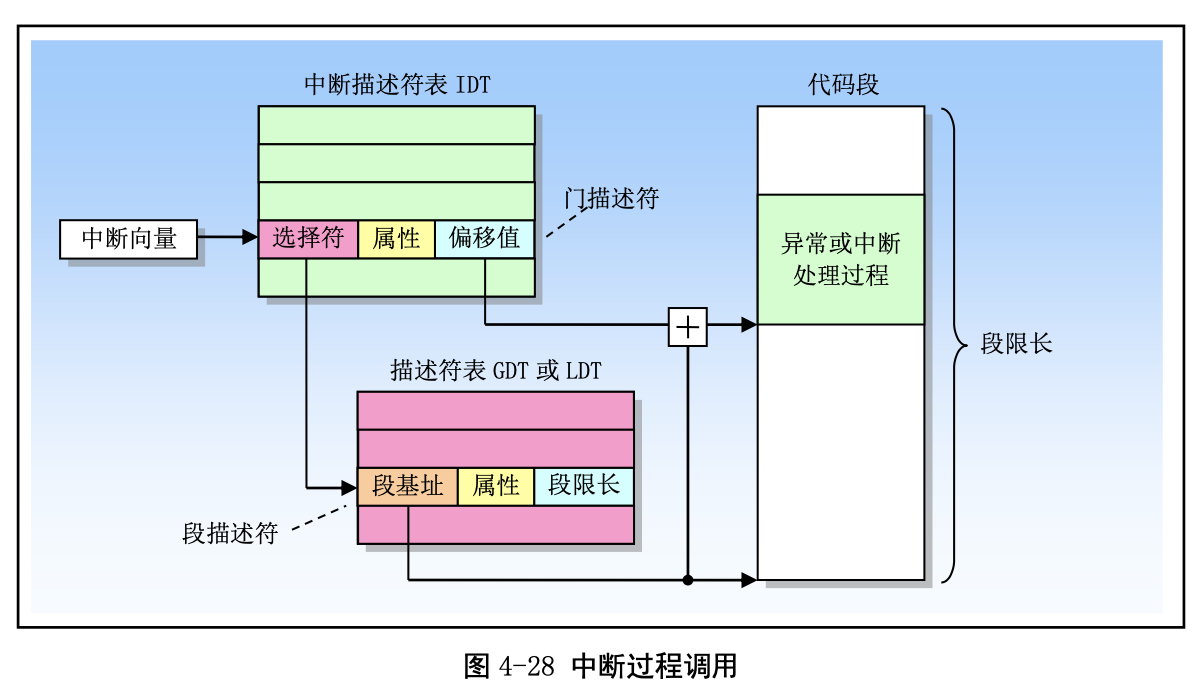
我们来看下中断过程调用。
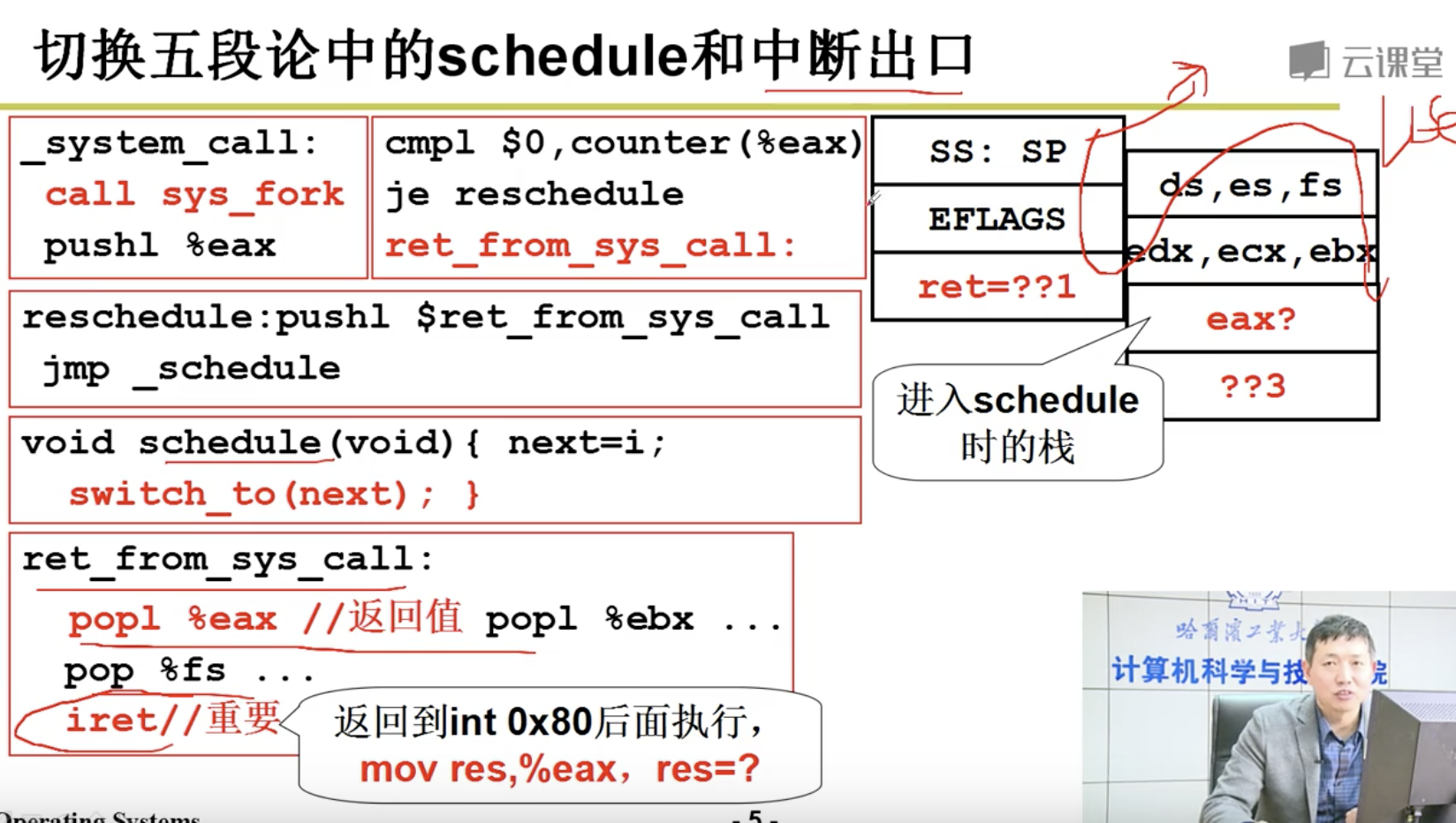




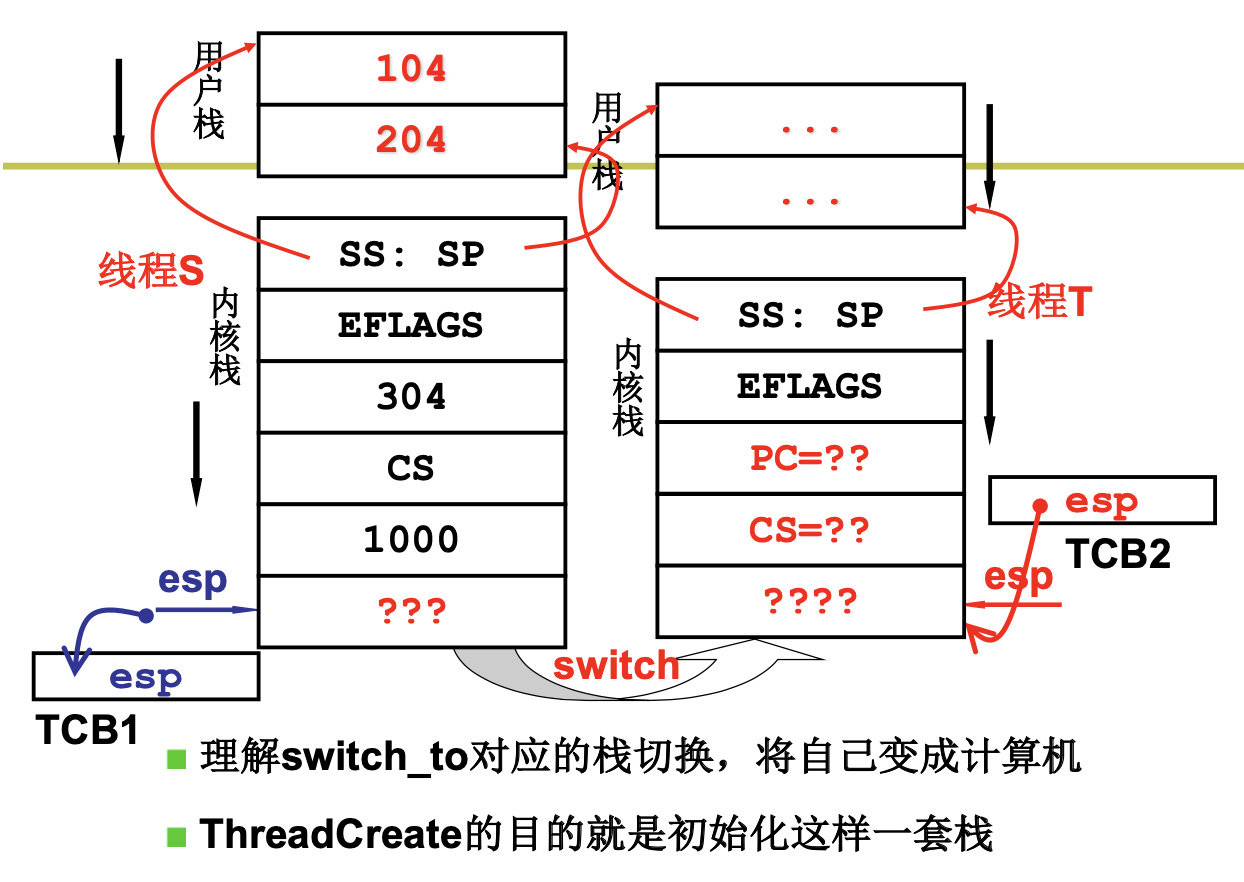
到这里,我们来总结下,CPU运转后,由于有些进程比较耗时,所以我们引入了多进程。如果我们只用一个栈来处理进程的切换,将会造成混乱,所以我们引入了2个栈。有些调用是在内核态的,所以我们必须考虑用户态和内核态的切换,我们引入了切换的5段论。
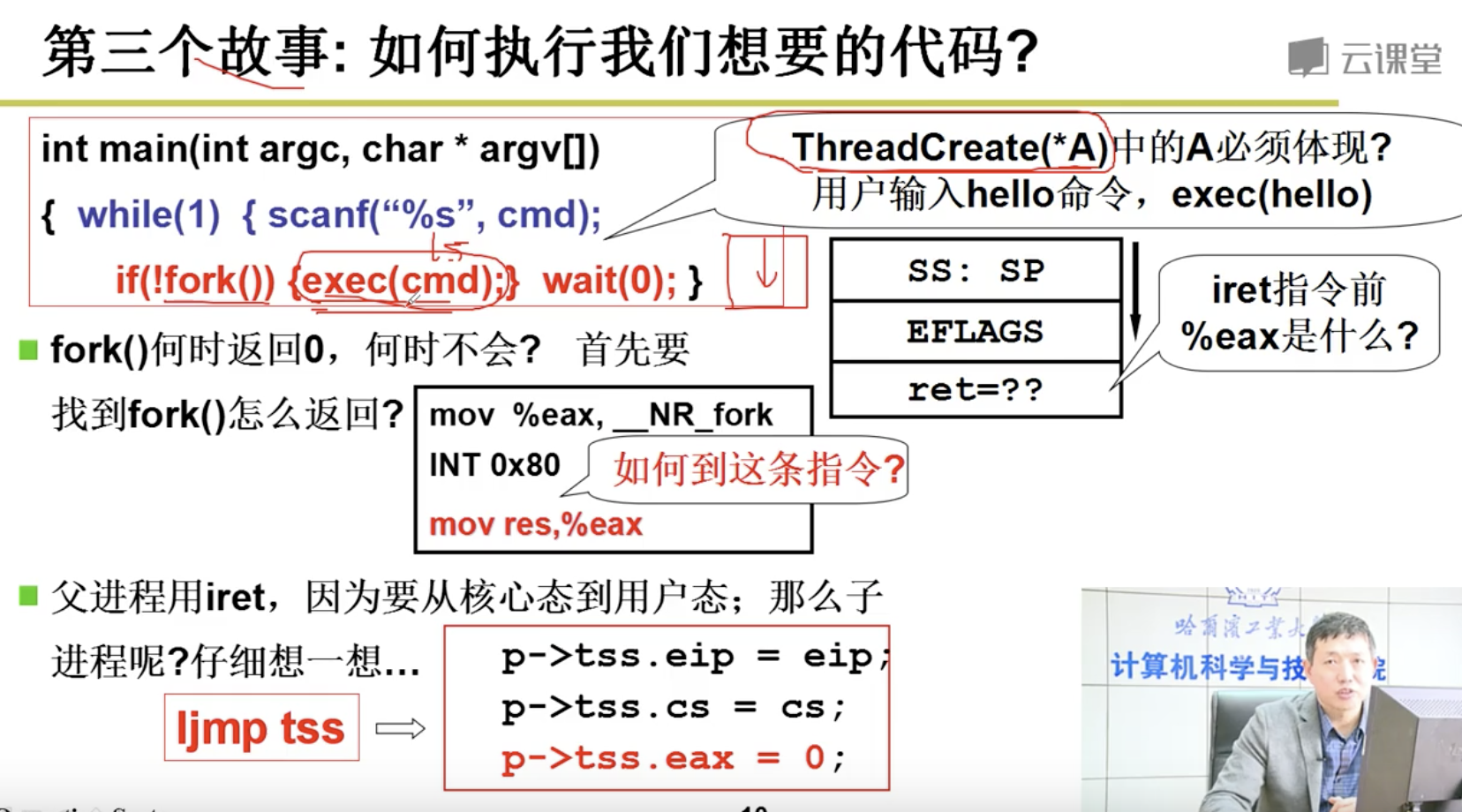
下面我们想实现一段程序,来交替打印A和B:
main(){
if(!fork()){while(1)printf(“A”);}
if(!fork()){while(1)printf(“B”);}
wait();
}
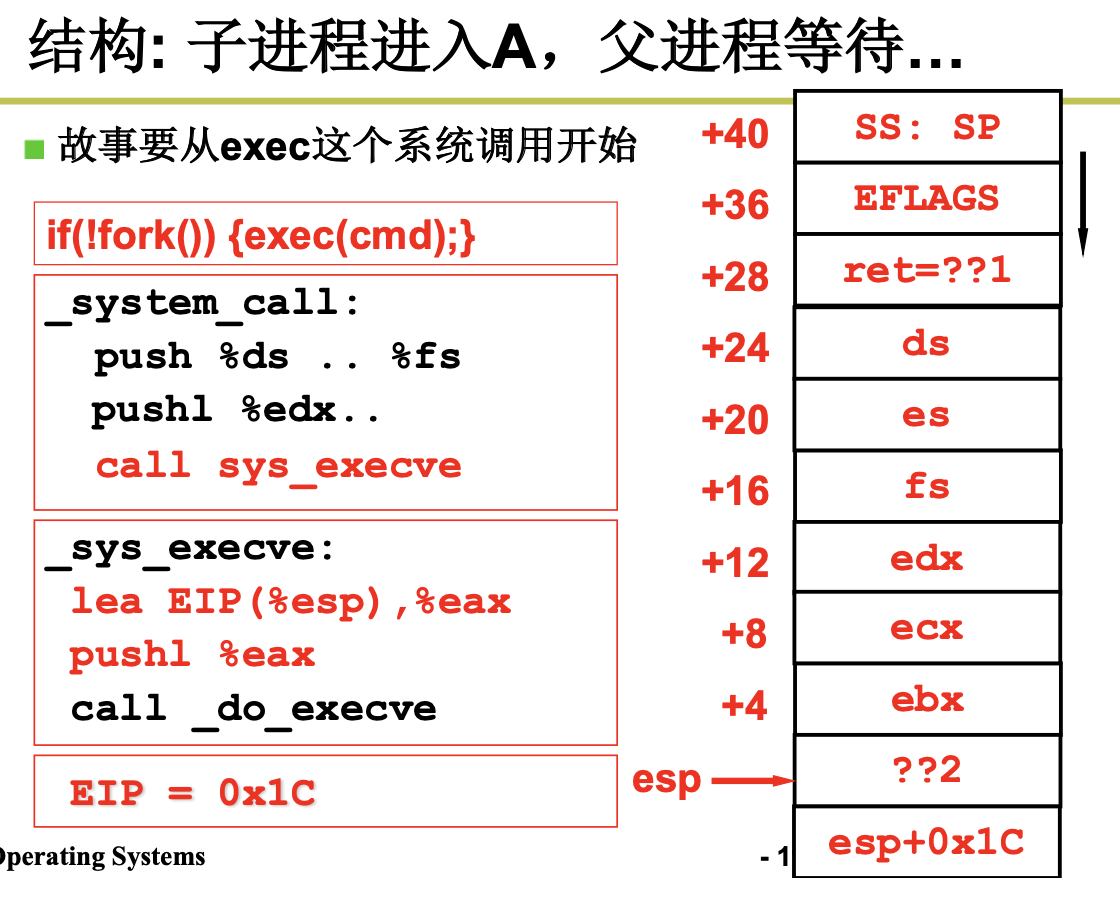
当我们调用fork的时候,将会通过INT指令进入内核,执行sys_fork,调用copy_process,我们将通过ret指令返回到父进程,iret指令返回到子进程。然后再次执行fork,执行了schedule ,然后进行了switch_to切换。那么A什么时候可以和B进行交替打印,答案是时钟中断。
2.2 信号量的实现和应用
2.2.1 进程同步与信号量
Processes Synchronization and Semaphore

注意,这个程序是有问题的,如果,在生产者访问的时候,别切走了,切回来之后,counter被修改了,但是生产者还不知道。
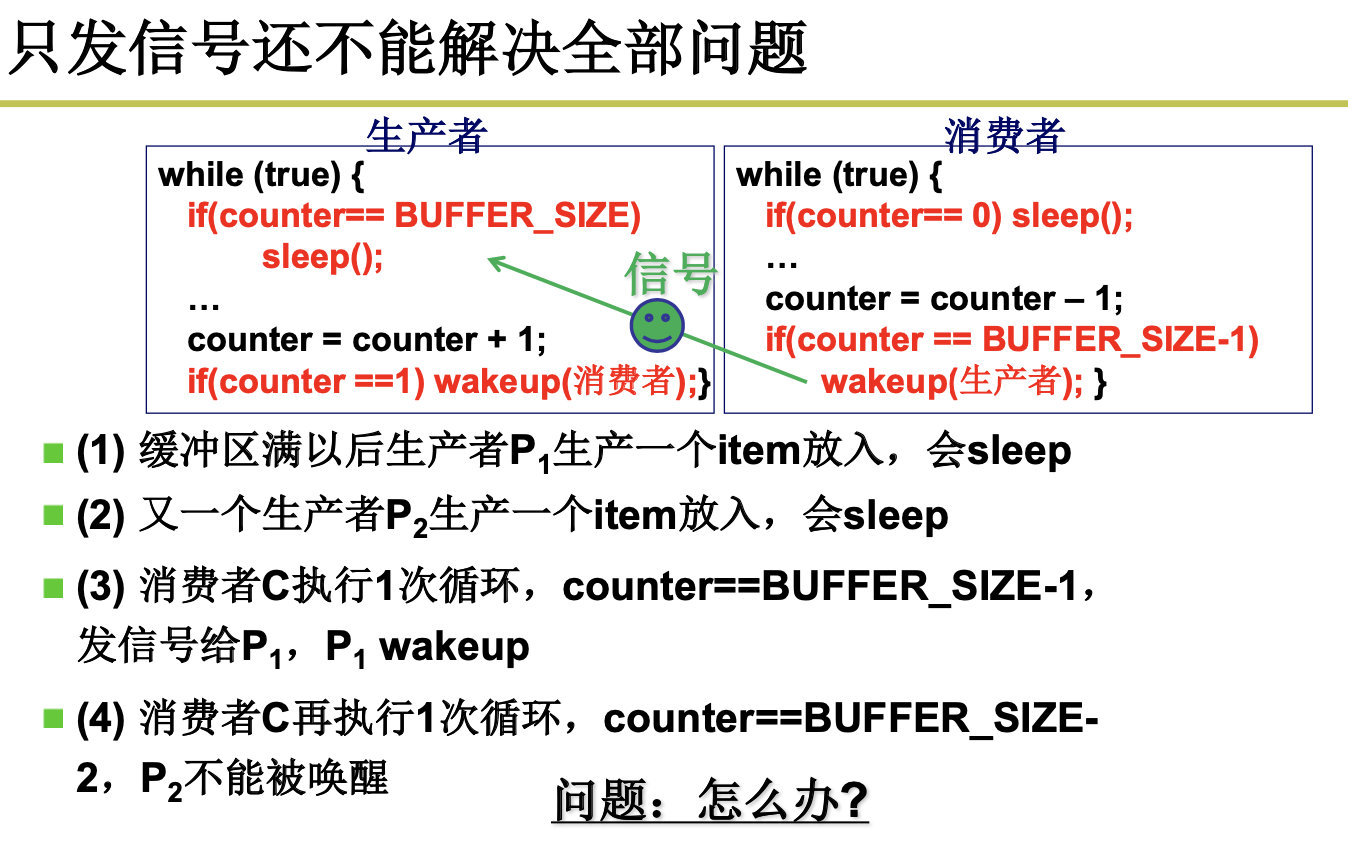



empty表示空闲缓冲区的个数,full表示已经生产的个数,multx表示互斥信号:

2.2.2 信号量临界区保护
靠临界区保护信号量,靠信号量实现进程的同步。
Critical Section
温故而知新:什么是信号量? 通过对这个量的访问和修改,让大 家有序推进。哪里还有问题吗?
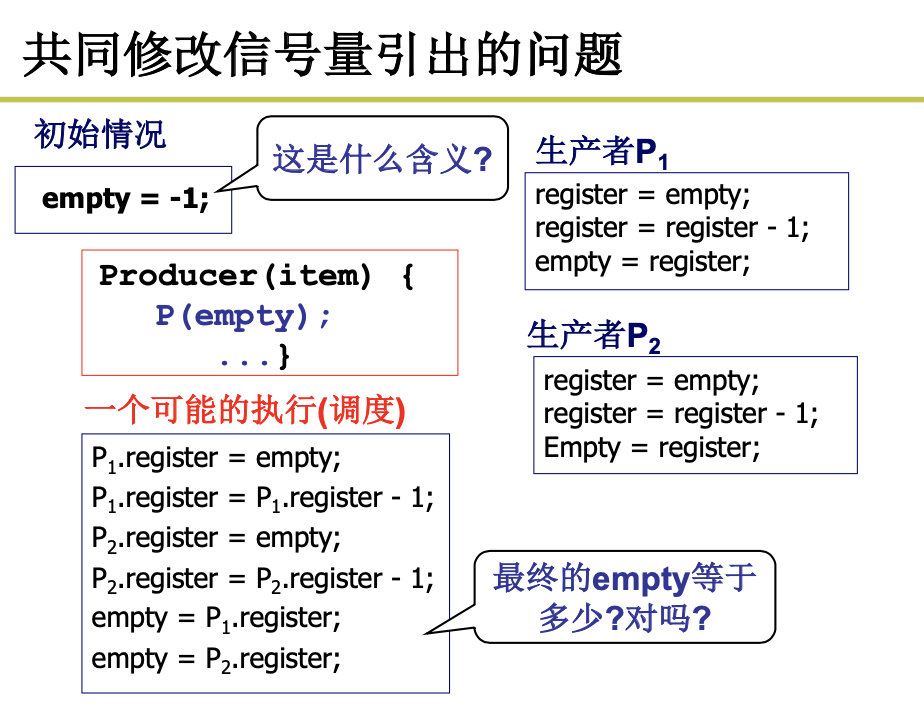
empty=-1,表示已经有一个进程在睡眠了。

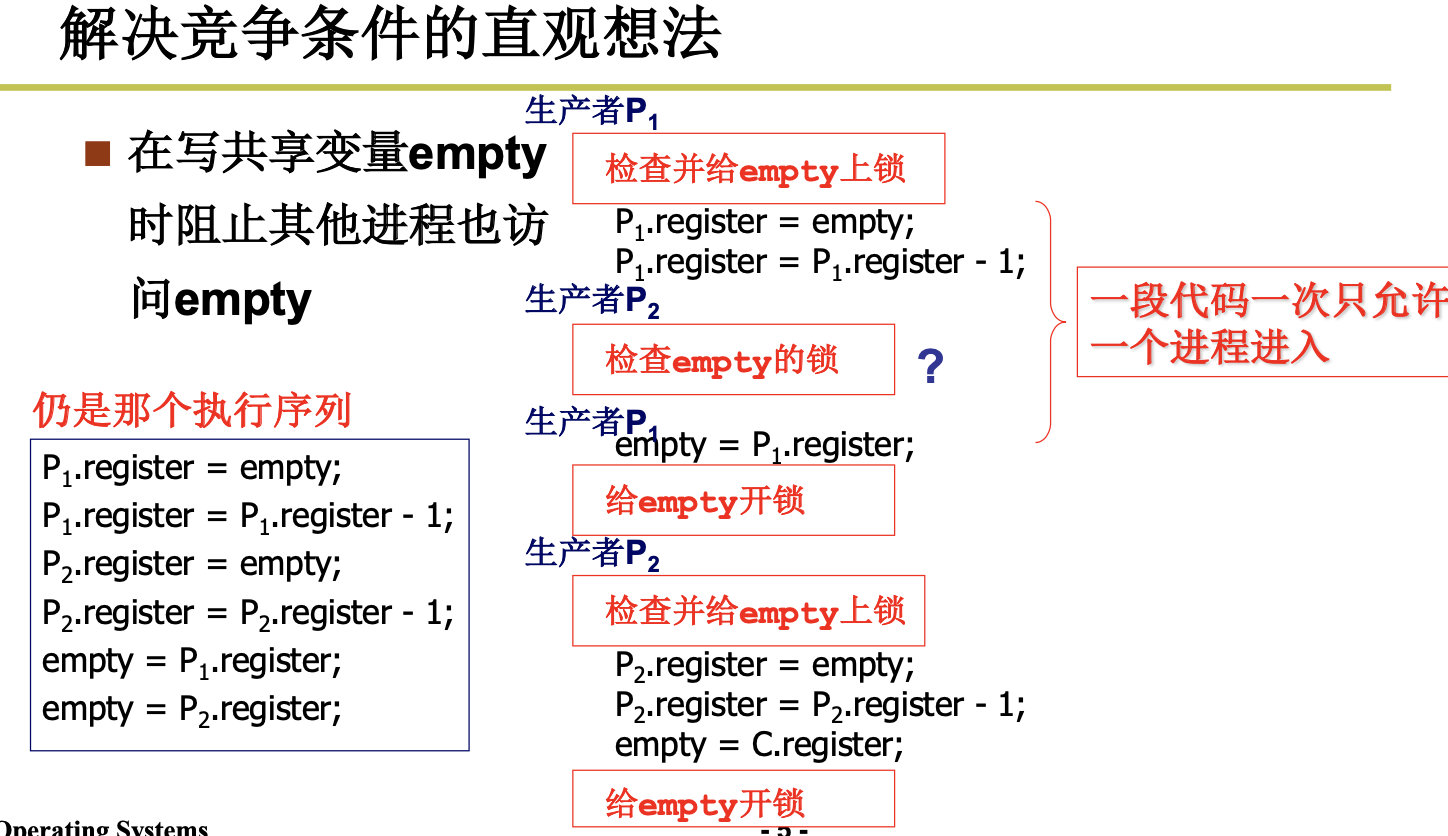

进入临界区的方法:
轮换法(也称值日法),满足互斥,但是不满足有空让进,比如,P0进入后,turn=1,然后由于某种原因,一直在等待,这个时候,P2也无法进入。
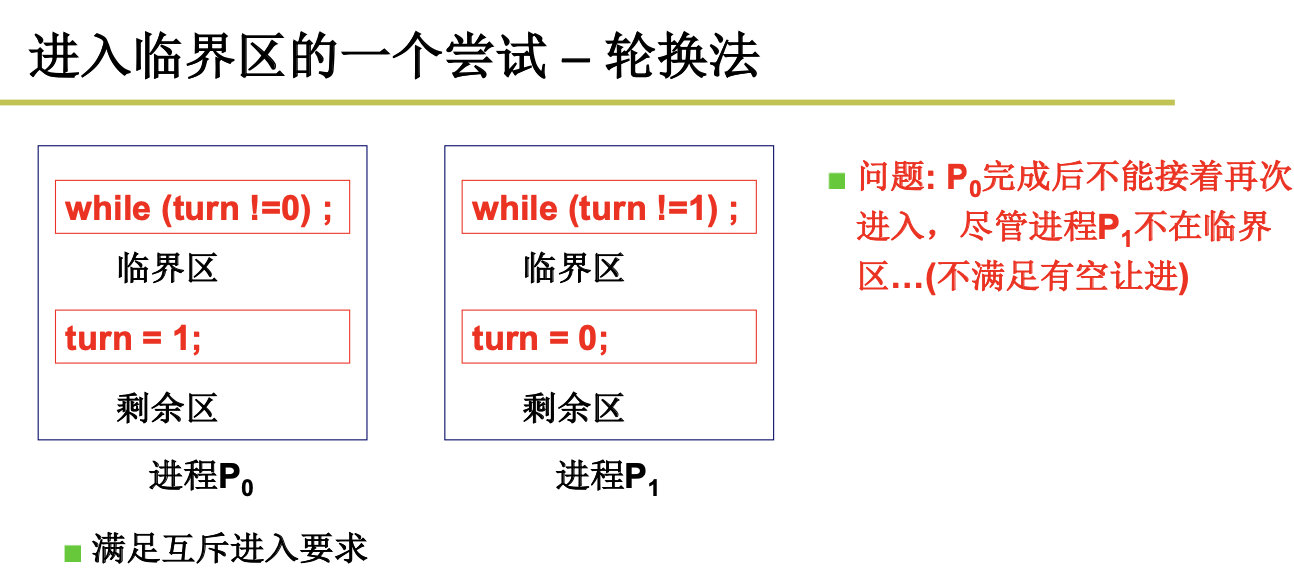
然后我们引入了标记法,发现虽然满足了,互斥,有空让进,但是不满足有限等待。

然后我们又引入了非对称标记:

flag[1]=true,turn=1,表示1要进入临界区,并且轮到1进入。

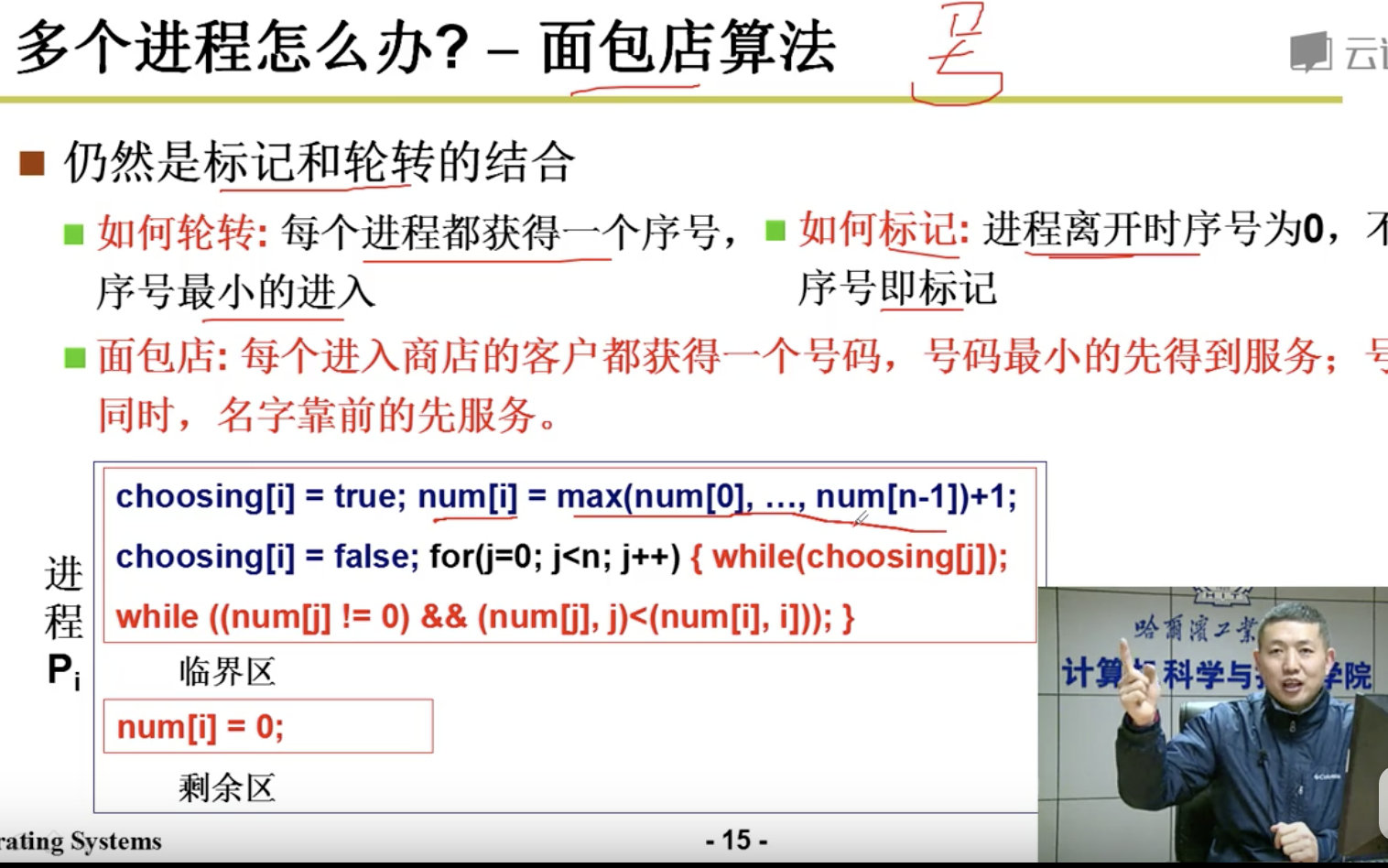
下面我们只是讨论了2个进程,那么多个进程怎么办呢?

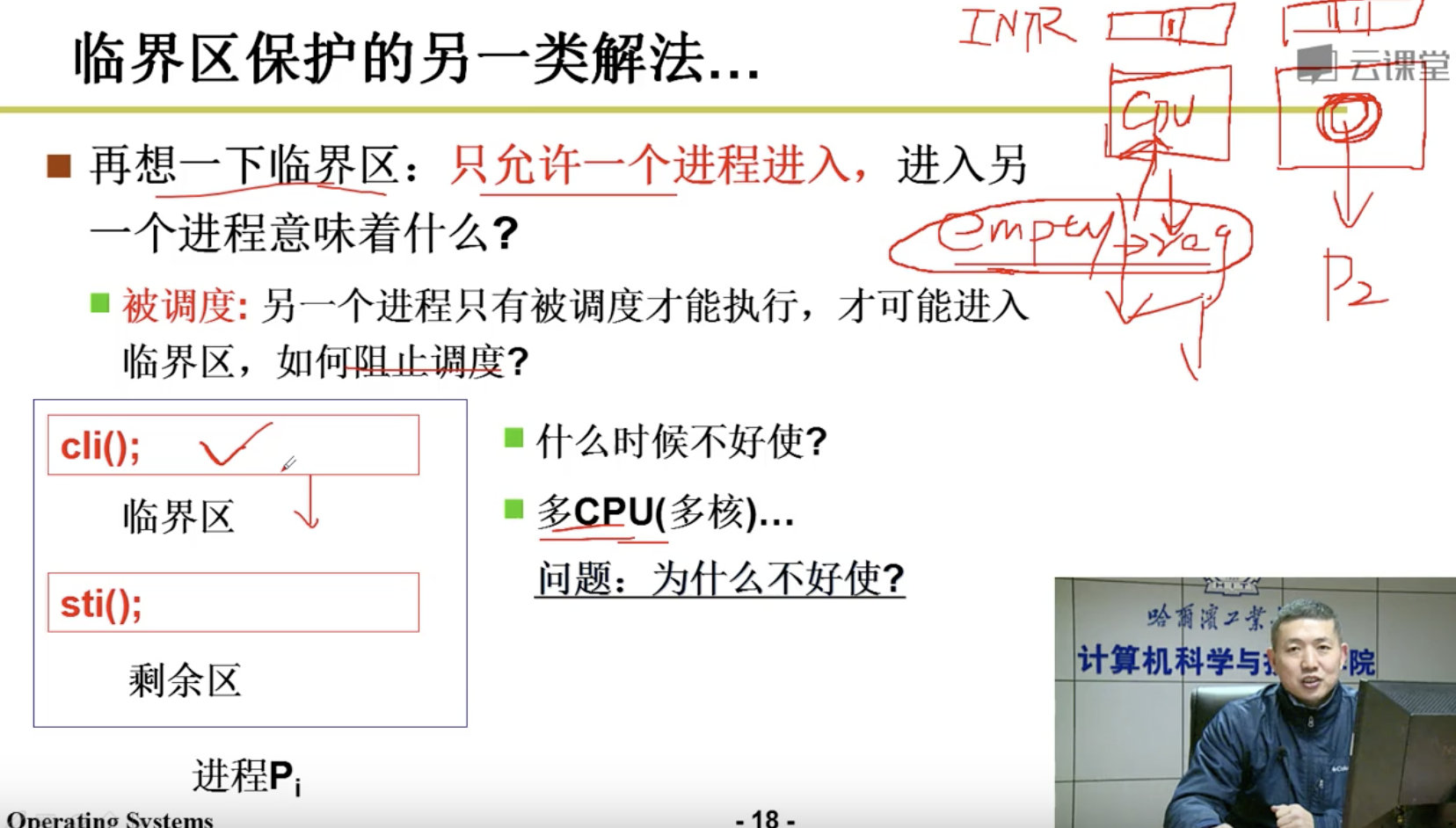
面包店算法是在是太复杂了,我们尝试另外的解法,回想一下,我们只允许一个进程进入,这句话意味着什么呢?意味着另一个进程只有被调度才可以进入临界区,那么我们只要阻止时钟中断就好了。即CPU不会在调度。
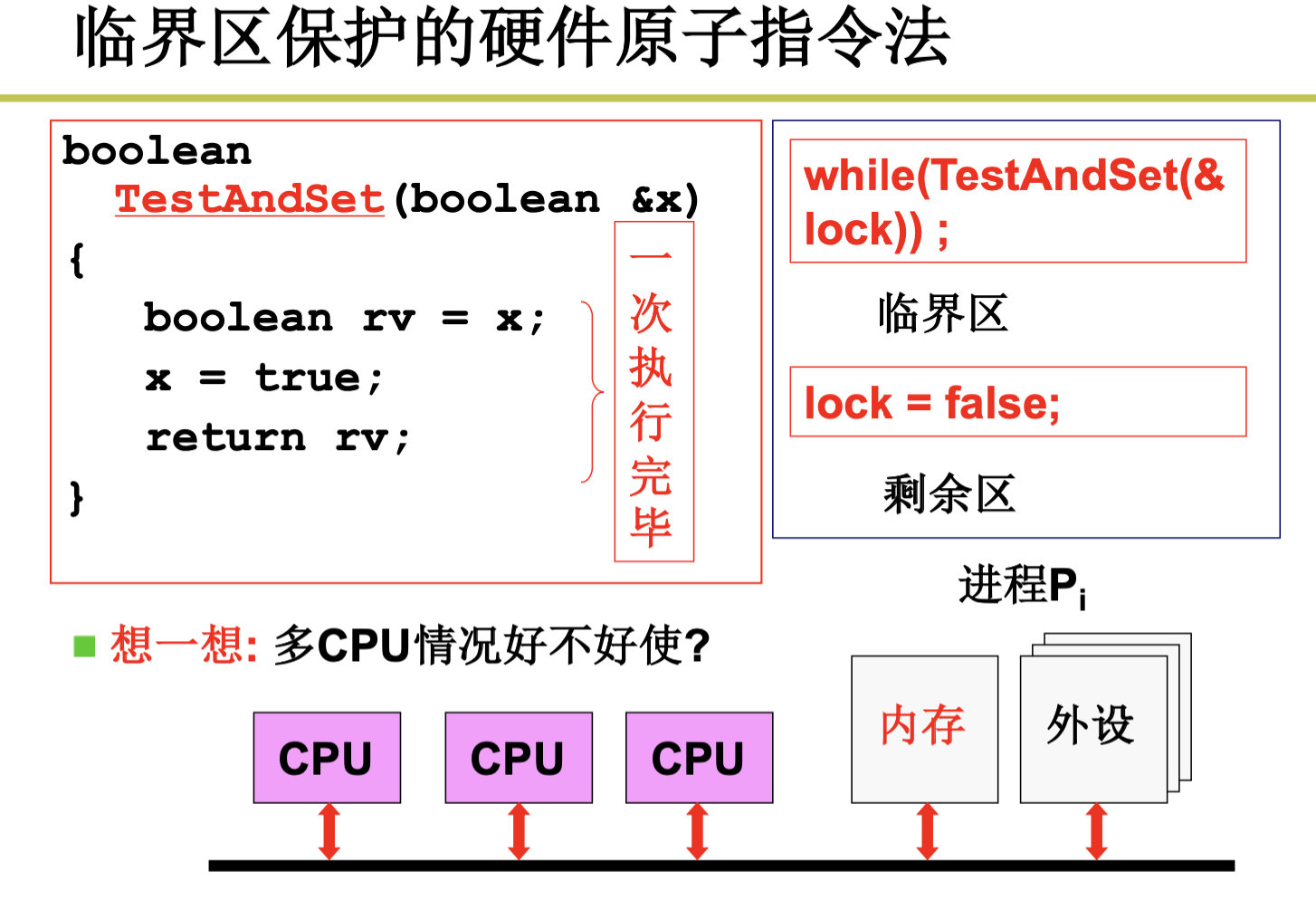
但是多CPU不行,因为我们没法关掉所有CPU的中断。
接下来我们引入了硬件原子指令法:
2.2.3 信号量的代码实现
Coding Semaphore


2.2.4 死锁处理
3. 内存管理
地址映射与共享
3.1 内存使用与分段
Memory and Segmentation
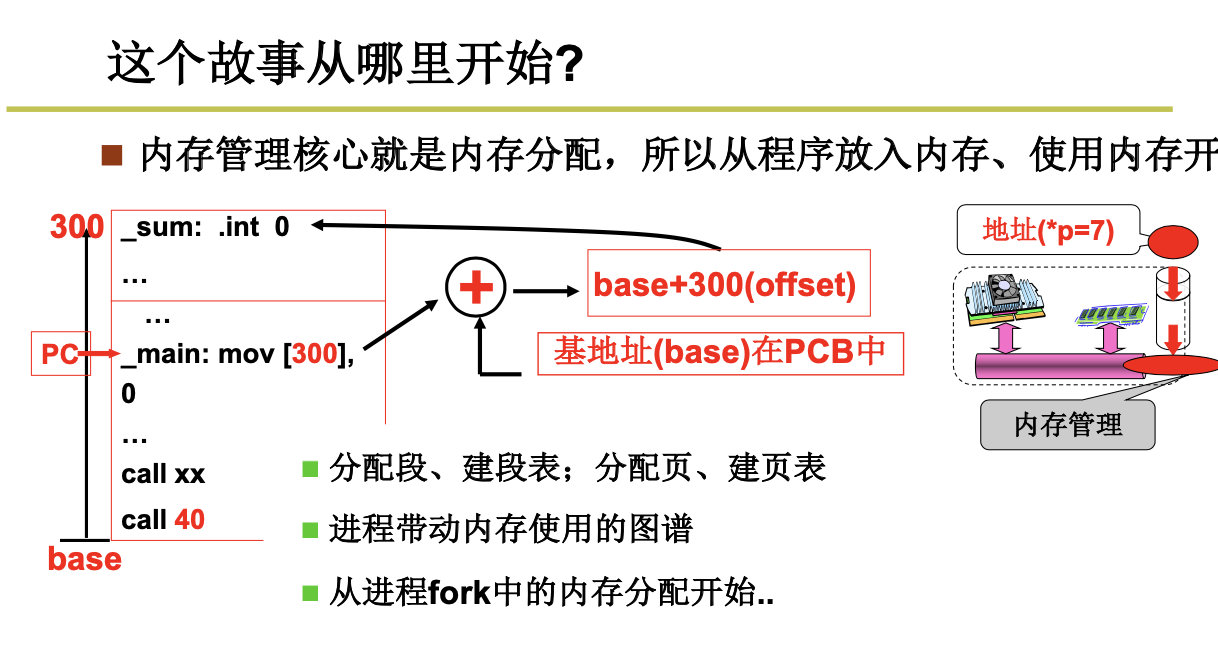
我们把程序装入内存后,需要进行重定位,那么我们什么时候进行重定位呢?编译时还是加载时呢?看看优缺点:编译时重定位的程序只能放在内存固定位置 ,载入时重定位的程序一旦载入内存就不能动了。
这两个方法都是存在缺点的,那么我们能不能在运行时进行重定位呢?
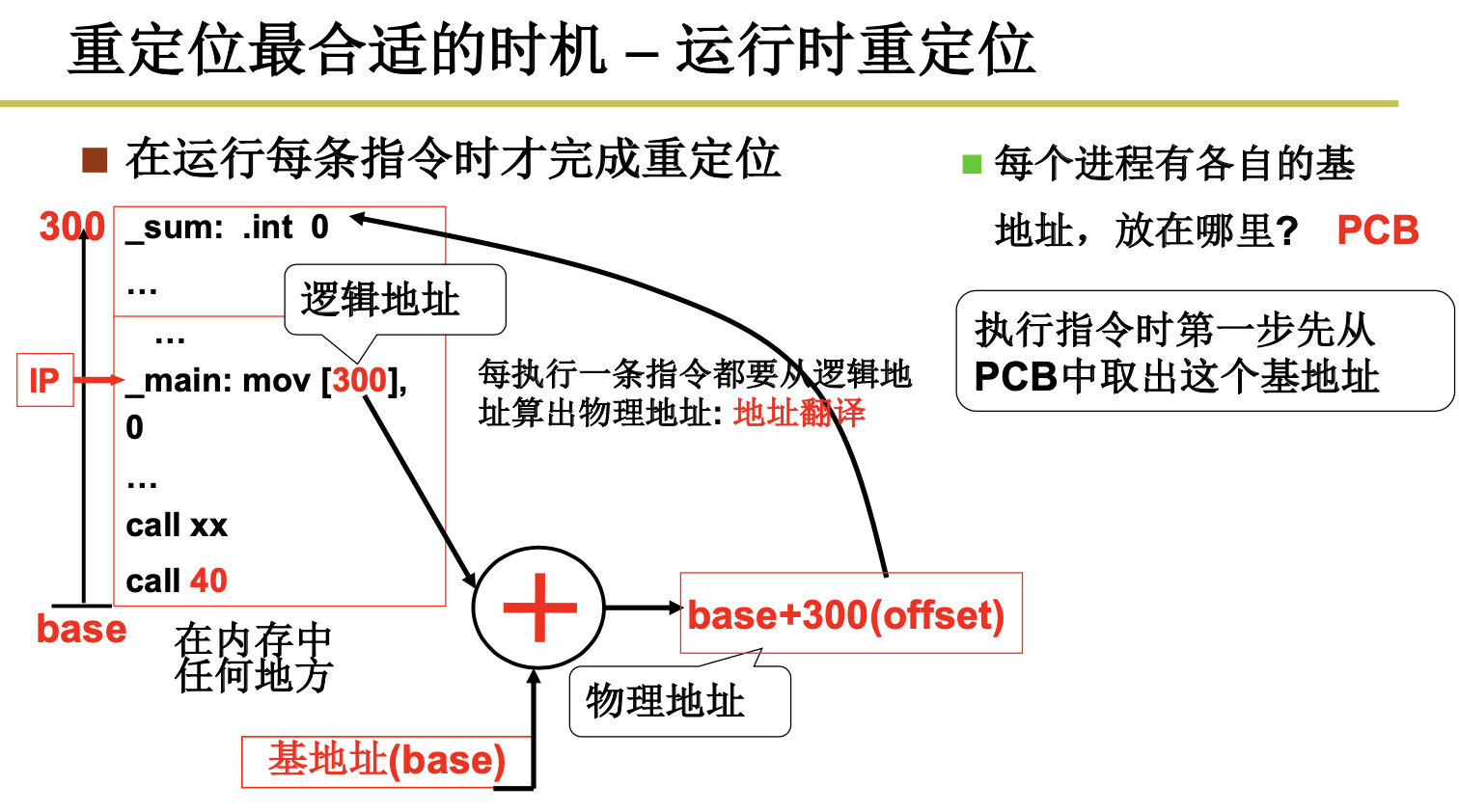
我们来总结下:
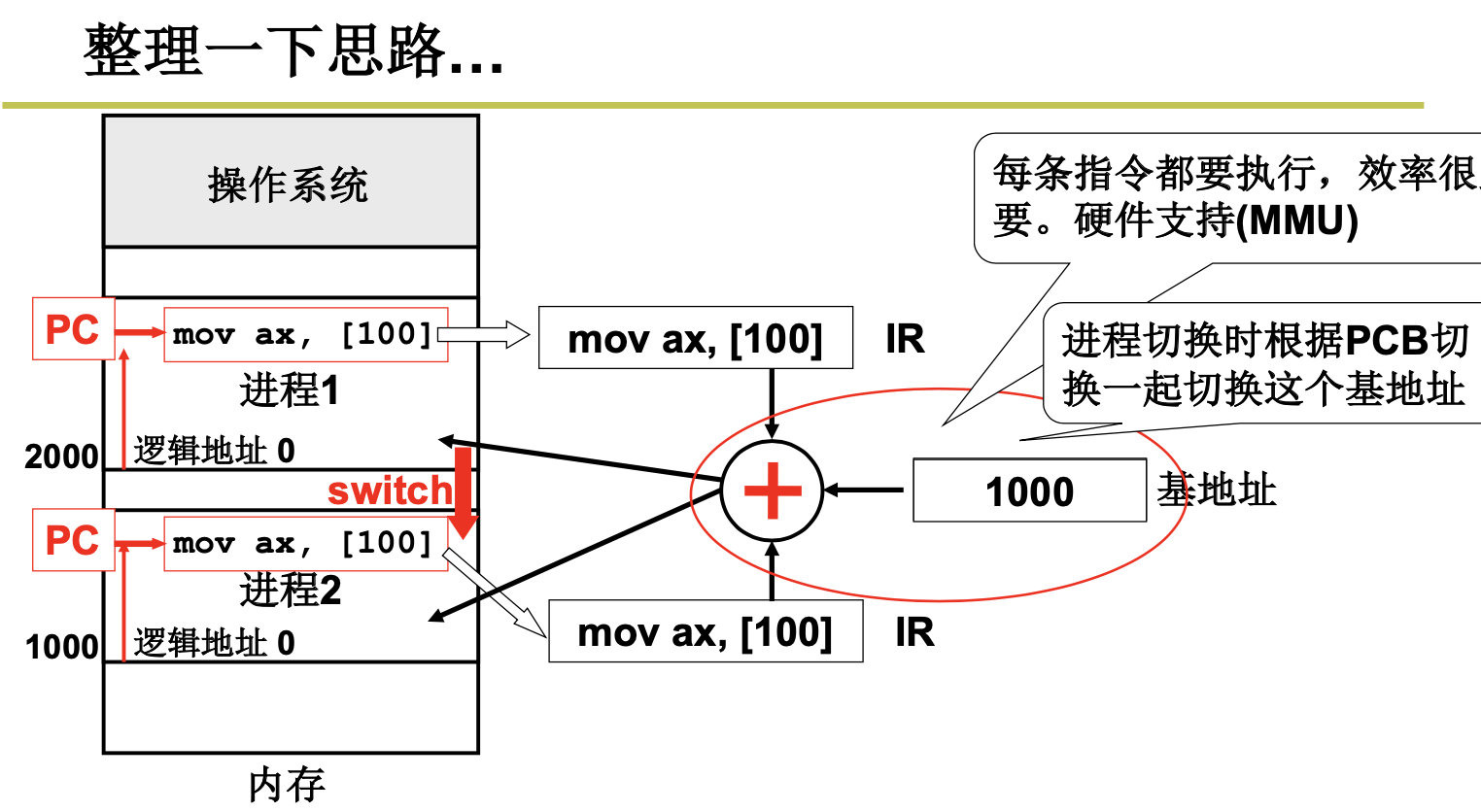
事情到这里。好像问题得到了完美的解决。但是没有这么简单,难道我们需要把程序都装到内存中吗?当然不是啦。
我们根据代码的特点和用途,将代码进行分段,比如数据段和代码段,可以参考这个:https://haojunsheng.github.io/2019/12/Linker-Loader/
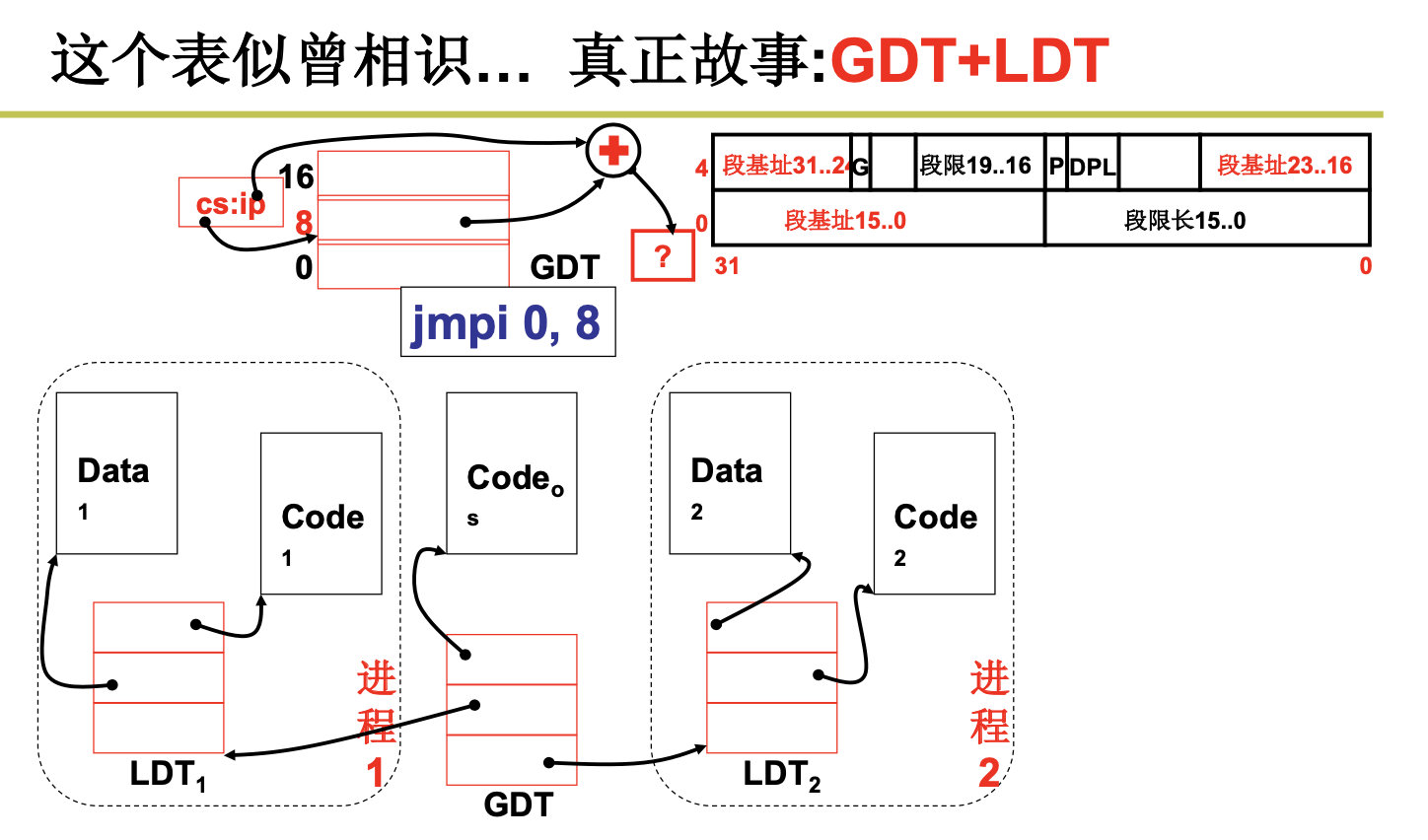
真正的故事是从GDT和LDT开始的(全局符号描述表和局部符号描述表)
3.2 内存分区与分页
Memory Partition and Paging
接下来我们就可以把各个段放到相应的内存分区了。
由于内存需要不断的换入换出,我们首先尝试内存分区的办法,但是我们发现内存分区的效率是很低的,而且还会导致内存碎片的问题。
我们还要继续去思考解决的办法,我们可以尝试将连续的内存变为离散的内存,即将内存进行分页,针对每个段内存请求,系统一页一页的分配给给这个段。
此时不再需要内存紧缩了,我们最大仅浪费4k的内存。

3.3 多级页表与快表
Multilevel Paging
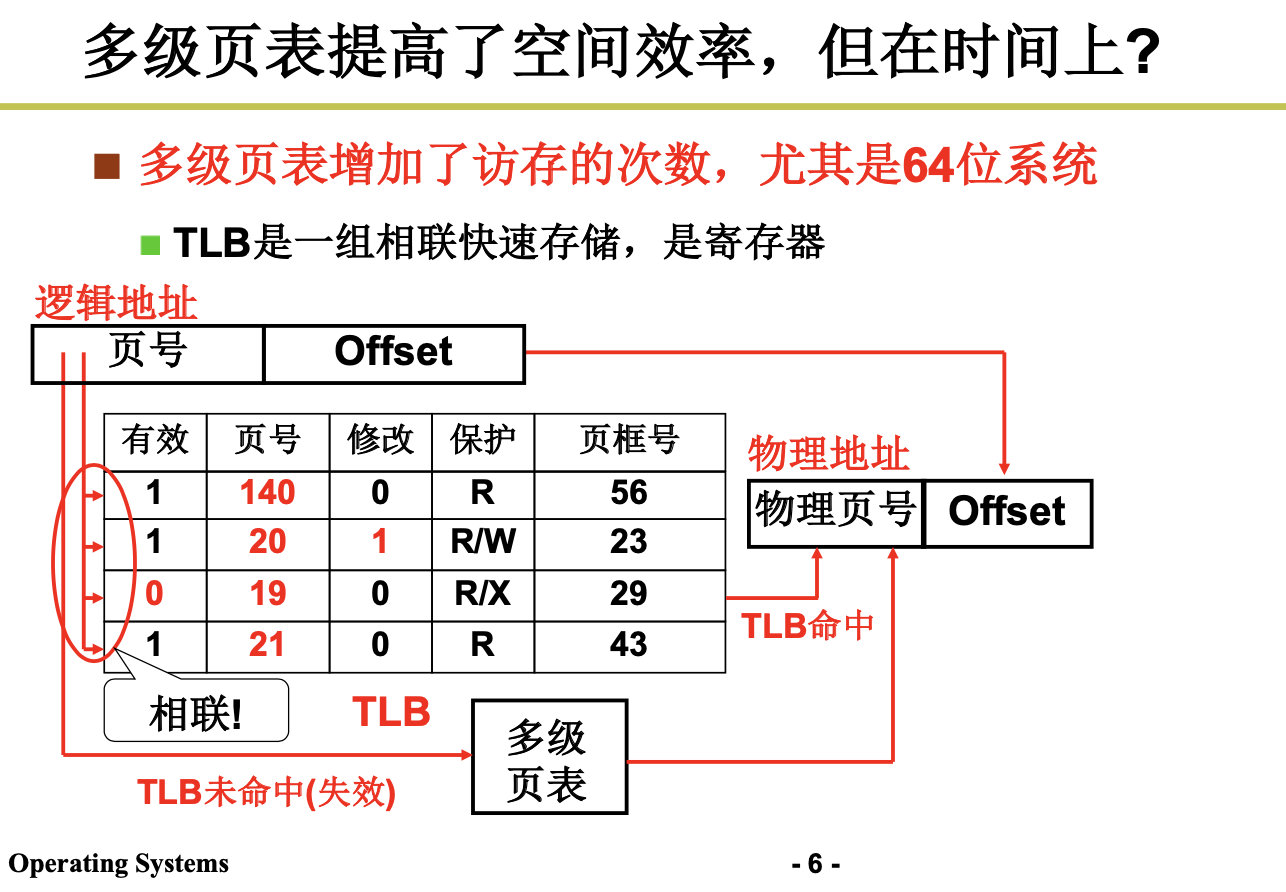
我们为了提高空间利用率,每个页应该尽可能的小,但是页小了,页表就会变大,进而导致页表的放置成问题。哎,难搞啊。
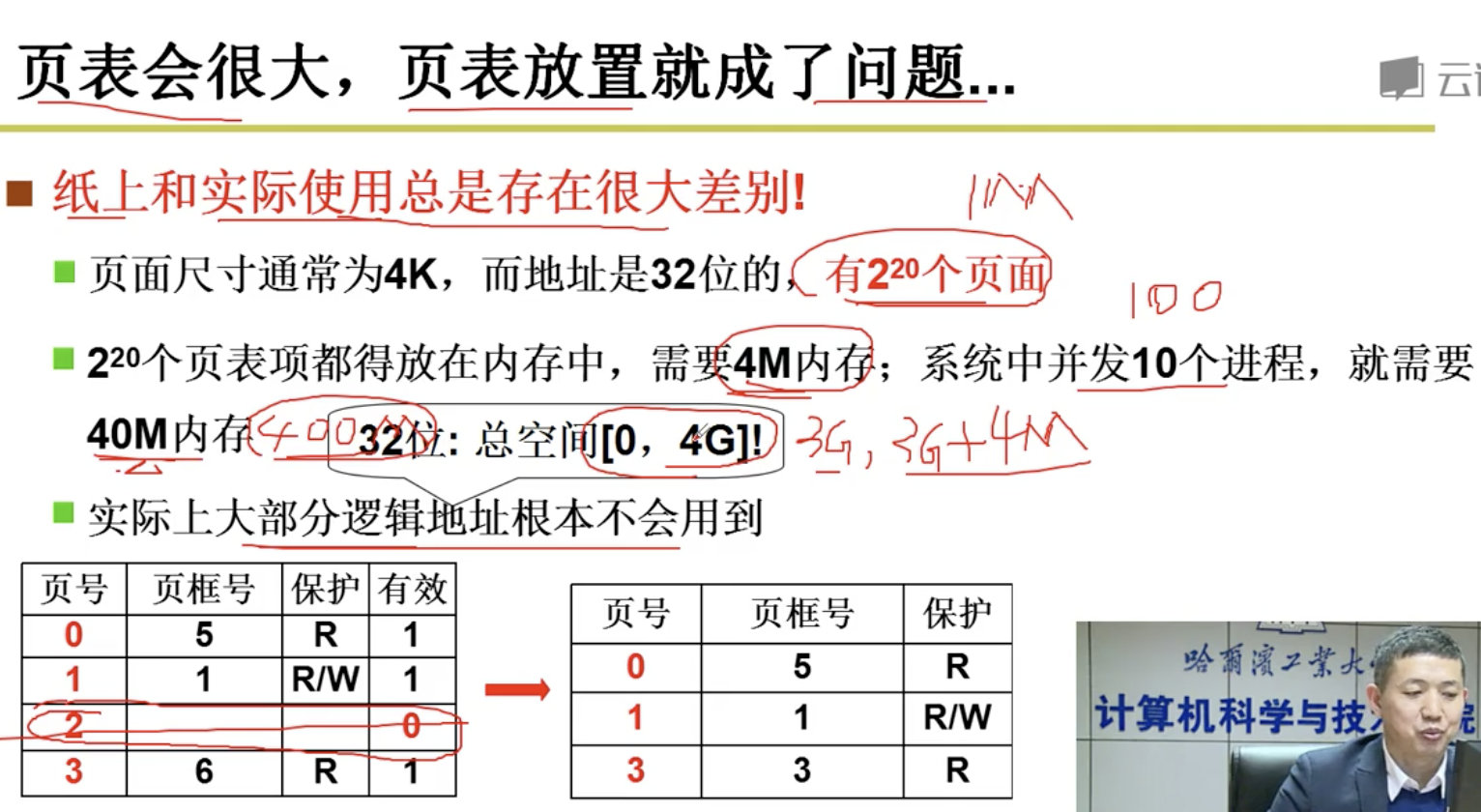
但是在实际中,不是所有的逻辑地址都会使用的,比如,32位的操作系统,逻辑地址空间是4G,那么我们可不可以只存放用到的页。
但是引出了新的问题,页号不再连续,我们在访问指令之前,需要先查找页,无论是采用顺序查找,还是折半查找,都是很费劲的。需要增加访问内存的次数。哎,解决了旧的问题,还有新的问题。

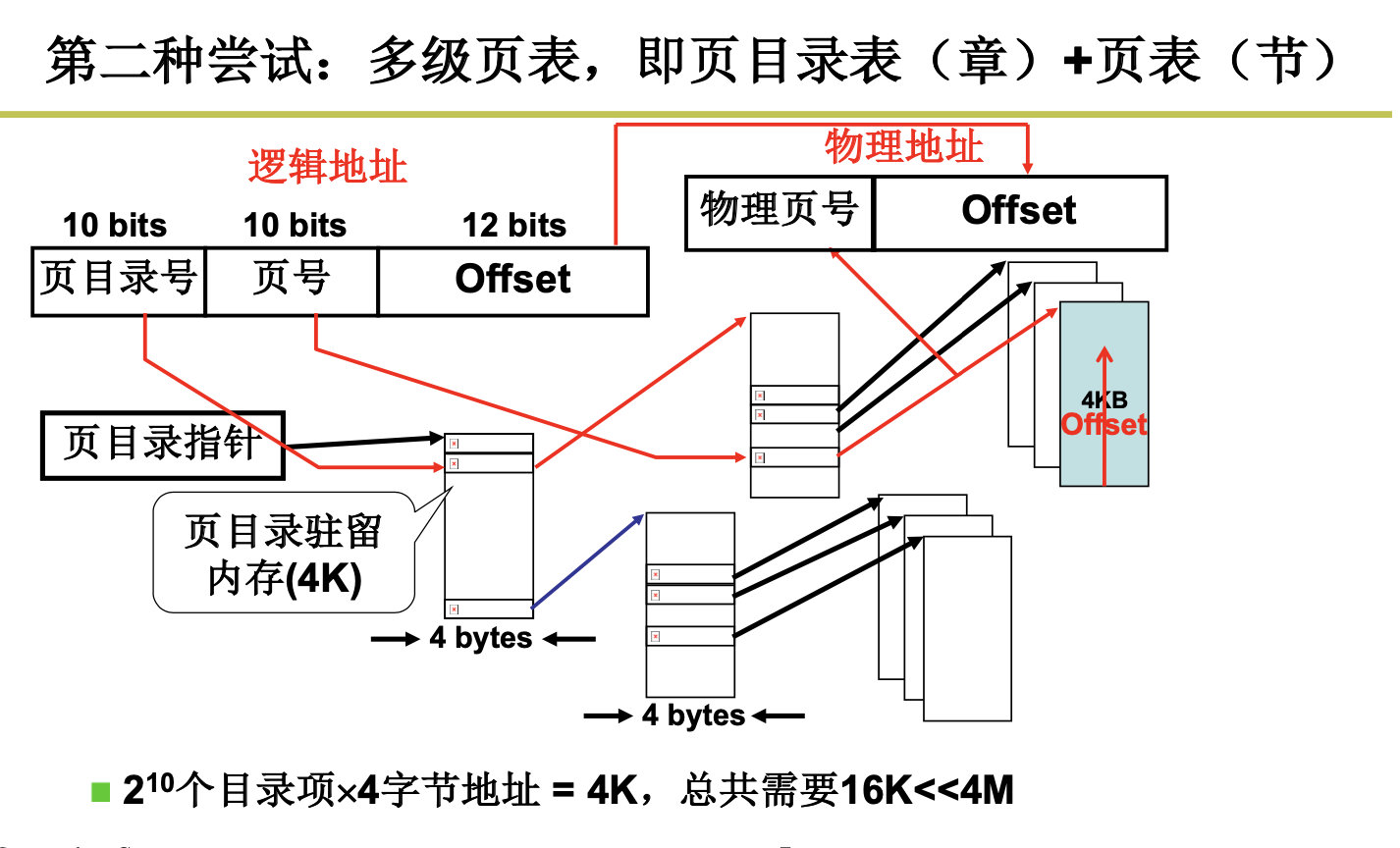
我们开始新的尝试,我们既要满足页表的连续性,又要满足尽量少放入内存的需求,哈哈,既要,又要,是不是很难搞,但是总是有办法的,我们可以引入多级列表,即页目录+页表。

3.4 段页结合的实际内存管理
Segmentation & Paging
段、页结合: 程序员希望用段, 物理内存希望用页,所以段和页进行结合。
注意:
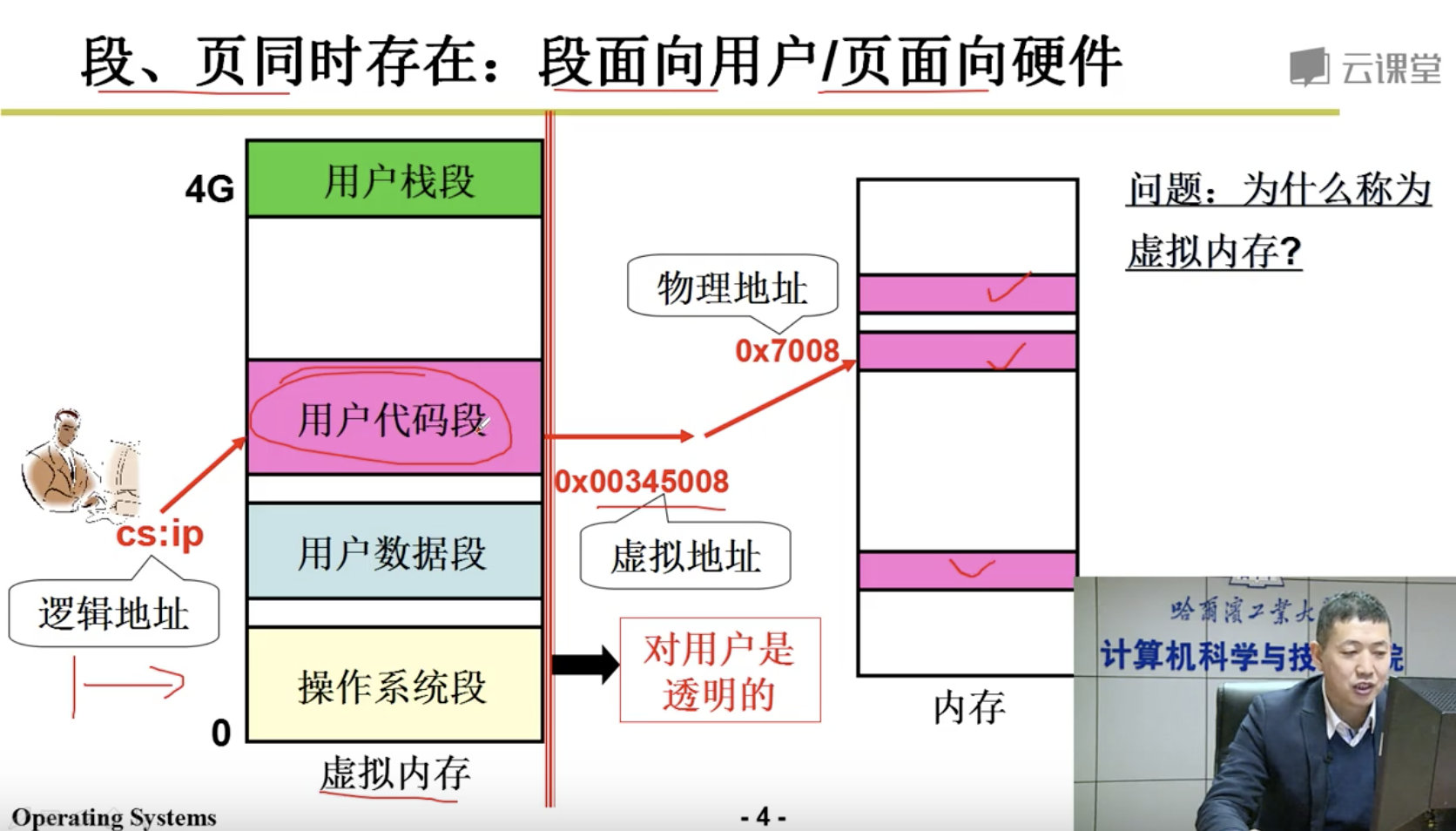
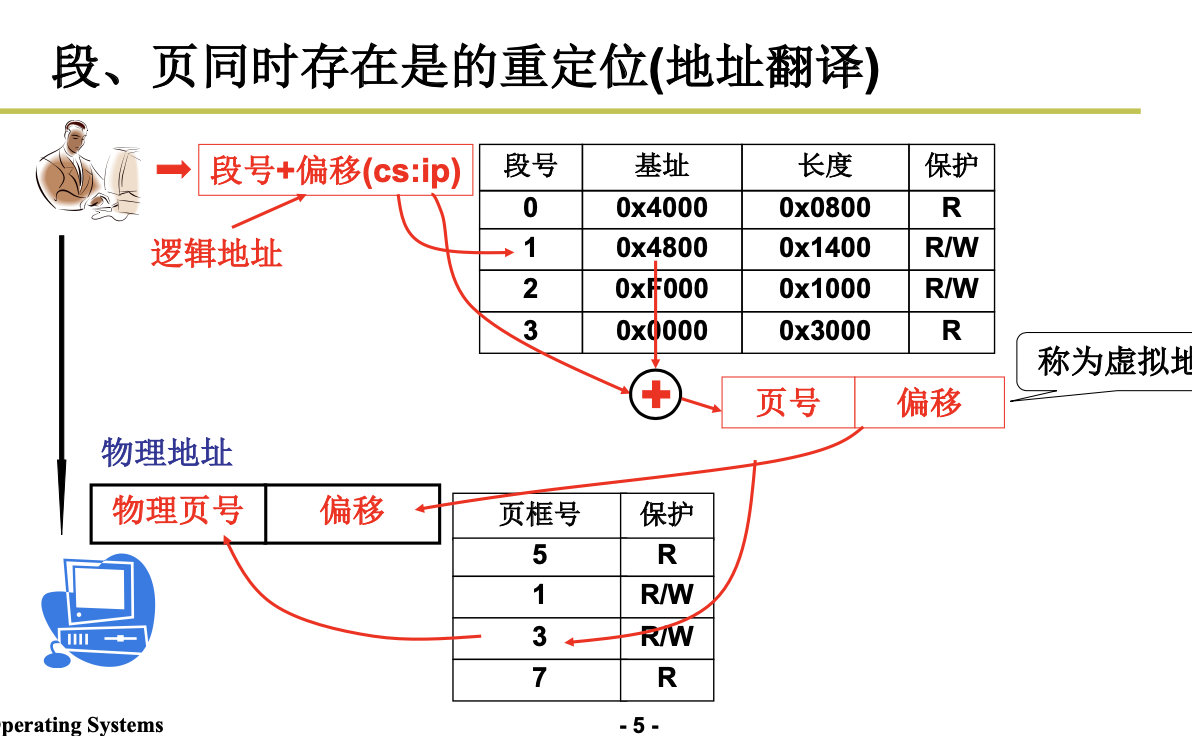
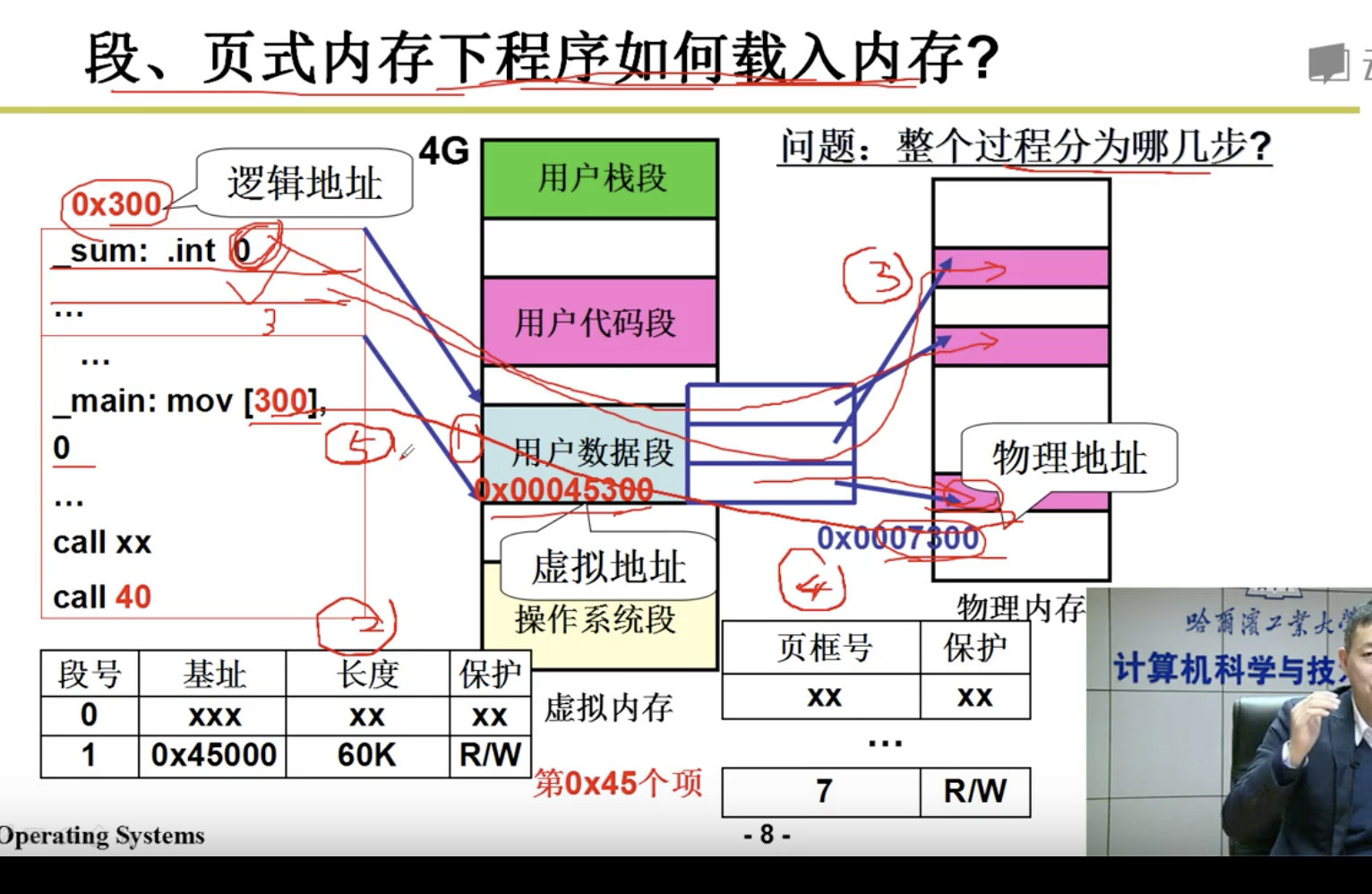
下面我们的任务是讲清楚这5步:
分配虚存,建段表,分配内存,建页表,地址重定位。

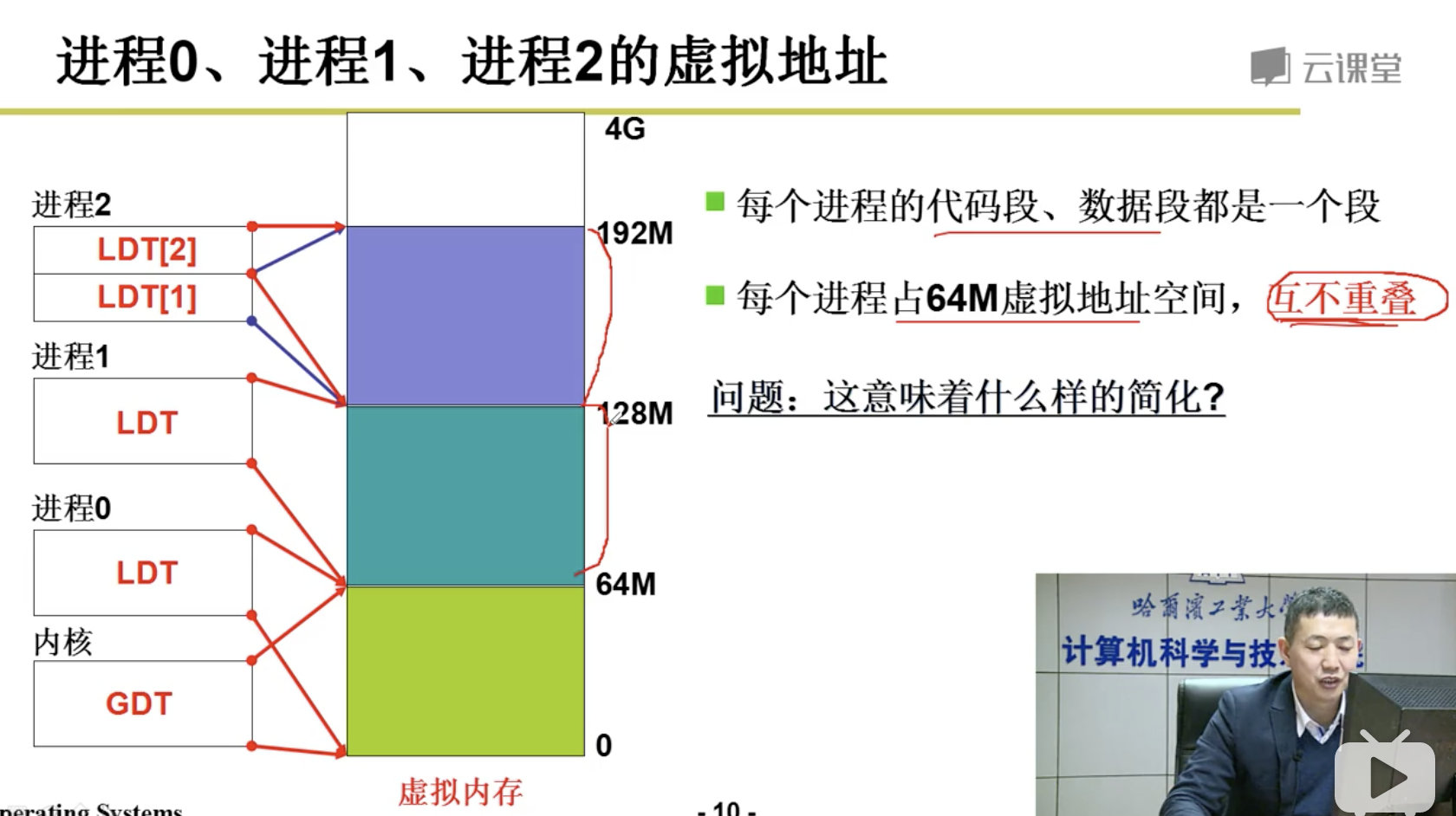
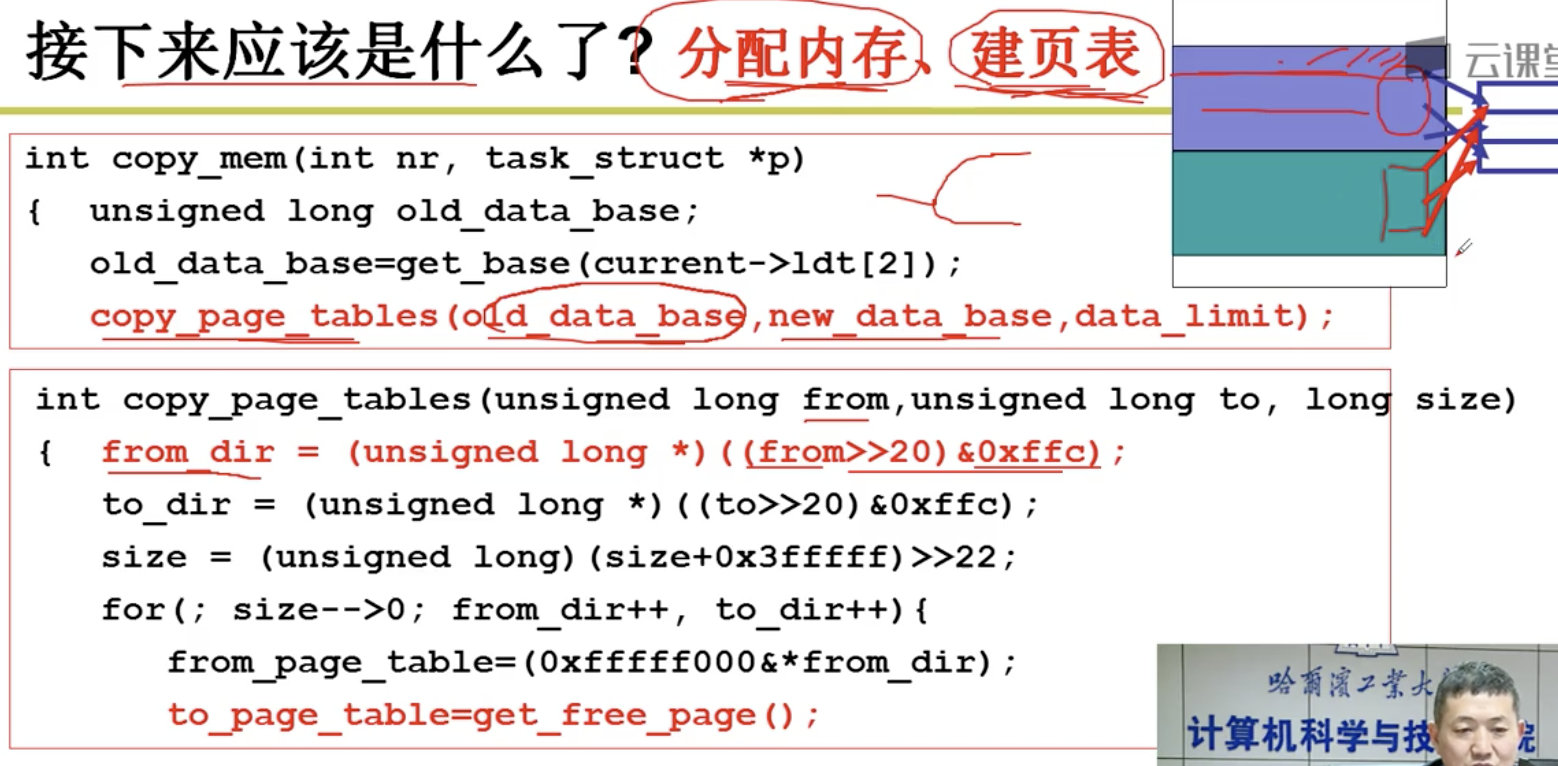

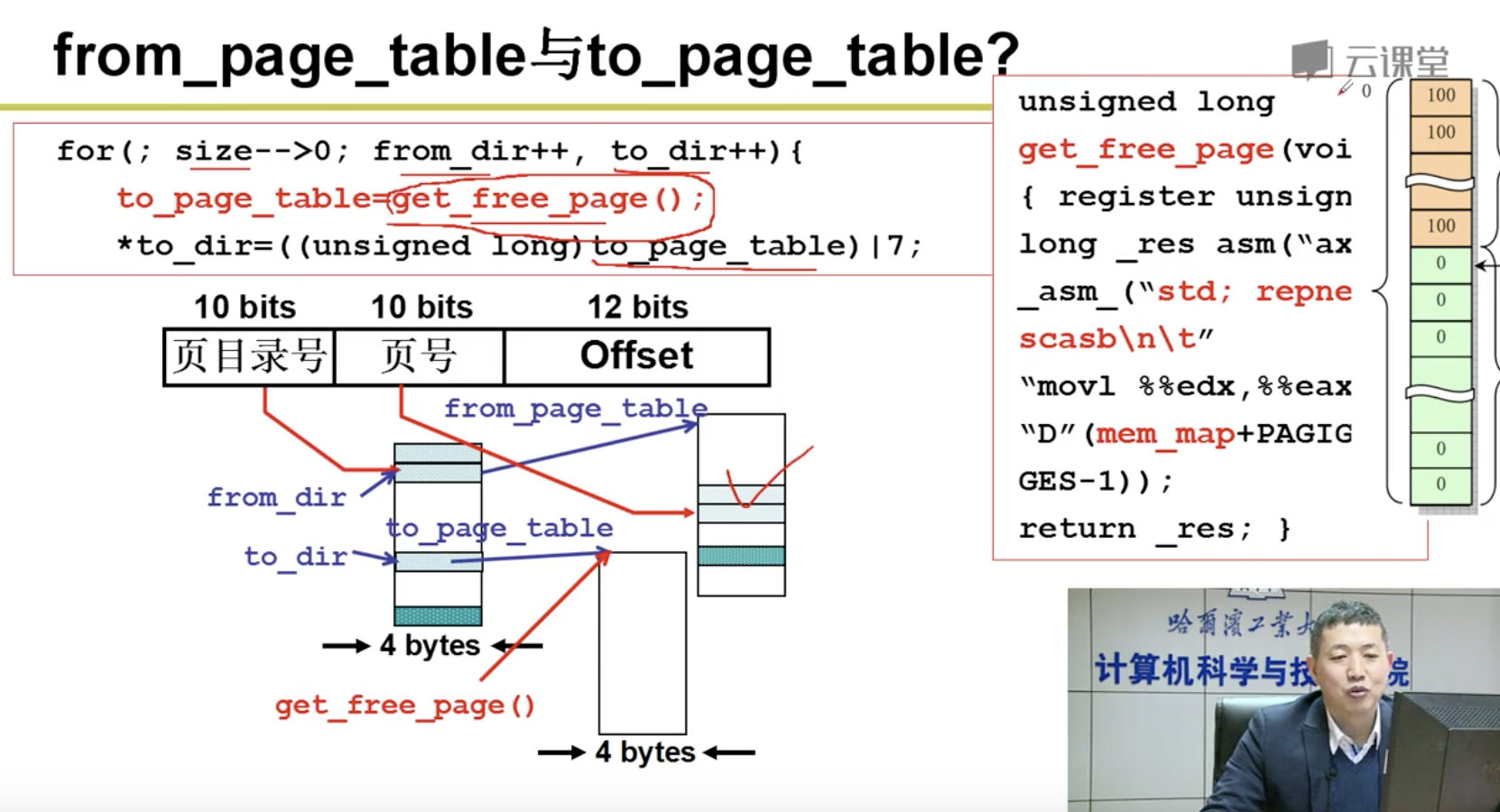
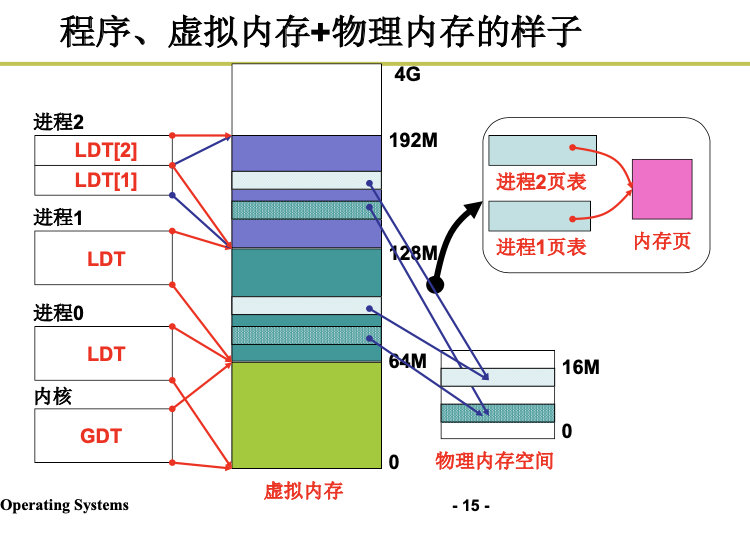
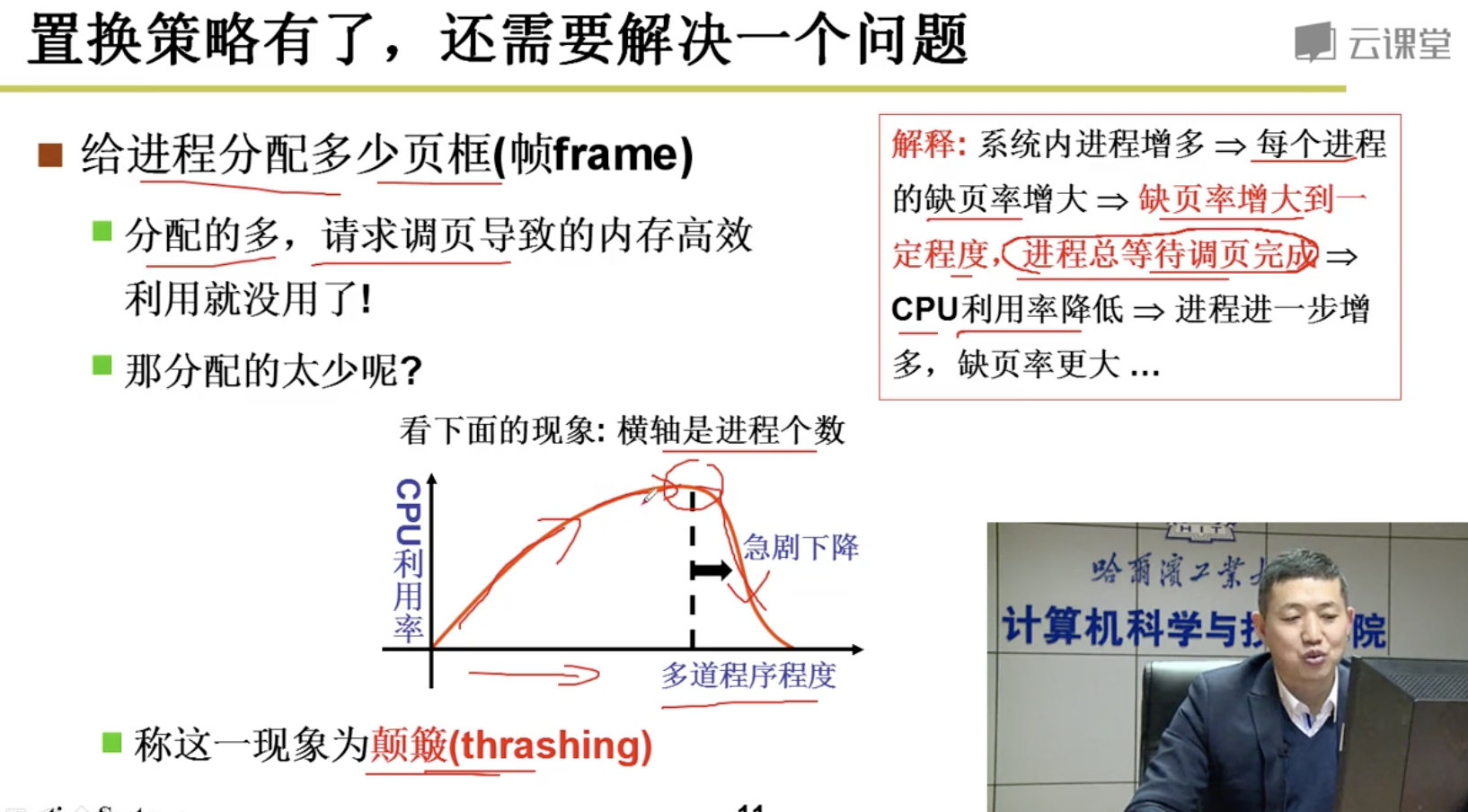
3.5 内存换入-请求调页
Swap in


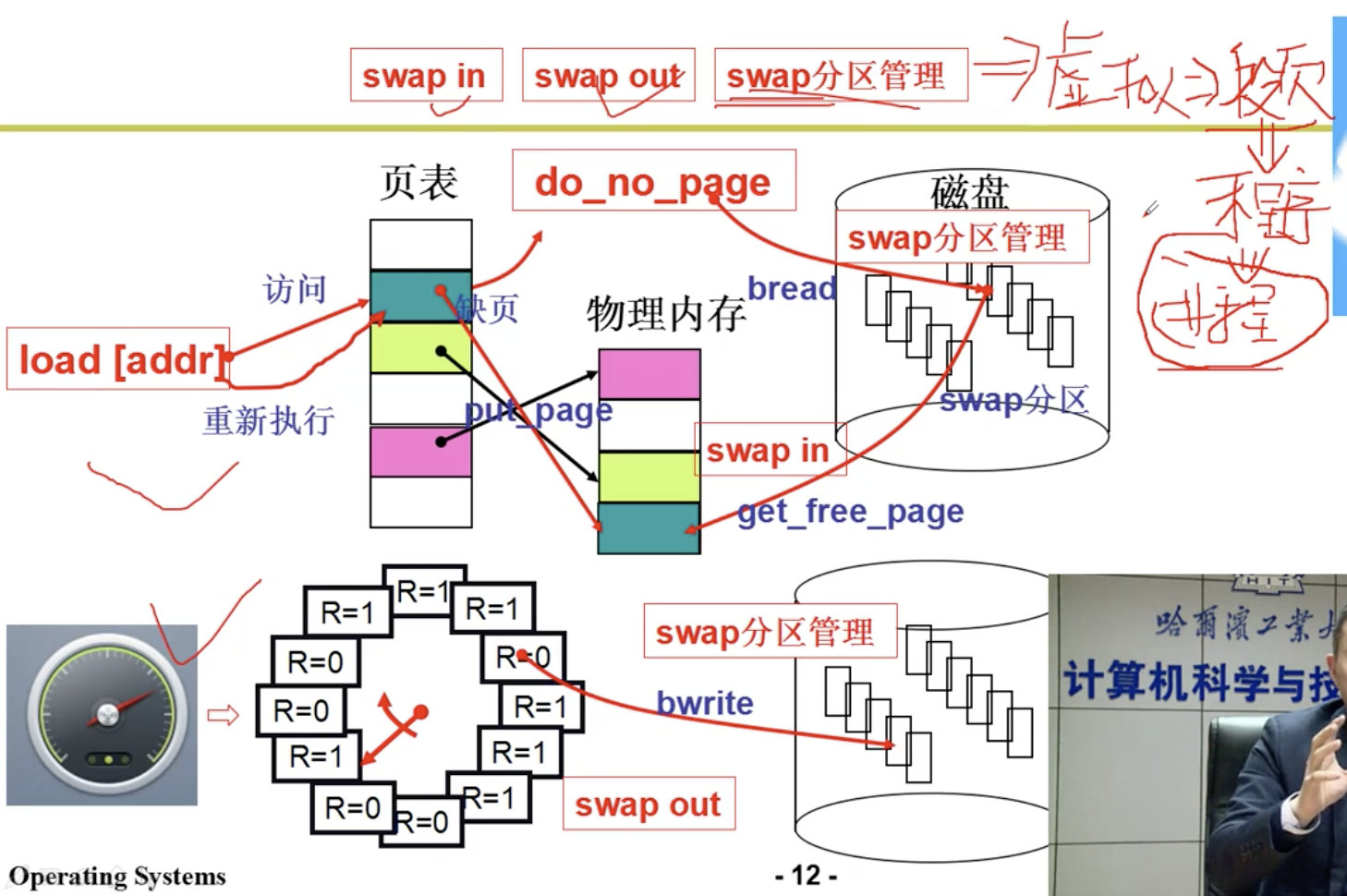
3.6 内存换出
Swap out
各种置换算法没有赘述。
3.7 逻辑地址VS线性地址VS物理地址
来自《Linux内核完全注释》5.3节。
Linux内存翻译的细节:
代码和数据在逻辑地址,线性地址(虚拟地址)和物理地址之间的对应关系。
为了有效地使用机器中的物理内存,在系统初始化阶段内存被划分成几个功 能区域 :
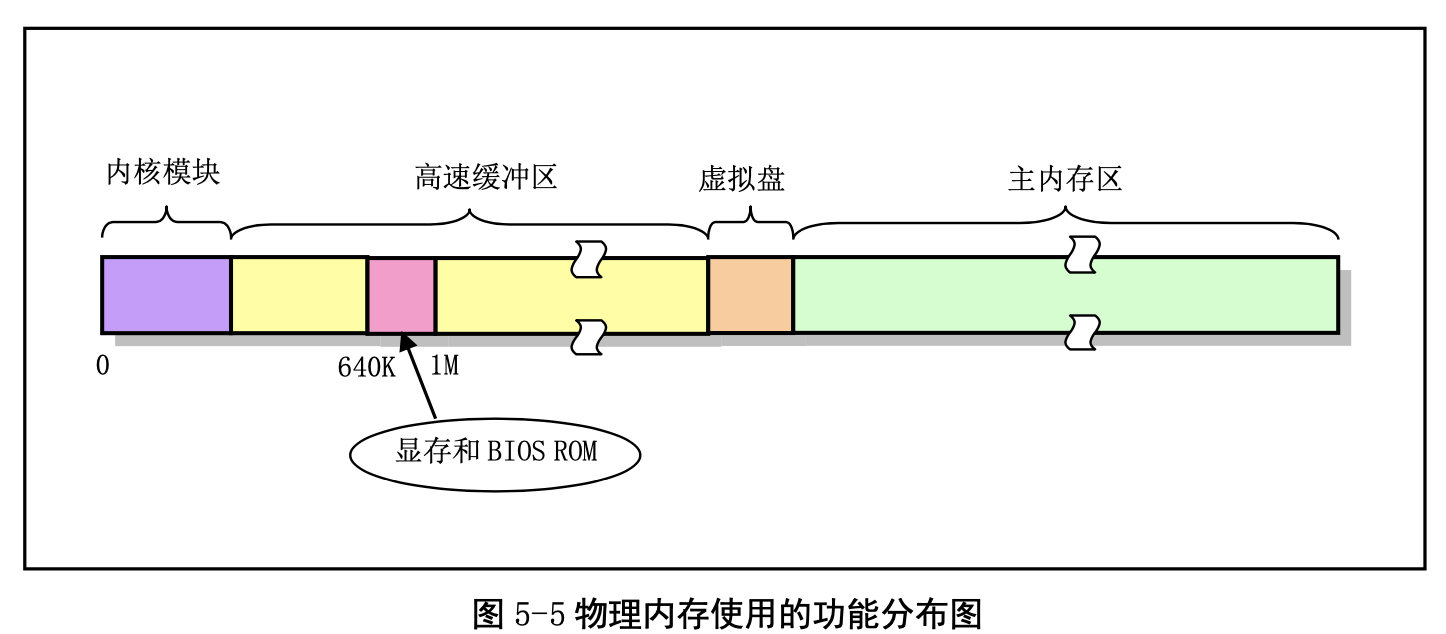
我们再来看内存地址空间的概念:
我们需要区分:进程的逻辑地址,CPU的线性地址,实际的物理内存。
-
逻辑地址:由 GDT 映射的全局地址空间和 由 LDT 映射的局部地址空间组成。由程序产生的与段相关的偏移地址部分。所以程序员可以使用的逻辑地址空间是4G。
- 线性地址(Linear Address)是逻辑地址到物理地址变换之间的中间层,是处理器可寻址的内存空间 (称为线性地址空间)中的地址。 32位的为4G。
- 物理地址(Physical Address)是指出现在 CPU 外部地址总线上的寻址物理内存的地址信号,是地址变换的最终结果地址。
在 Linux 0.12 内核中,给每个程序(进程)都划分了总容量为 64MB 的虚拟内存空间。因此程序的逻辑地址范围是 0x0000000 到 0x4000000。虚拟内存面向用户:好像给用户提供了一个很大的内存,提供一个假象。面向计算机,使用分页机制,把虚拟地址映射到物理内存,加快了读取的速度。
下面我们来看下内存分段机制:
在内存分段系统中,一个程序的逻辑地址通过分段机制自动地映射(变换)到中间层的 4GB(2^32) 线性地址空间中。程序每次对内存的引用都是对内存段中内存的引用。当程序引用一个内存地址时,通 过把相应的段基址加到程序员看得见的逻辑地址上就形成了一个对应的线性地址。
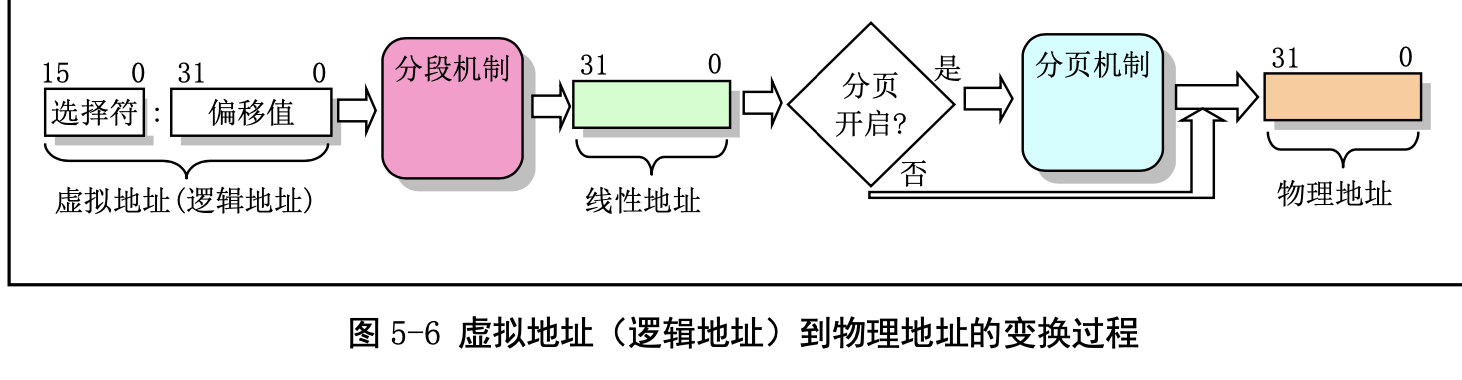
CPU 进行地址变换(映射)的主要目的是为了解决虚拟内存空间到物理内存空间的映射问题。虚拟内存空间的含义是指一种利用二级或外部存储空间,使程序能不受实际物理内存量限制而使用内存的一种方法。通常虚拟内存空间要比实际物理内存量大得多。
那么虚拟存储管理是怎样实现的呢?首先,当一个程序需要使用 一块不存在的内存时(也即在内存页表项中已标出相应内存页面不在内存中),CPU 就需要一种方法来 得知这个情况。这是通过 80386 的页错误异常中断来实现的。当一个进程引用一个不存在页面中的内存 地址时,就会触发 CPU 产生页出错异常中断,并把引起中断的线性地址放到 CR2 控制寄存器中。因此 处理该中断的过程就可以知道发生页异常的确切地址,从而可以把进程要求的页面从二级存储空间(比 如硬盘上)加载到物理内存中。如果此时物理内存已经被全部占用,那么可以借助二级存储空间的一部 分作为交换缓冲区(Swapper)把内存中暂时不使用的页面交换到二级缓冲区中,然后把要求的页面调入 内存中。这也就是内存管理的缺页加载机制,在 Linux 0.12 内核中是在程序 mm/memory.c 中实现。
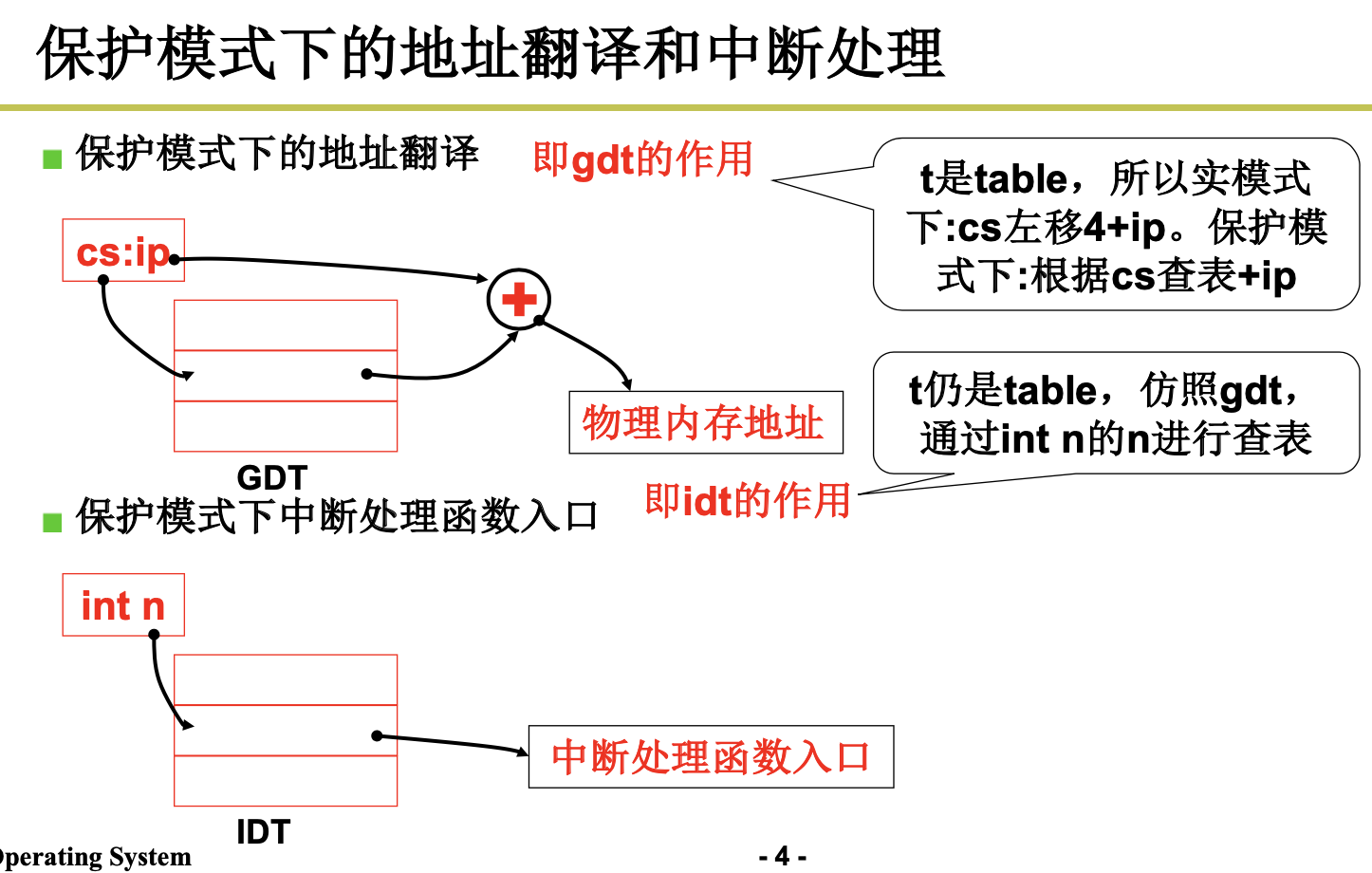
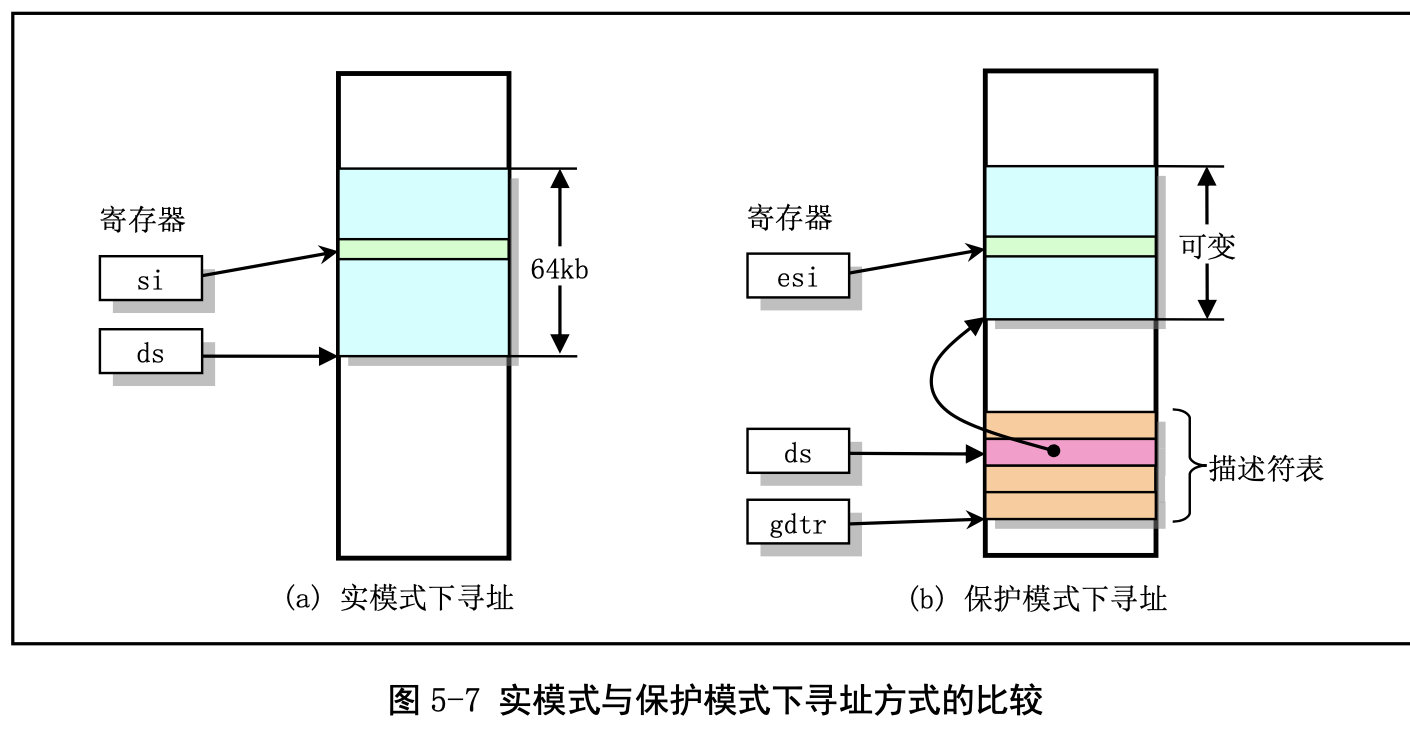
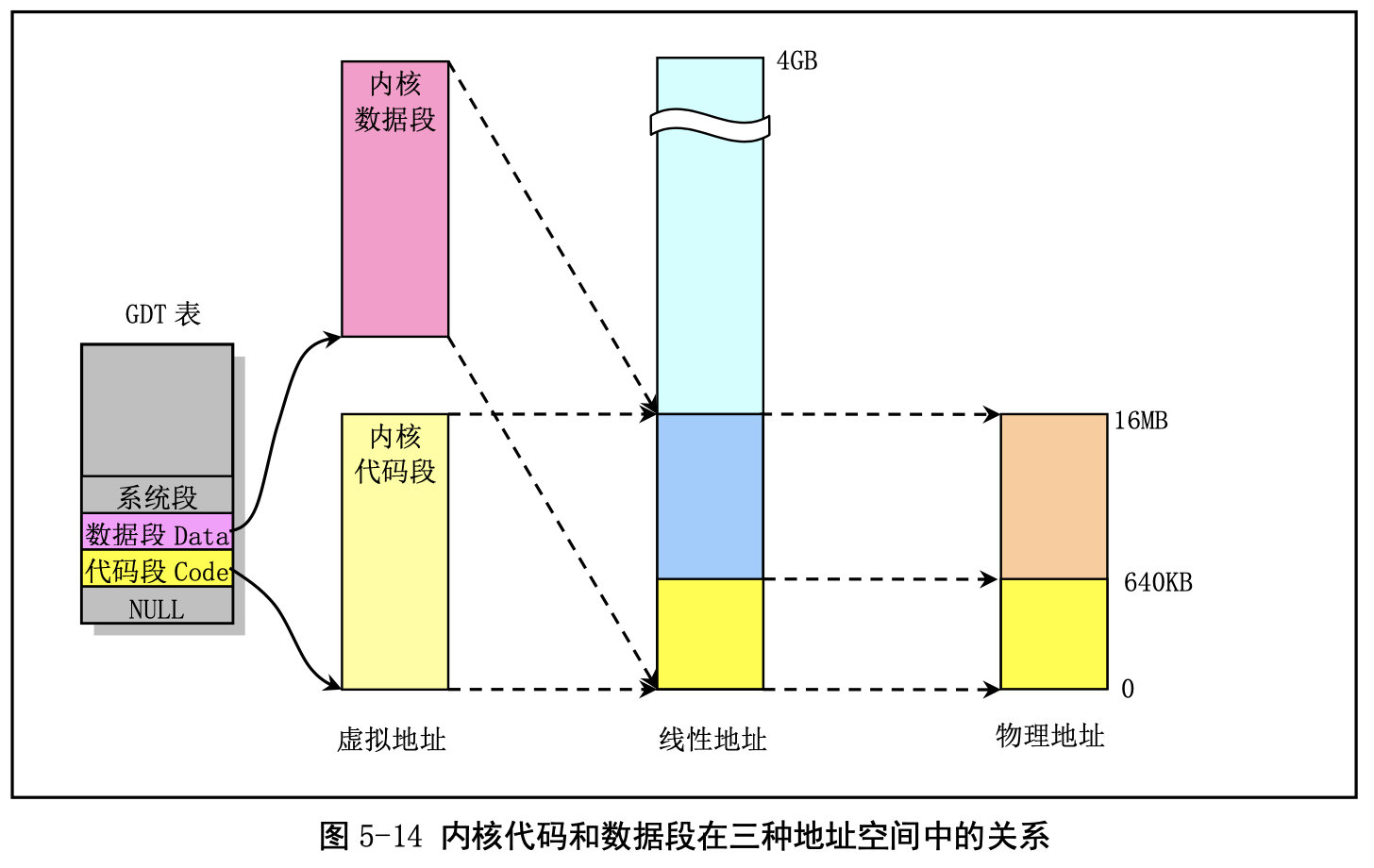
在实模式下,寻址一个内存地址主要是使用段和偏移值,段值被存放在段寄存器中(例如 ds),并 且段的长度被固定为 64KB。段内偏移地址存放在任意一个可用于寻址的寄存器中(例如 si)。因此,根
据段寄存器和偏移寄存器中的值,就可以算出实际指向的内存地址,见图 5-7 (a)所示。 而在保护模式运行方式下,段寄存器中存放的不再是被寻址段的基地址,而是一个段描述符表 (Segment Descriptor Table)中某一描述符项在表中的索引值。索引值指定的段描述符项中含有需要寻址 的内存段的基地址、段的长度值和段的访问特权级别等信息。寻址的内存位置是由该段描述符项中指定 的段基地址值与一个段内偏移值组合而成。段的长度可变,由描述符中的内容指定。可见,和实模式下 的寻址相比,段寄存器值换成了段描述符表中相应段描述符的索引值以及段表选择位和特权级,称为段 选择符(Segment Selector),但偏移值还是使用了原实模式下的概念。这样,在保护模式下寻址一个内 存地址就需要比实模式下多一道手续,也即需要使用段描述符表。这是由于在保护模式下访问一个内存 段需要的信息比较多,而一个 16 位的段寄存器放不下这么多内容。示意图见图 5-7 (b)所示。注意,如果 你不在一个段描述符中定义一个内存线性地址空间区域,那么该地址区域就完全不能被寻址,CPU 将拒 绝访问该地址区域。
每个描述符占用 8 个字节,其中含有所描述段在线性地址空间中的起始地址(基址)、段的长度、段 的类型(例如代码段和数据段)、段的特权级别和其他一些信息。一个段可以定义的最大长度是 4GB。
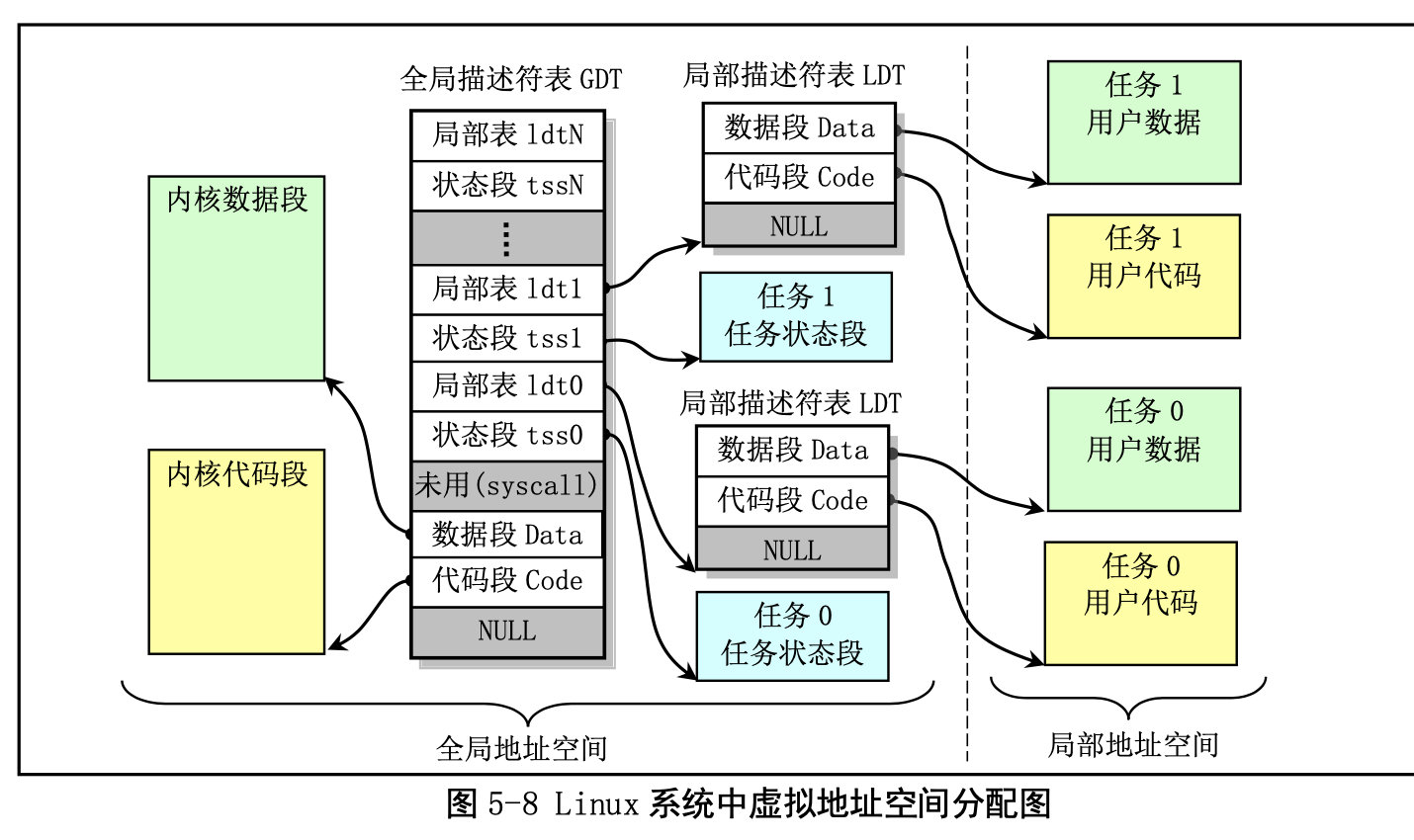
保存描述符项的描述符表有 3 种类型,每种用于不同目的。全局描述符表 GDT(Global Descriptor Table)是主要的基本描述符表,该表可被所有程序用于引用访问一个内存段。中断描述符表 IDT(Interrupt Descriptor Table)保存有定义中断或异常处理过程的段描述符。IDT 表直接替代了 8086 系统中的中断向 量表。为了能在 80X86 保护模式下正常运行,我们必须为 CPU 定义一个 GDT 表和一个 IDT 表。最后一 种类型的表是局部描述符表 LDT(Local Descriptor Table)。该表应用于多任务系统中,通常每个任务使 用一个 LDT 表。作为对 GDT 表的扩充,每个 LDT 表为对应任务提供了更多的可用描述符项,因而也为 每个任务提供了可寻址内存空间的范围。这些表可以保存在线性地址空间的任何地方。为了让 CPU 能定 位 GDT 表、IDT 表和当前的 LDT 表,需要为 CPU 分别设置 GDTR、IDTR 和 LDTR 三个特殊寄存器。 这些寄存器中将存储对应表的 32 位线性基地址和表的限长字节值。表限长值是表的长度值-1。
当 CPU 要寻址一个段时,就会使用 16 位的段寄存器中的选择符来定位一个段描述符。在 80X86 CPU 中,段寄存器中的值右移 3 位即是描述符表中一个描述符的索引值。13 位的索引值最多可定位 8192 (0–8191)个的描述符项。选择符中位 2(TI)用来指定使用哪个表。若该位是 0 则选择符指定的是 GDT 表中的描述符,否则是 LDT 表中的描述符。 每个程序都可有若干个内存段组成。程序的逻辑地址(或称为虚拟地址)即是用于寻址这些段和段
中具体地址位置。在 Linux 0.12 中,程序逻辑地址到线性地址的变换过程使用了 CPU 的全局段描述符表 GDT 和局部段描述符表 LDT。由 GDT 映射的地址空间称为全局地址空间,由 LDT 映射的地址空间则称 为局部地址空间,而这两者构成了虚拟地址的空间。具体的使用方式见图 5-8 所示。
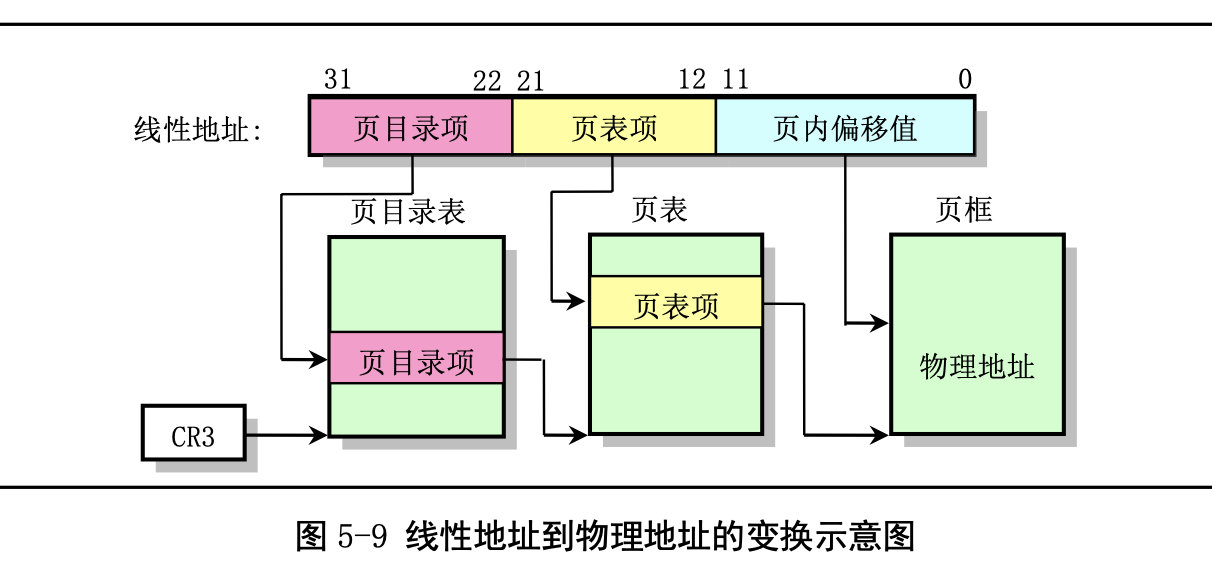
下面我们再来看下内存的分页管理:
内存分页管理机制的基本原理是将 CPU 整个线性内存区域划分成 4096 字节为 1 页的内存页面。
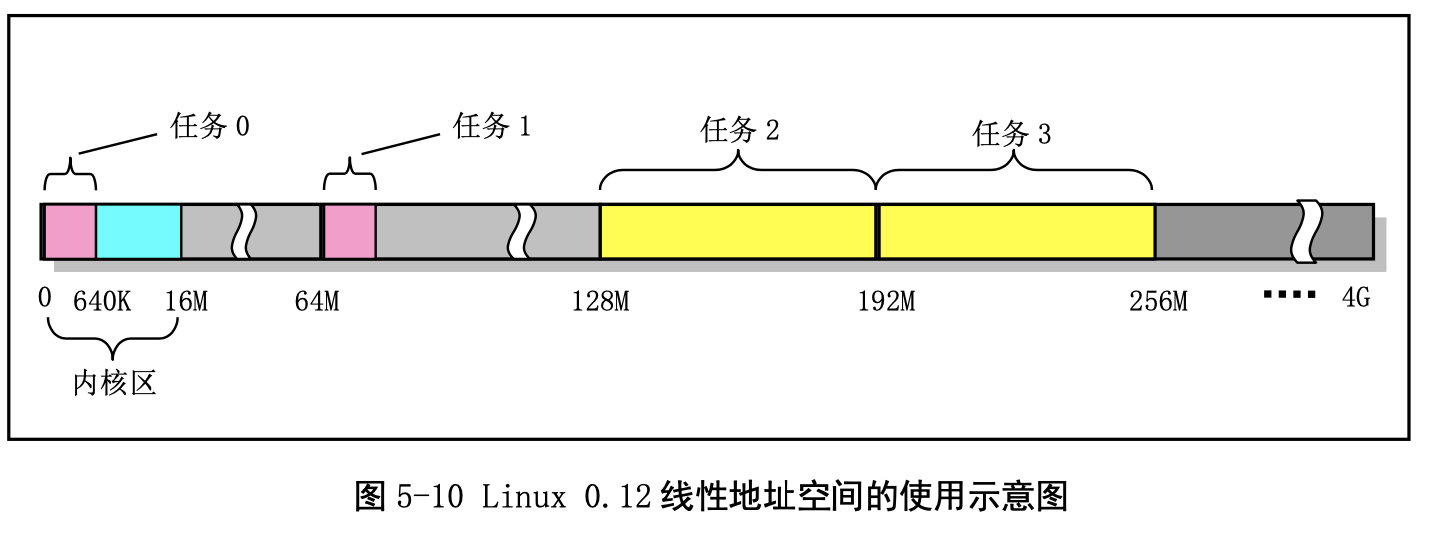
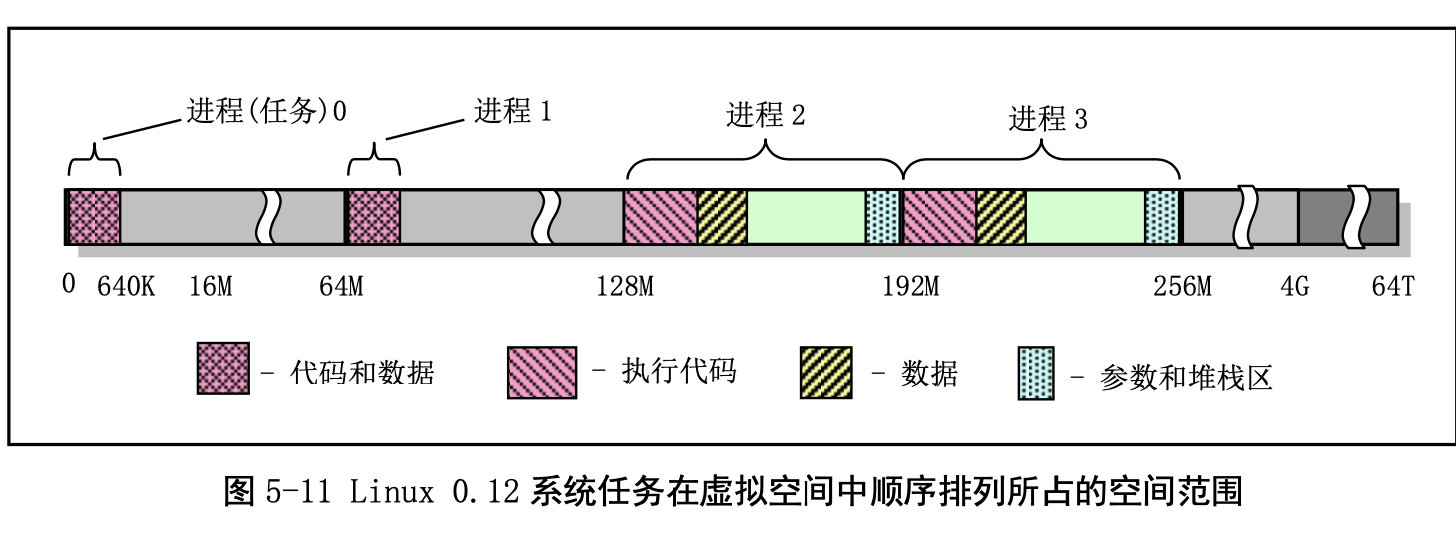
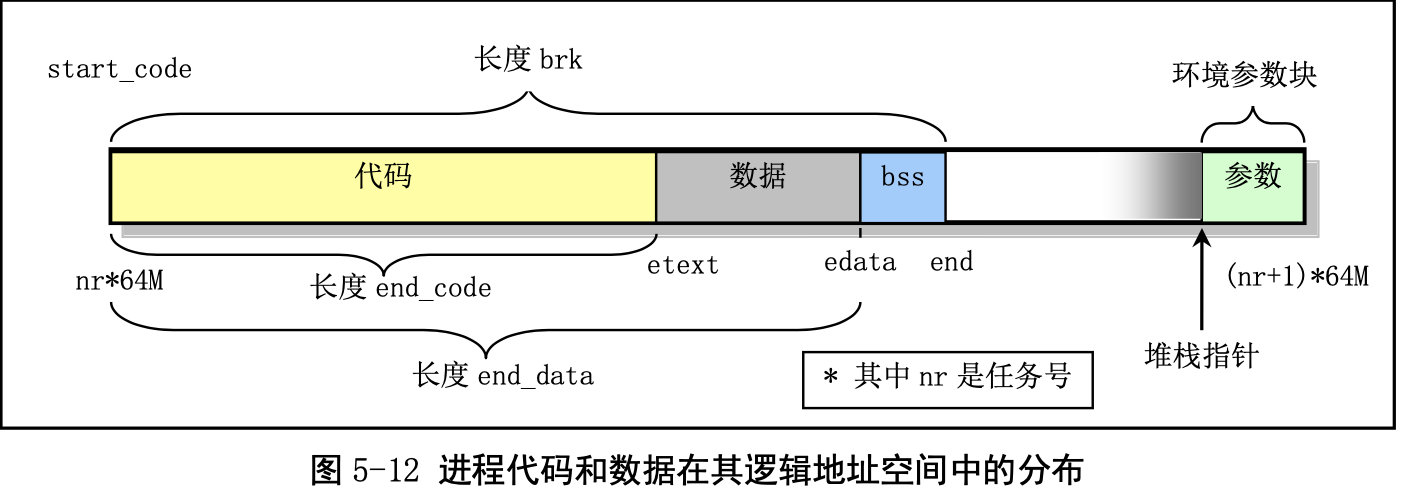
进程逻辑地址空间中代码段(Code Section)和数据段(Data Section)的概念与CPU 分段机制中的代码段和数据段不是同一个概念。CPU 分段机制中段的概念确定了在线性地址空间中一个 段的用途以及被执行或访问的约束和限制,每个段可以设置在 4GB 线性地址空间中的任何地方,它们可 以相互独立也可以完全重叠或部分重叠。而进程在其逻辑地址空间中的代码段和数据段则是指由编译器 在编译程序和操作系统在加载程序时规定的在进程逻辑空间中顺序排列的代码区域、初始化和未初始化 的数据区域以及堆栈区域。进程逻辑地址空间中代码段和数据段等结构形式见图所示。有关逻辑地址空 间的说明请参见内存管理一章内容。其中 nr 是任务号,start_code 是进程或任务在线性地址空间的起始 位置。其他变量均表示进程在逻辑空间中的值。
虚拟地址、线性地址和物理地址之间的关系:
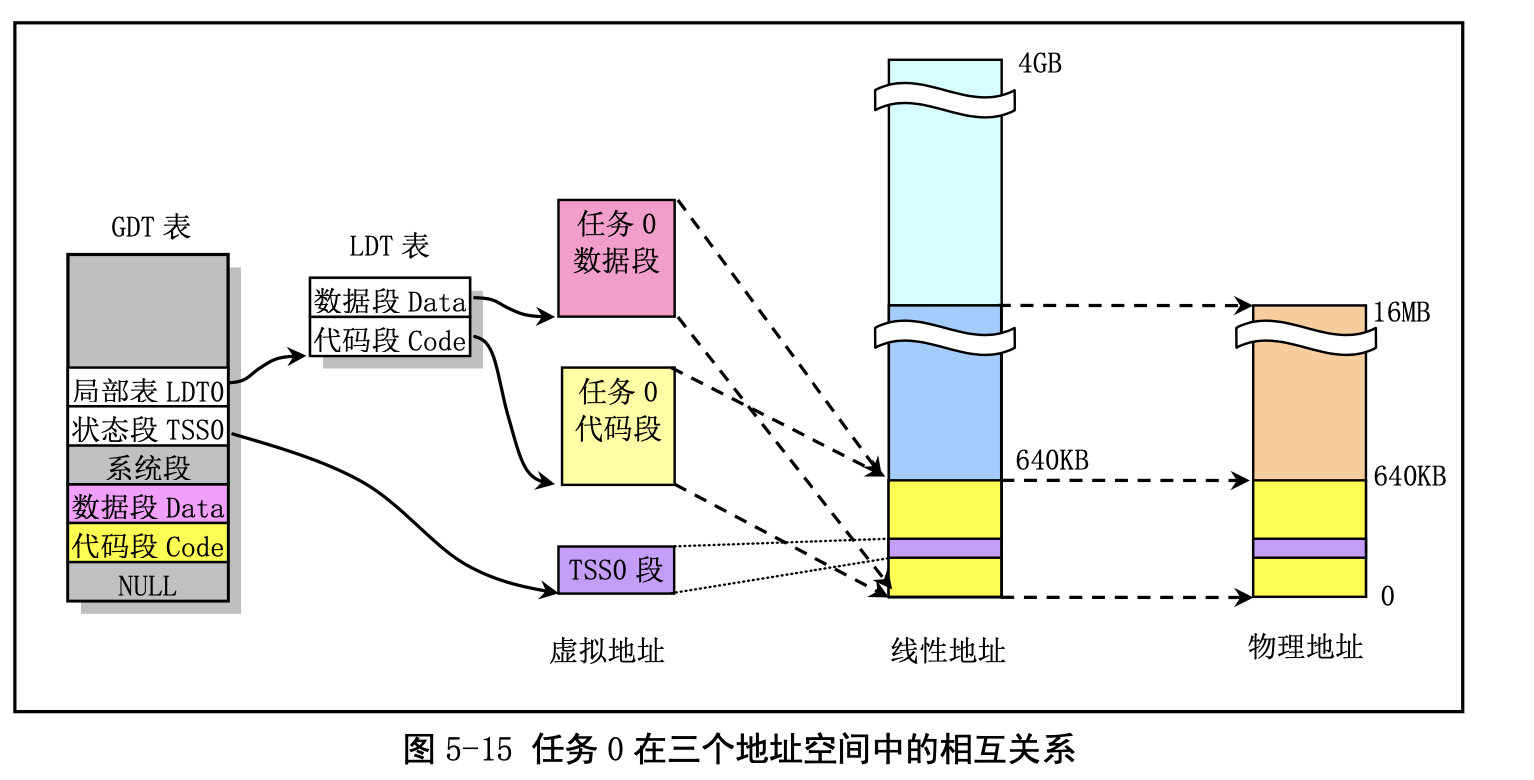
任务 0 的地址对应关系:
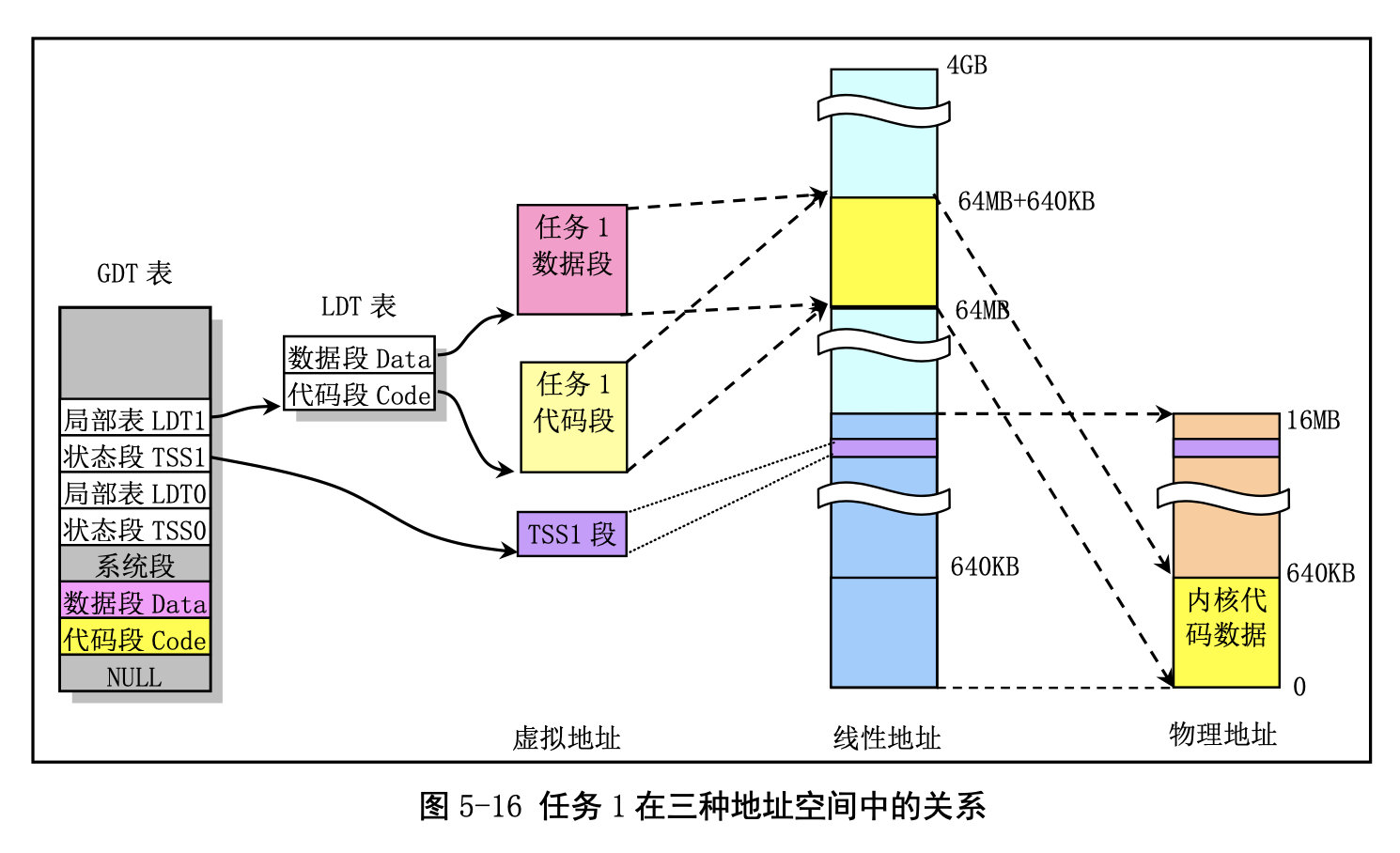
任务 1 的地址对应关系:
与任务 0 类似,任务 1 也是一个特殊的任务。它的代码也在内核代码区域中。与任务 0 不同的是在 线性地址空间中,系统在使用 fork()创建任务 1(init 进程)时为存放任务 1 的二级页表而在主内存区申 请了一页内存来存放,并复制了父进程(任务 0)的页目录和二级页表项。
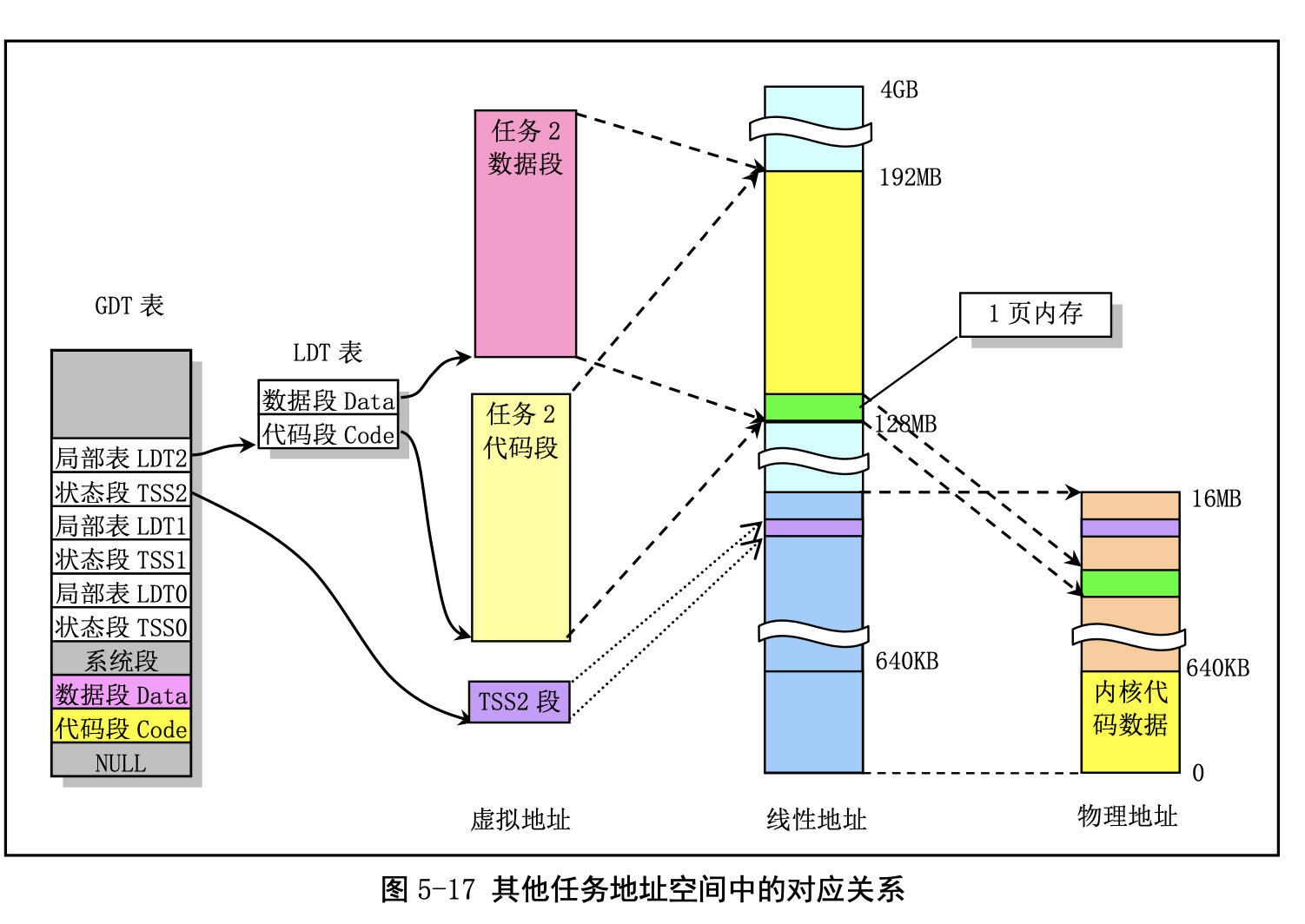
其他任务的地址对应关系:
4. 设备驱动与文件系统
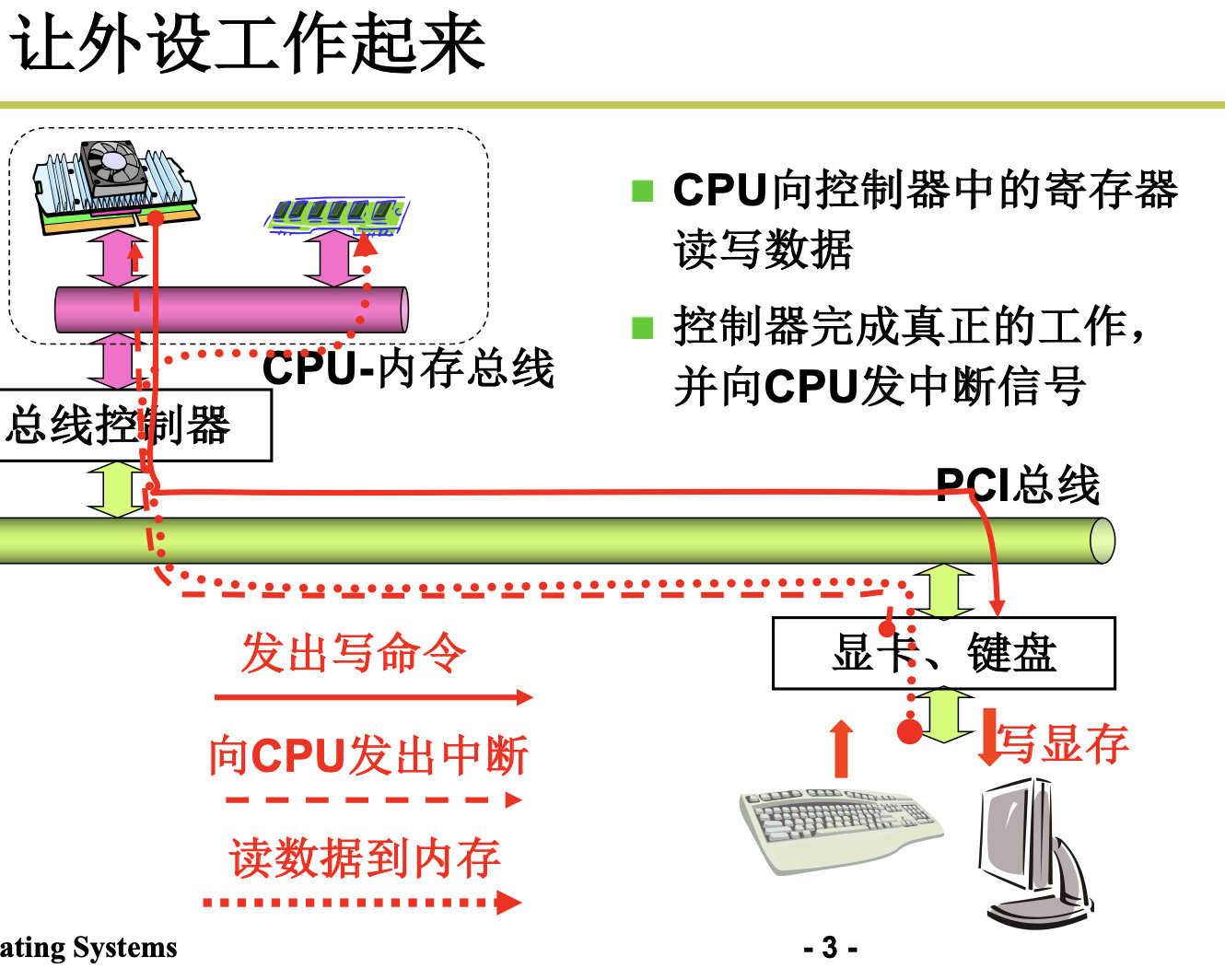
设备可以分为块设备(block device)和字符型设备(character device)。块型设备是一种可以以固定大小的数据块为单位进行寻址和访问的设备,例如硬盘设备和软盘设备。字符型设备是一种以字符流作为操作对象的设备,不能进行寻址操作。 例如打印机设备、网络接 口设备和终端设备。
4.1 终端设备的控制
4.1.1 IO与显示器
printf(Display)



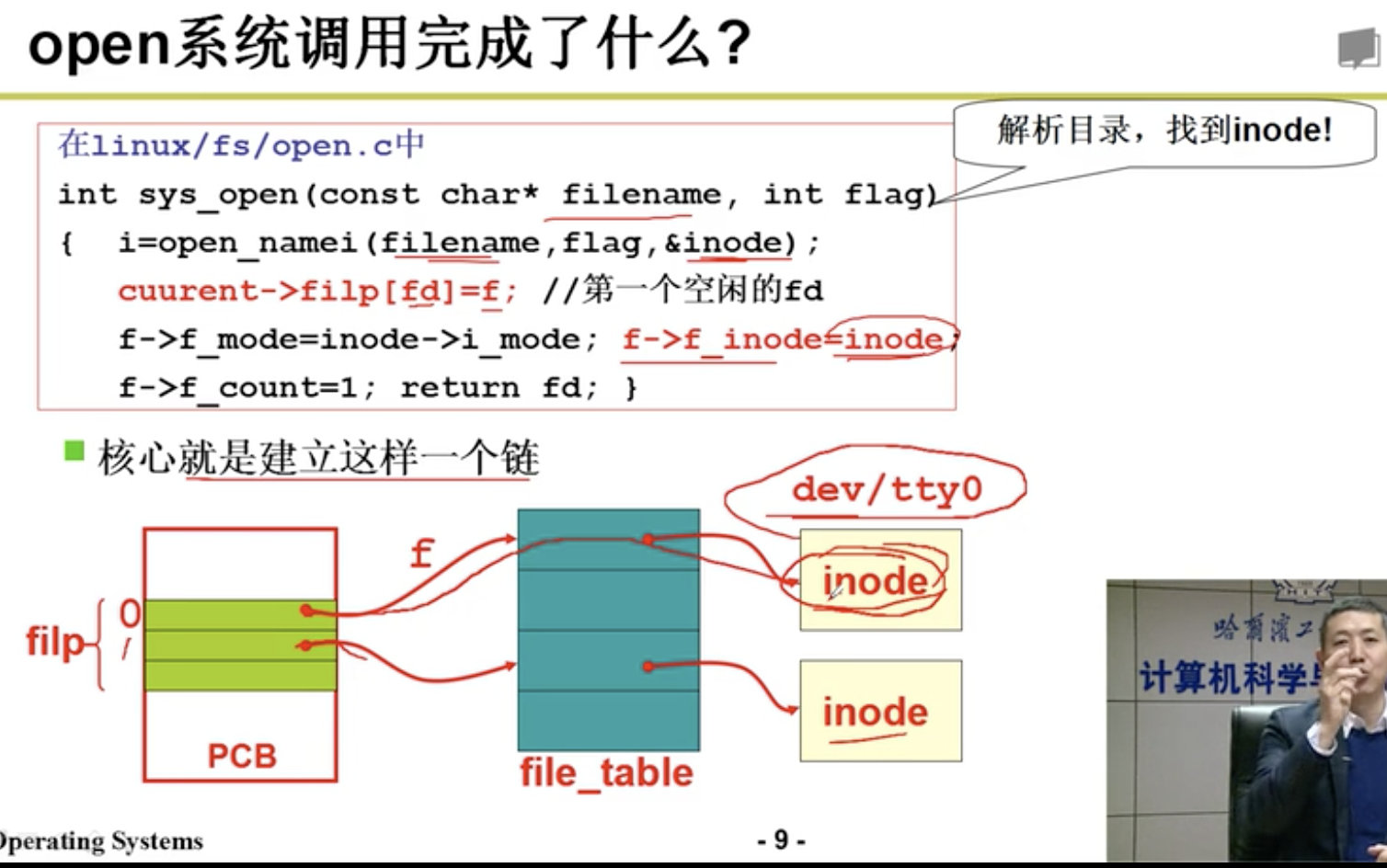




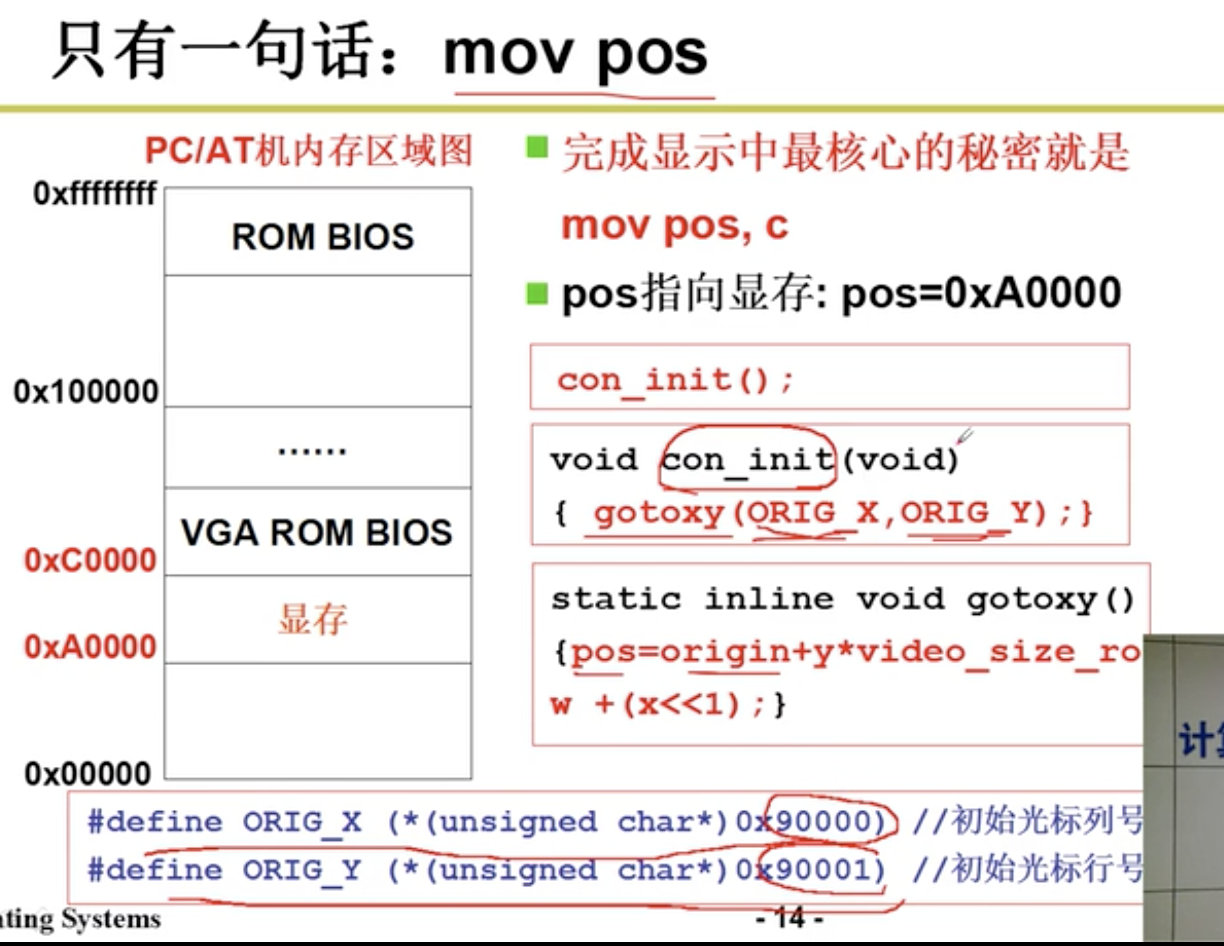
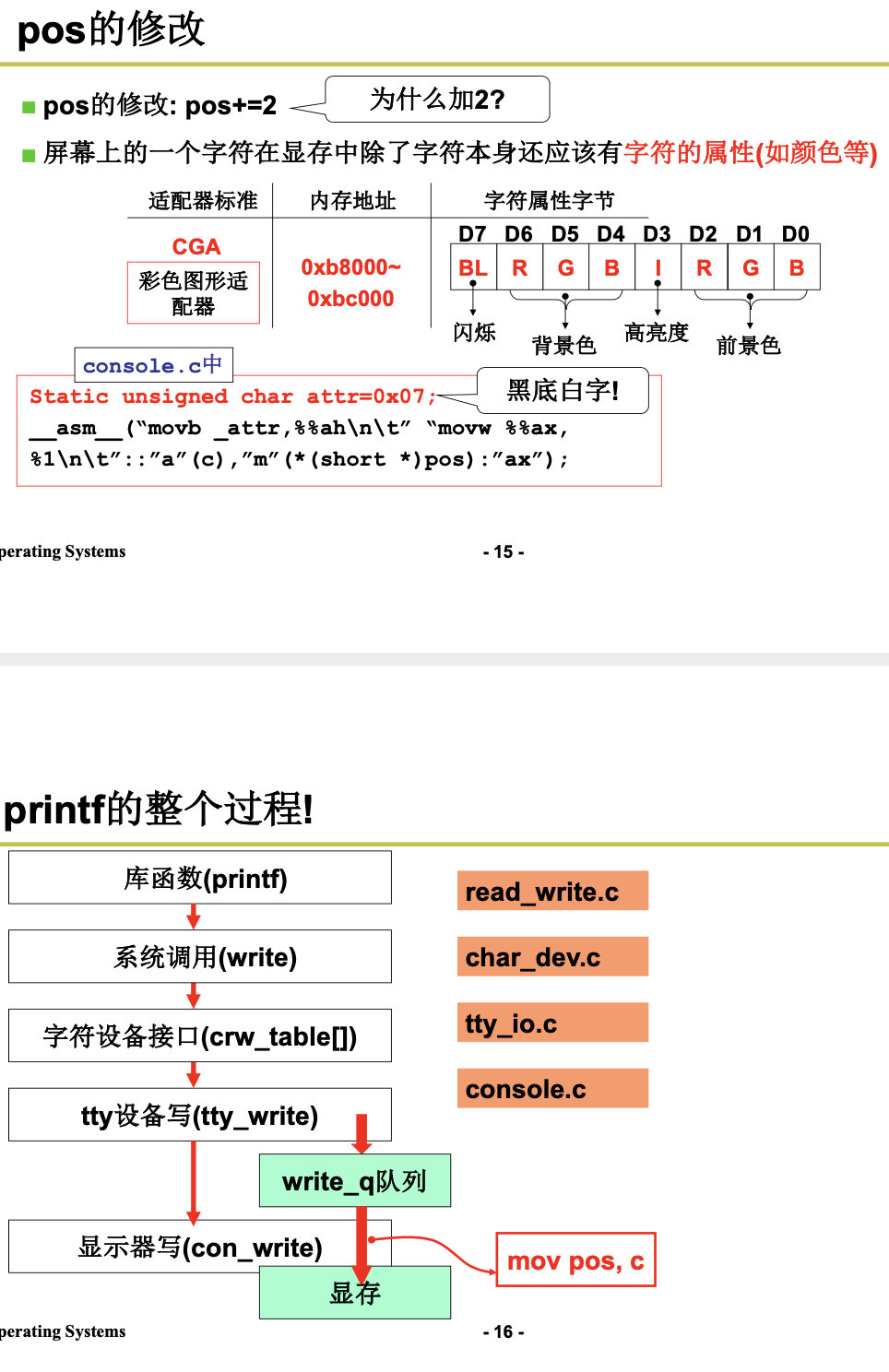
4.1.2 键盘
Keyboard ,终端设备包括显示器和键盘。



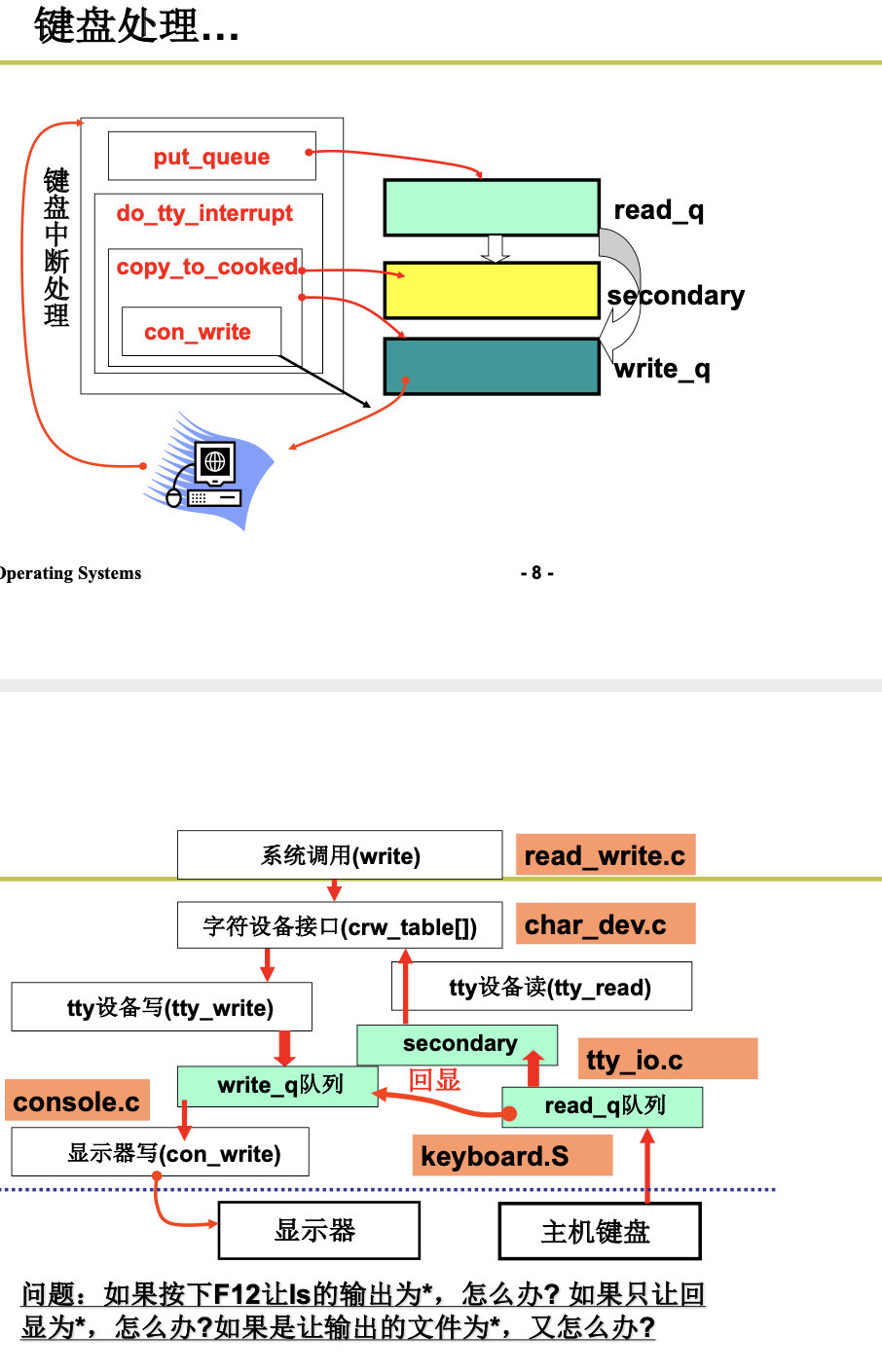
4.2 proc文件系统的实现
4.2.1 生磁盘的使用
Raw Disks
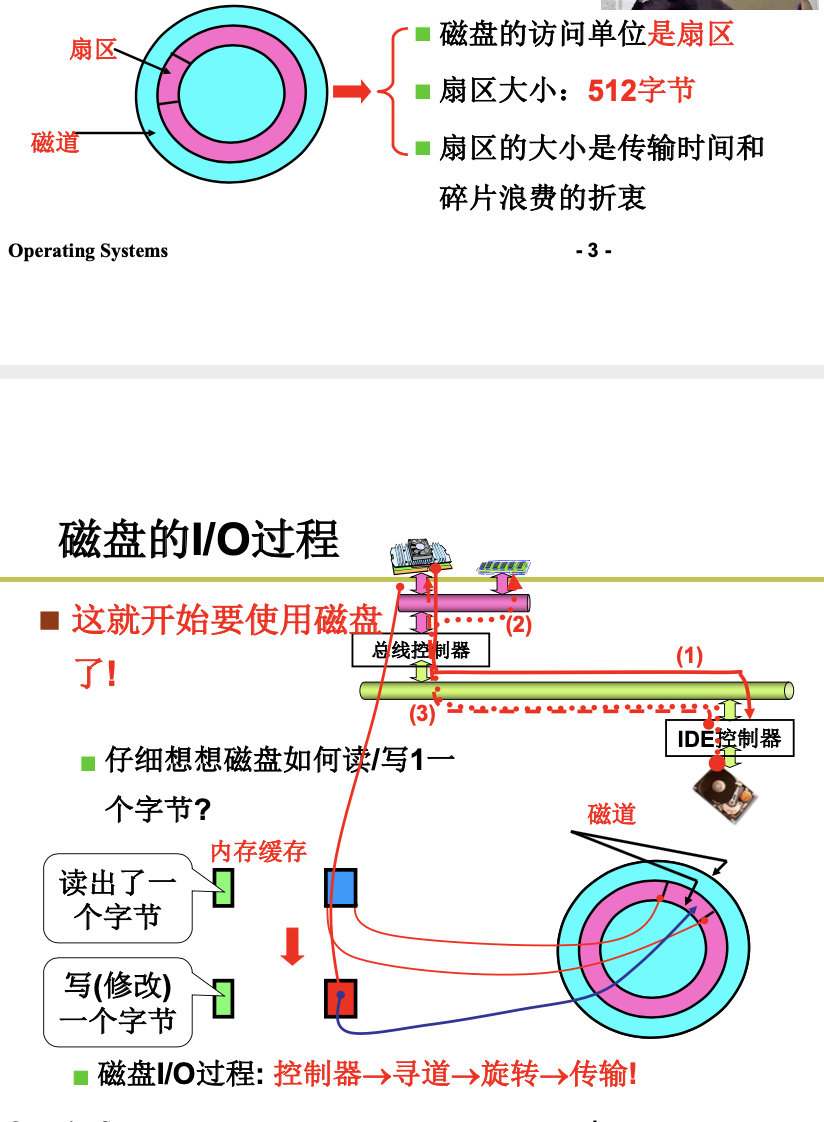

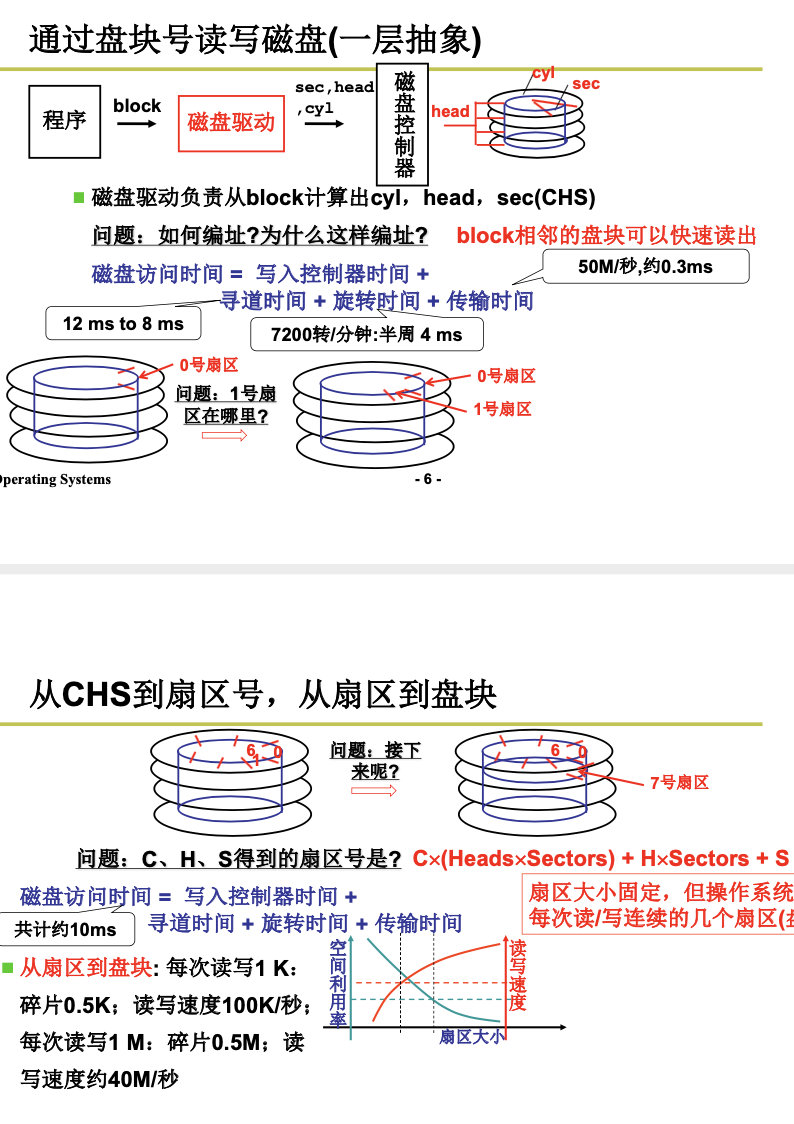

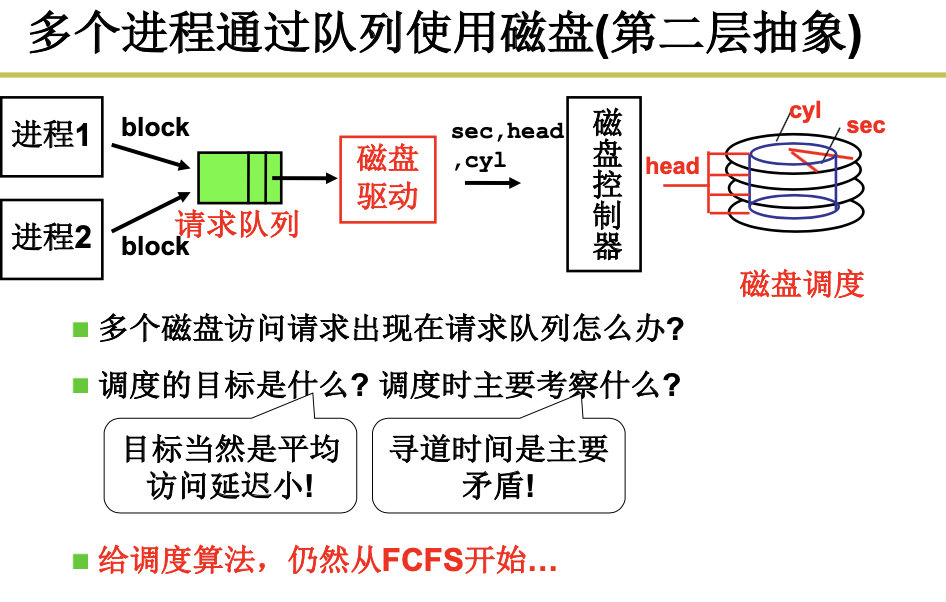

4.2.2 从生磁盘到文件
Files- cooked Disks
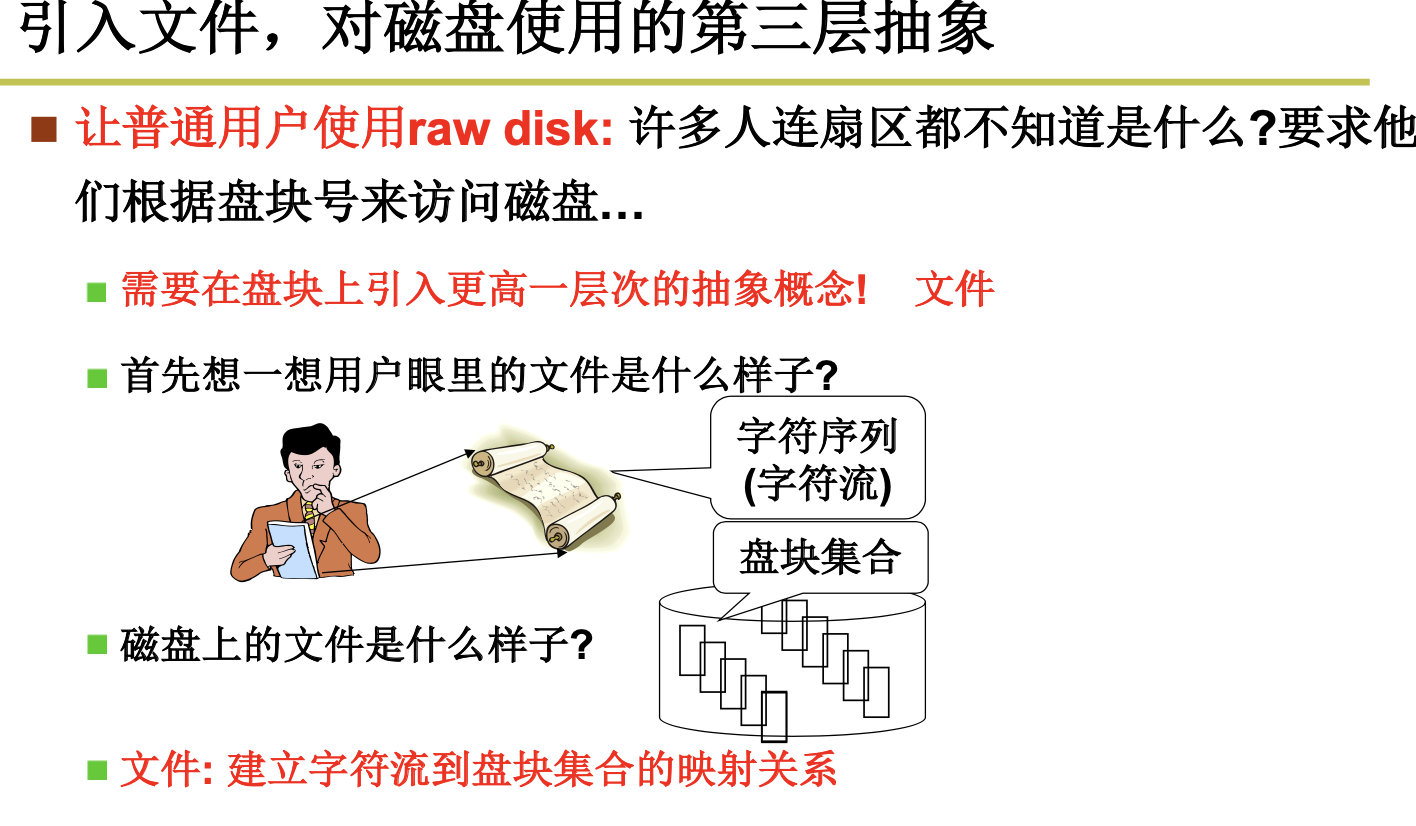
文件在磁盘中的存储分为3种,顺序存储,链式存储,和索引存储。
4.2.3 文件使用磁盘的实现
Files Implementation
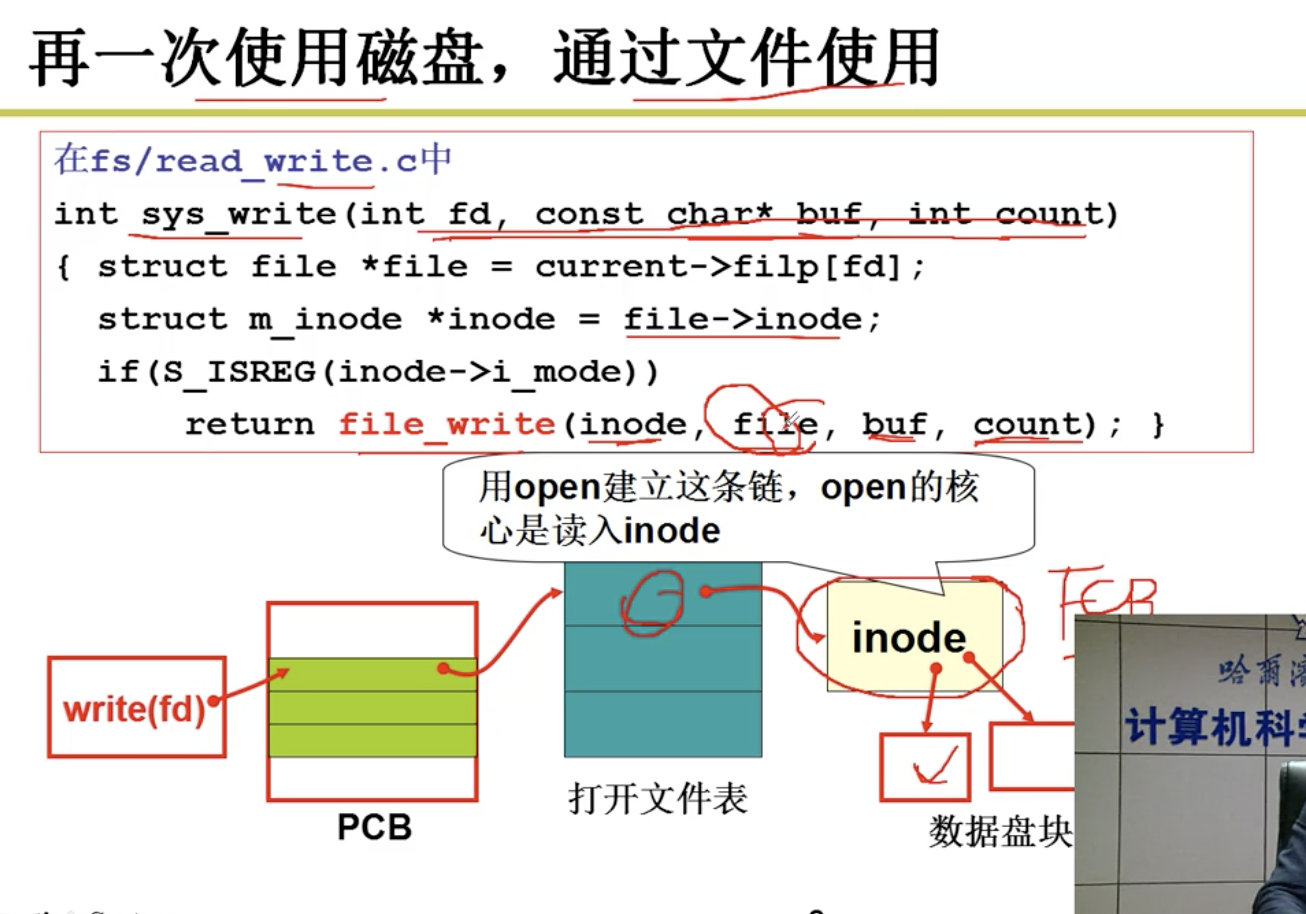
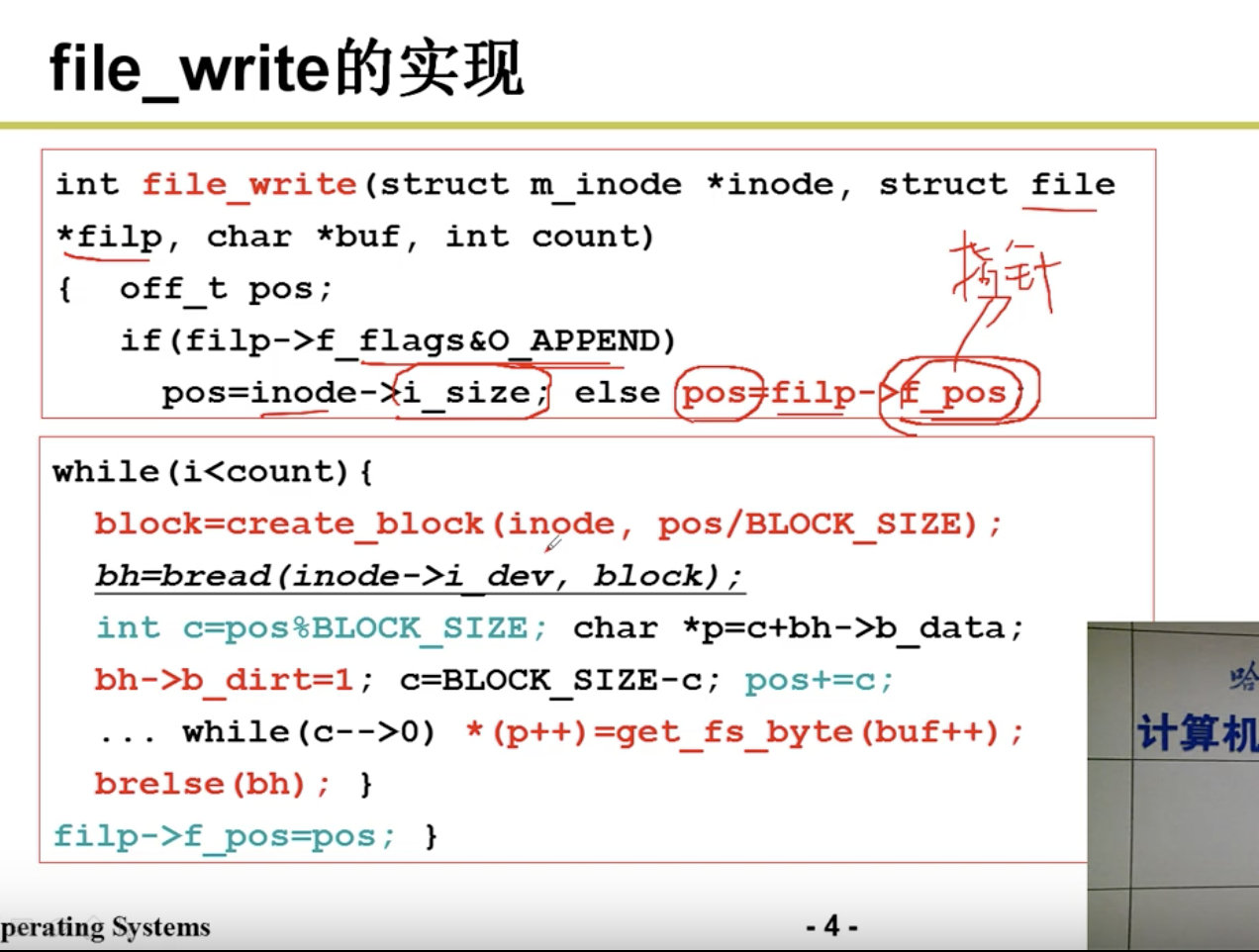
下一步是算出盘块号:
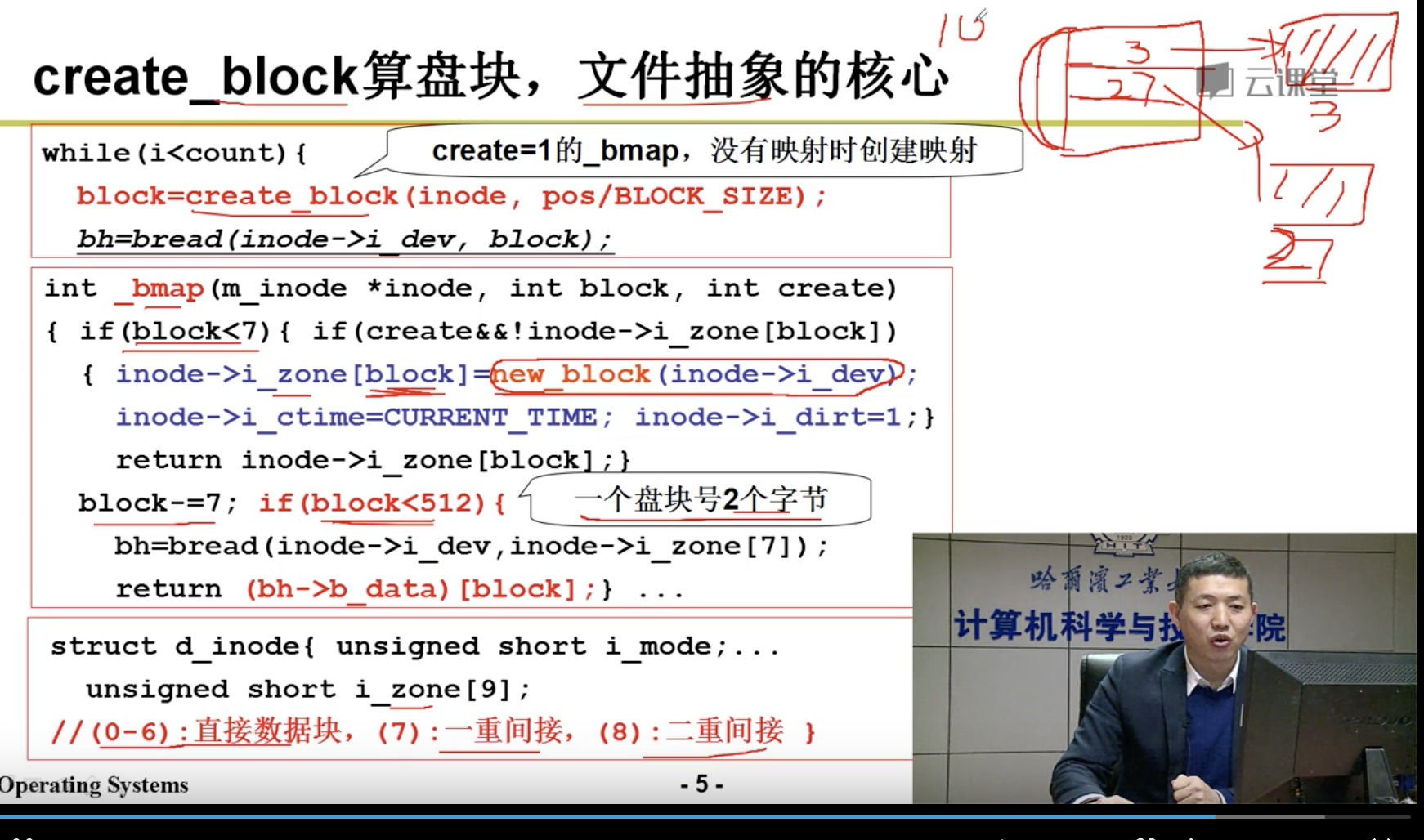

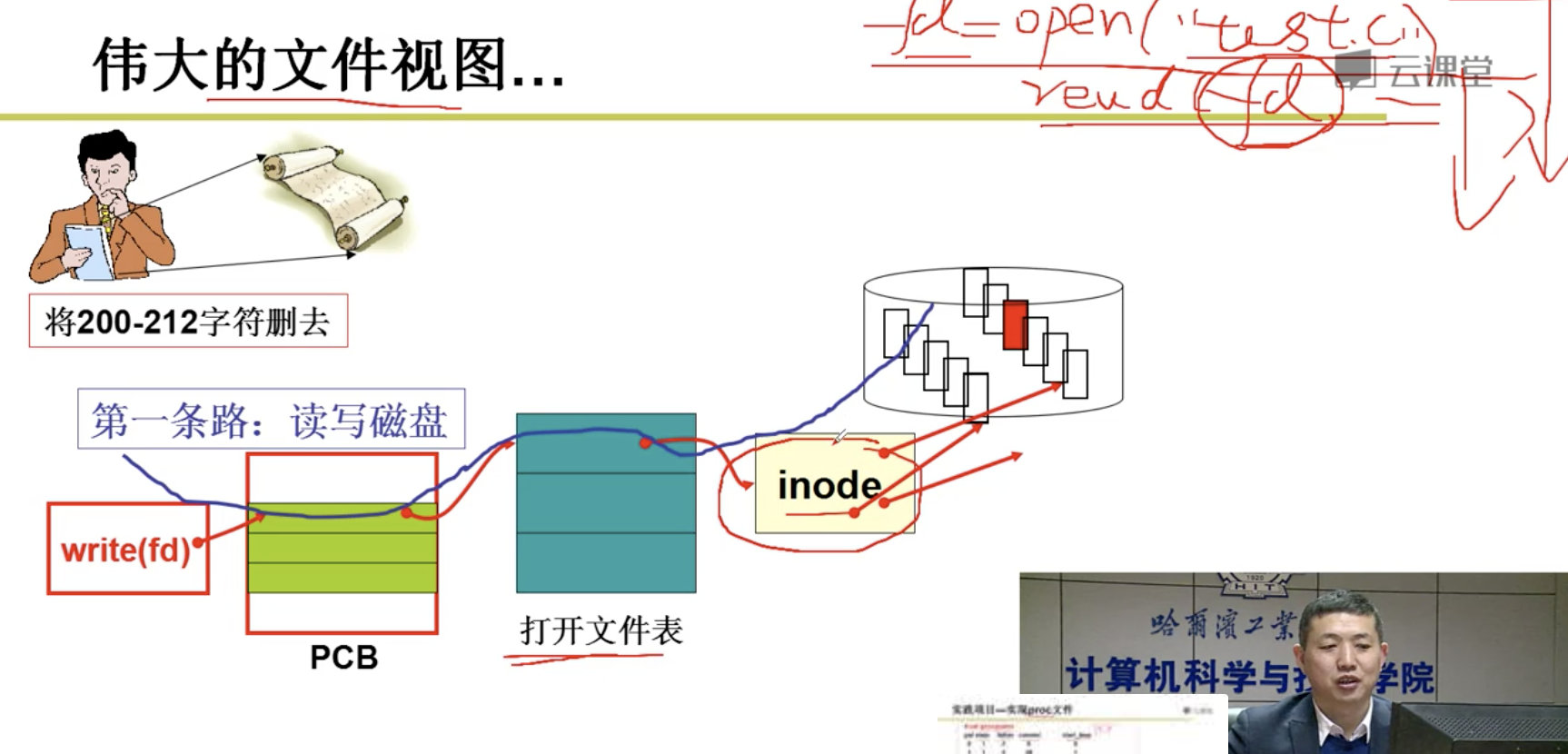
整个故事是从文件名找到inode,从inode找到盘块号,根据盘块号放到电梯队列,根据电梯队列中的盘块号算出CHS,然后使用out指令发送到磁盘控制器,磁盘控制器控制马达,电生磁,磁生电,形成数据。

4.2.4 目录与文件系统
File System
磁盘文件: 建立了字符流到盘块集合的映射关系。
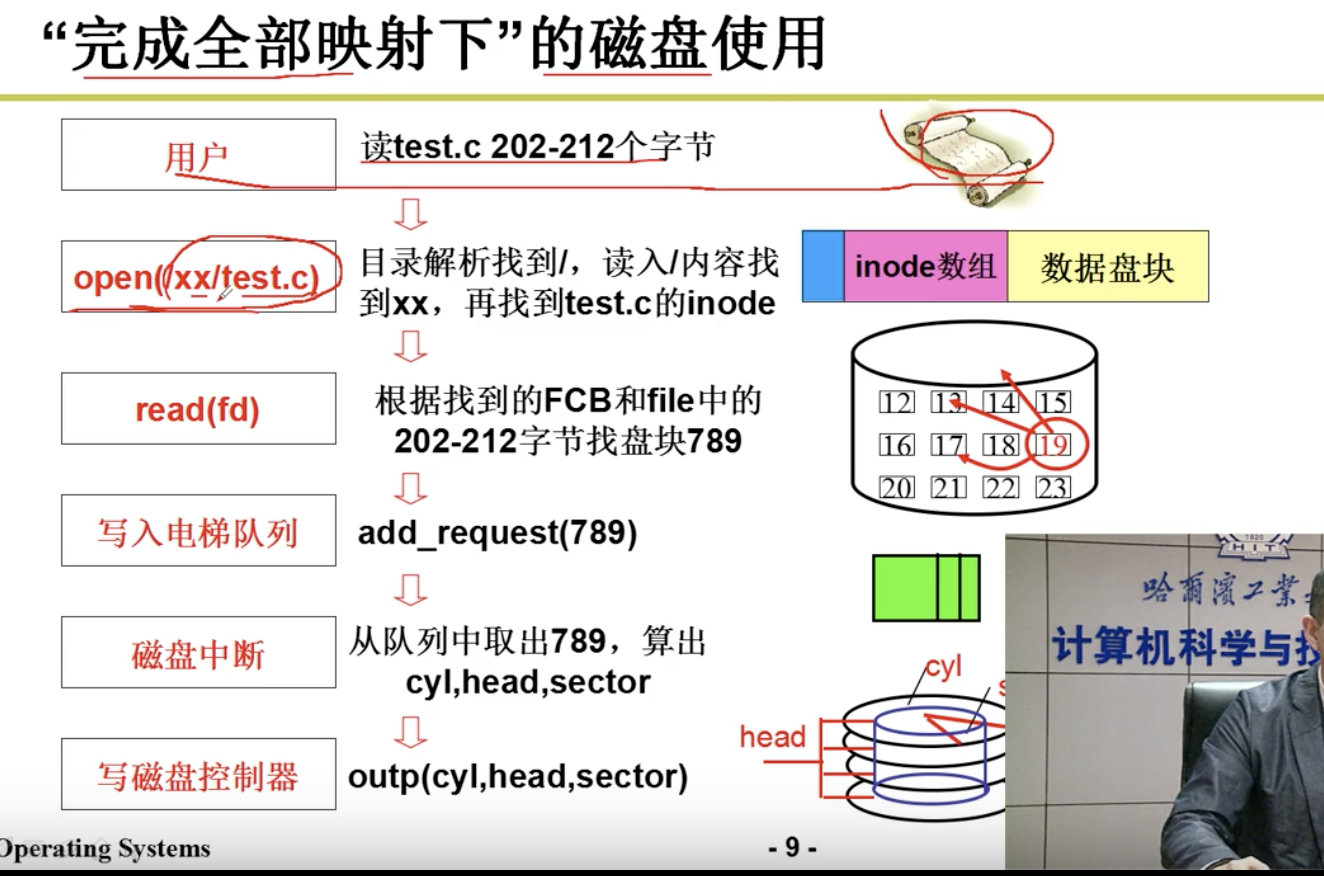
4.2.5 目录解析代码的实现
Directory Resolution
5. 总结