
1. 前言
之前在学习java的JVM的时候,总是傻傻的分不清堆,栈,数据区,代码区什么的,查了很多的资料,都是很零碎的,学的也很乱,其实现在才发现,这些都是编译原理里面的。
下面的内容我主要参考的是《程序员的自我修养,链接,装载与库》和《Links and Loaders》。
我没有按照实际的顺序,按照的书的顺序,方便以后的查找,只是摘录了现阶段比较重要的东西,像是语义分析之类的,直接省略了。动态链接的内容也是比较少,以后用到的时候,在来补充吧。
https://mp.weixin.qq.com/s/-BM7IGL2-_q9EY49OiIbYg 这篇文章也可以参考下。
2.静态链接
2.3目标文件
ELF,executable linkable format。动态链接库(.so)和静态链接库(.a)都是按照可执行文件格式存储。
目标文件.o。
目标文件按照段的方式来存储。
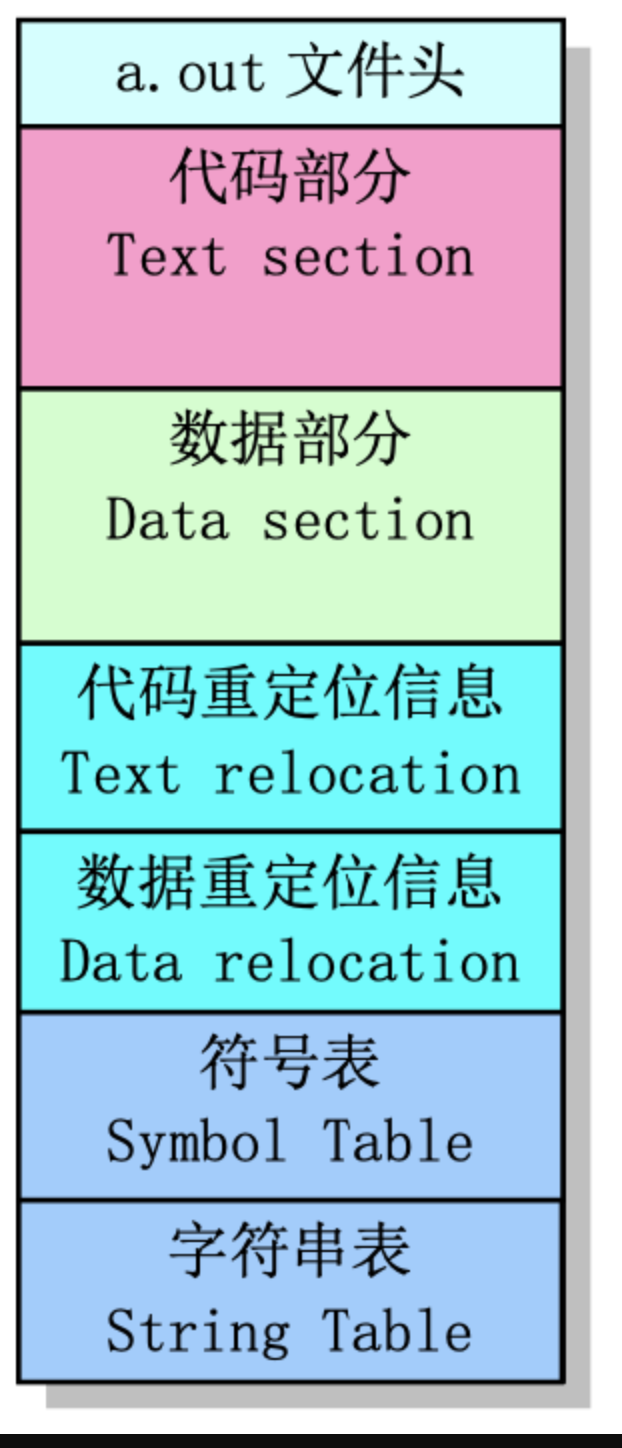
2.3.4 ELF文件结构描述
文件头,段表,重定位表,字符串表(段名,变量名),符号表。
-
执行头部分(exec header)。执行文件头部分。该部分中含有一些参数(exec 结构),是有关目标文件
的整体结构信息。例如代码和数据区的长度、未初始化数据区的长度、对应源程序文件名以及目标文 件创建时间等。内核使用这些参数把执行文件加载到内存中并执行,而链接程序(ld)使用这些参数 将一些模块文件组合成一个可执行文件。这是目标文件唯一必要的组成部分。
-
代码区(text segment)。由编译器或汇编器生成的二进制指令代码和数据信息,含有程序执行时被加 载到内存中的指令代码和相关数据。可以以只读形式被加载。
-
数据区(data segment)。由编译器或汇编器生成的二进制指令代码和数据信息,这部分含有已经初始 化过的数据,总是被加载到可读写的内存中。
-
代码重定位部分(text relocations)。这部分含有供链接程序使用的记录数据。在组合目标模块文件时 用于定位代码段中的指针或地址。当链接程序需要改变目标代码的地址时就需要修正和维护这些地方。
-
数据重定位部分(data relocations)。类似于代码重定位部分的作用,但是用于数据段中指针的重定位。
-
符号表部分(symbol table)。这部分同样含有供链接程序使用的记录数据。这些记录数据保存着模块 文件中定义的全局符号以及需要从其他模块文件中输入的符号,或者是由链接器定义的符号,用于在 模块文件之间对命名的变量和函数(符号)进行交叉引用。
-
字符串表部分(string table)。该部分含有与符号名相对应的字符串。用于调试程序调试目标代码,与
链接过程无关。这些信息可包含源程序代码和行号、局部符号以及数据结构描述信息等。
文件头的定义在 include/a.out.h ,
struct exec {
unsigned long a_magic; /* Use macros N_MAGIC, etc for access */
unsigned a_text; /* length of text, in bytes */
unsigned a_data; /* length of data, in bytes */
unsigned a_bss; /* length of uninitialized data area for file, in bytes */
unsigned a_syms; /* length of symbol table data in file, in bytes */
unsigned a_entry; /* start address */
unsigned a_trsize; /* length of relocation info for text, in bytes */
unsigned a_drsize; /* length of relocation info for data, in bytes */
};
重定位信息部分的定义, include/a.out.h。有2个用处,一是当代码段被重定位到一个不同的基地址处时,重定位项则用于指出需要 修改的地方。二是在模块文件中存在对未定义符号引用时,当此未定义符号最终被定义时链接程序就可以使用相应重定位项对符号的值进行修正。
/* This structure describes a single relocation to be performed.
The text-relocation section of the file is a vector of these structures,
all of which apply to the text section.
Likewise, the data-relocation section applies to the data section. */
struct relocation_info
{
/* Address (within segment) to be relocated. */
int r_address;
/* The meaning of r_symbolnum depends on r_extern. */
unsigned int r_symbolnum:24;
/* Nonzero means value is a pc-relative offset
and it should be relocated for changes in its own address
as well as for changes in the symbol or section specified. */
unsigned int r_pcrel:1;
/* Length (as exponent of 2) of the field to be relocated.
Thus, a value of 2 indicates 1<<2 bytes. */
unsigned int r_length:2;
/* 1 => relocate with value of symbol.
r_symbolnum is the index of the symbol
in file's the symbol table.
0 => relocate with the address of a segment.
r_symbolnum is N_TEXT, N_DATA, N_BSS or N_ABS
(the N_EXT bit may be set also, but signifies nothing). */
unsigned int r_extern:1;
/* Four bits that aren't used, but when writing an object file
it is desirable to clear them. */
unsigned int r_pad:4;
};
符号表和字符串:
struct nlist {
union {
char *n_name;
struct nlist *n_next;
long n_strx;
} n_un;
unsigned char n_type;
char n_other;
short n_desc;
unsigned long n_value;
};
字符串表和符号表的区别:
如String s1=”hello world”,我的理解字符串表存放的是s1,符号表中存放的是s1在字符串中的下标和”hello world”的地址。
下面我们使用simpleSecticon.c来一步一步的了解目标文件究竟是什么样子的,毕竟上面只是纸上谈兵,准备程序,simpleSecticon.c
int printf(const char* format,...);
int global_init_var = 84;
int global_uninit_var;
void func1(int i){
printf("%d\n", i);
}
int main(void)
{
static int staic_var = 85;
static int staic_var2;
int a = 1;
int b;
func1(staic_var + staic_var2 + a + b);
return a;
}
只编译不连接:gcc -c simpleSecticon.c 获取目标文件。
使用objdump -h simpleSecticon.o来打印目标文件的基本信息:
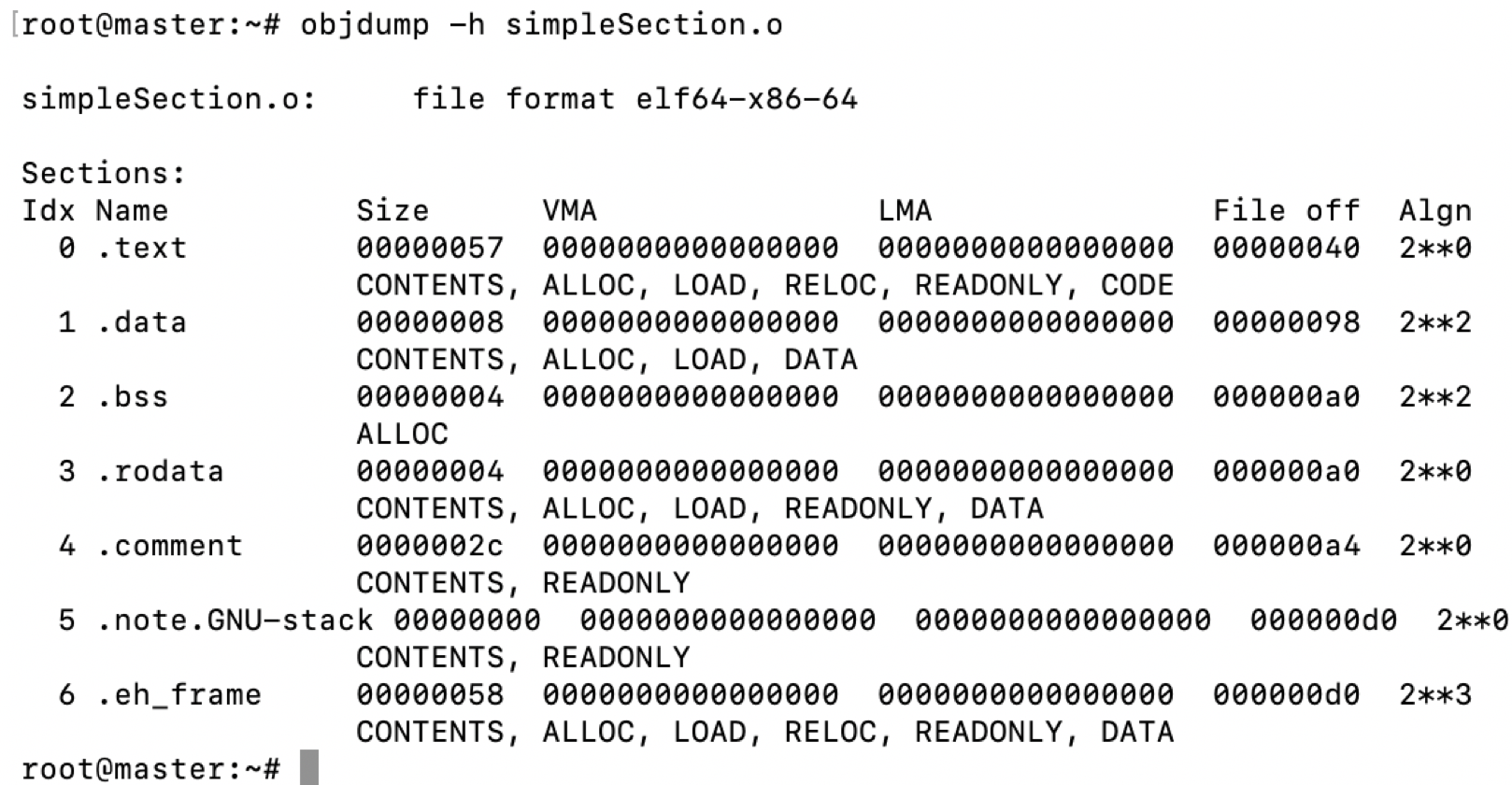
我们已经了解了几个段在目标文件中的分布,下面我们来详细看下:
首先看下代码段,将所有段的内容以十六进制的方式打印,并且指令反汇编
objdump -s -d simpleSecticon.o
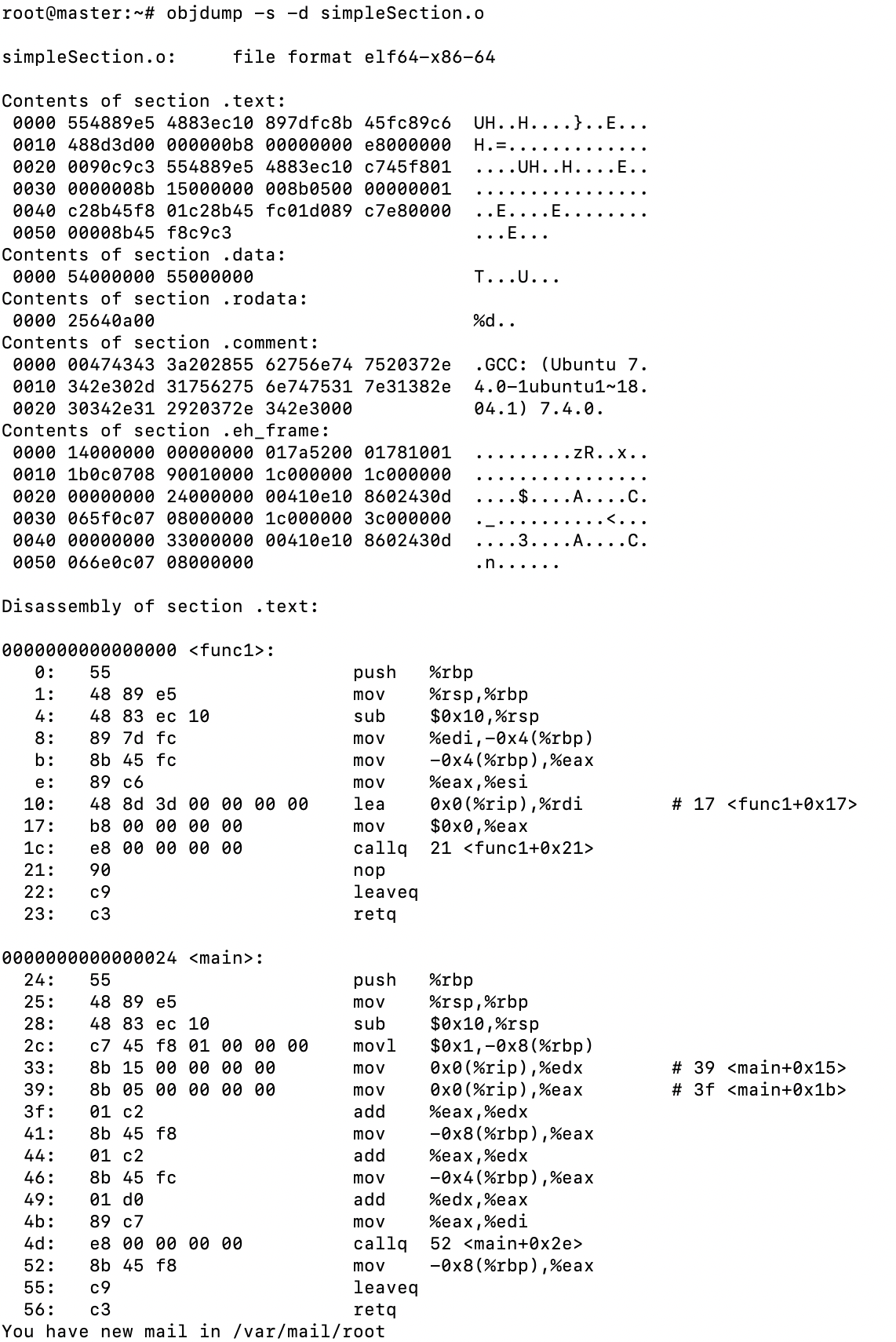
我们可以看到代码段包含func1和main函数的指令。
接着我们可以看数据段,.data段存放全局静态变量和局部静态变量,字符串常量也是在数据段中的。
bss段不再赘述。
在上面我们通过一个例子,大概了解了ELF文件的轮廓,接着我们来看下ELF文件的结构格式。
我们首先来看下ELF文件头,使用readelf -h simpleSecticon.o来查看头部基本信息
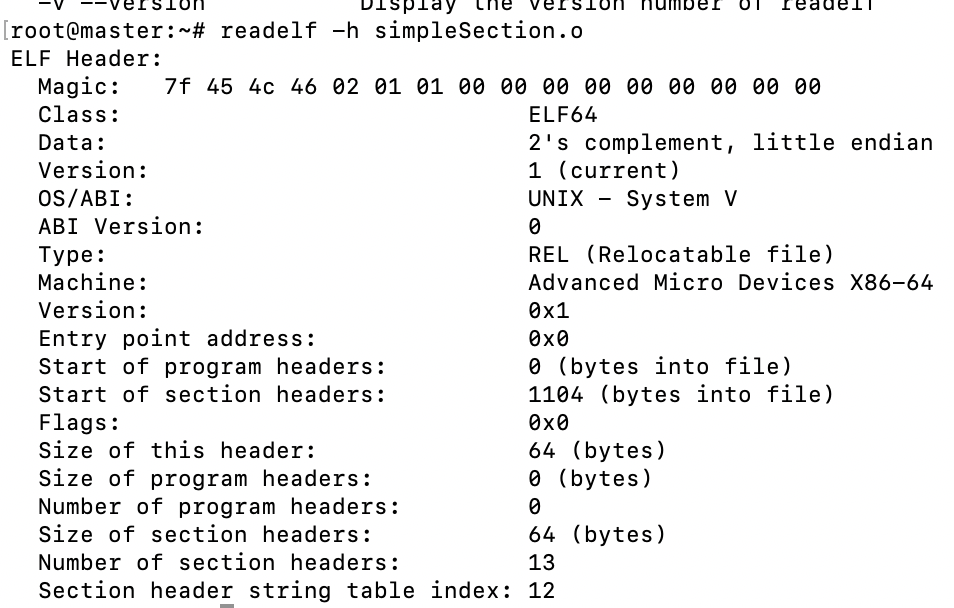
elf文件头定义在/usr/include/elf.h中
/* The ELF file header. This appears at the start of every ELF file. */
#define EI_NIDENT (16)
typedef struct
{
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */
Elf32_Half e_type; /* Object file type */
Elf32_Half e_machine; /* Architecture */
Elf32_Word e_version; /* Object file version */
Elf32_Addr e_entry; /* Entry point virtual address */
Elf32_Off e_phoff; /* Program header table file offset */
Elf32_Off e_shoff; /* Section header table file offset */
Elf32_Word e_flags; /* Processor-specific flags */
Elf32_Half e_ehsize; /* ELF header size in bytes */
Elf32_Half e_phentsize; /* Program header table entry size */
Elf32_Half e_phnum; /* Program header table entry count */
Elf32_Half e_shentsize; /* Section header table entry size */
Elf32_Half e_shnum; /* Section header table entry count */
Elf32_Half e_shstrndx; /* Section header string table index */
} Elf32_Ehdr;
在上面我们已经看到了目标文件有各种各样的段,我们使用使用readelf -S simpleSecticon.o来查看详细的段表结构,段表的结构是Elf32_Shdr,定义在/usr/include/elf.h中。
typedef struct
{
Elf32_Word sh_name; /* Section name (string tbl index) */
Elf32_Word sh_type; /* Section type */
Elf32_Word sh_flags; /* Section flags */
Elf32_Addr sh_addr; /* Section virtual addr at execution */
Elf32_Off sh_offset; /* Section file offset */
Elf32_Word sh_size; /* Section size in bytes */
Elf32_Word sh_link; /* Link to another section */
Elf32_Word sh_info; /* Additional section information */
Elf32_Word sh_addralign; /* Section alignment */
Elf32_Word sh_entsize; /* Entry size if section holds table */
} Elf32_Shdr;

分析到现在,我们已经把头部和段表都进行了分析,如下图所示,当然只是大概的,具体的没有展开。
哈哈,我们还有rel.text重定位表,字符串表,和符号表。
重定位表可以参考2.4里面的静态链接,不再详述。
下面看下字符串表。elf文件中用到了很多的字符串,有段名,变量名等。我们用偏移来表示字符串。字符串表分为strtab和section header string table,前者用来保存普通的字符串,如变量名,后者用来保存段名。
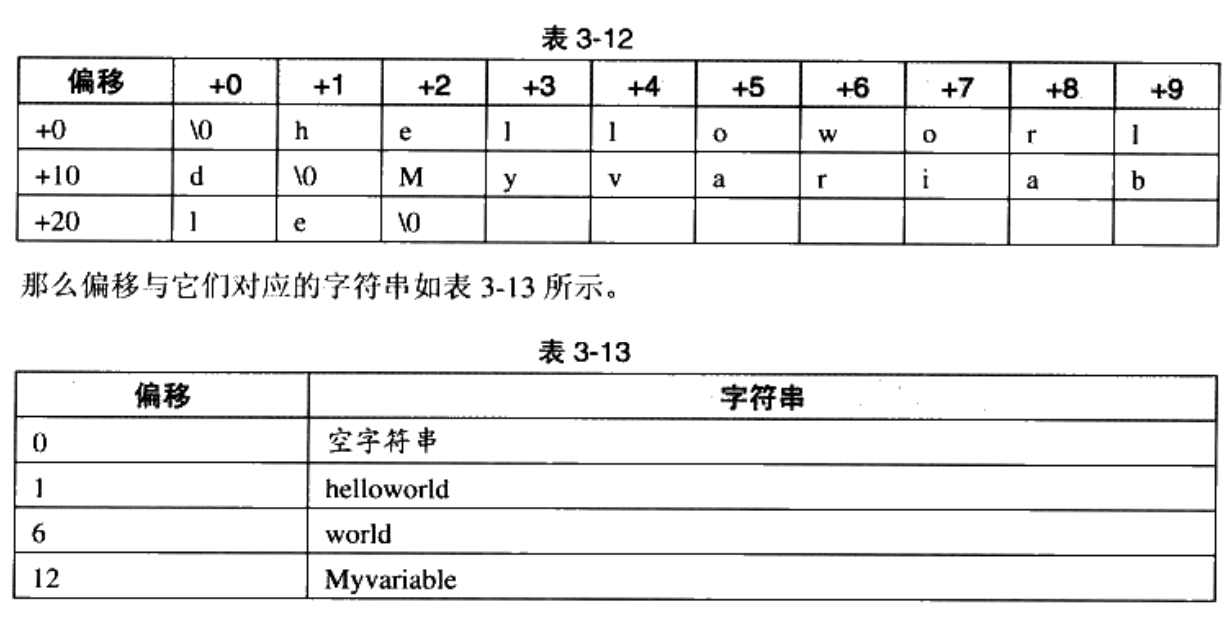
我们简单的看下符号表,具体的在下面讲解,符号表存放的是符号名在字符串表中的下表和符号对应的值的地址。
我们来总结下,二者之间的区别:
如String s1=”hello world”,我的理解字符串表存放的是s1,符号表中存放的是s1在字符串中的下标和”hello world”的地址。
2.3.5 链接的接口-符号
我们再来详细看下符号表。ELF符号表结构,特殊符号。
函数名和变量名叫符号名(Symbol),符号的值是地址。
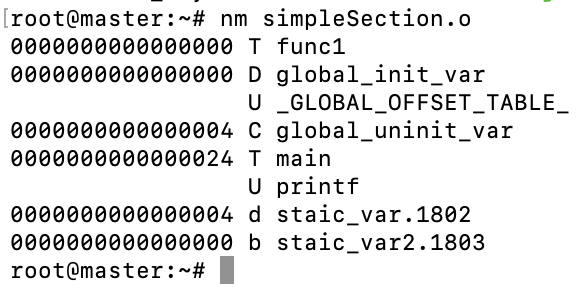
使用nm simpleSection.o来查看符号和符号值之间的关系,
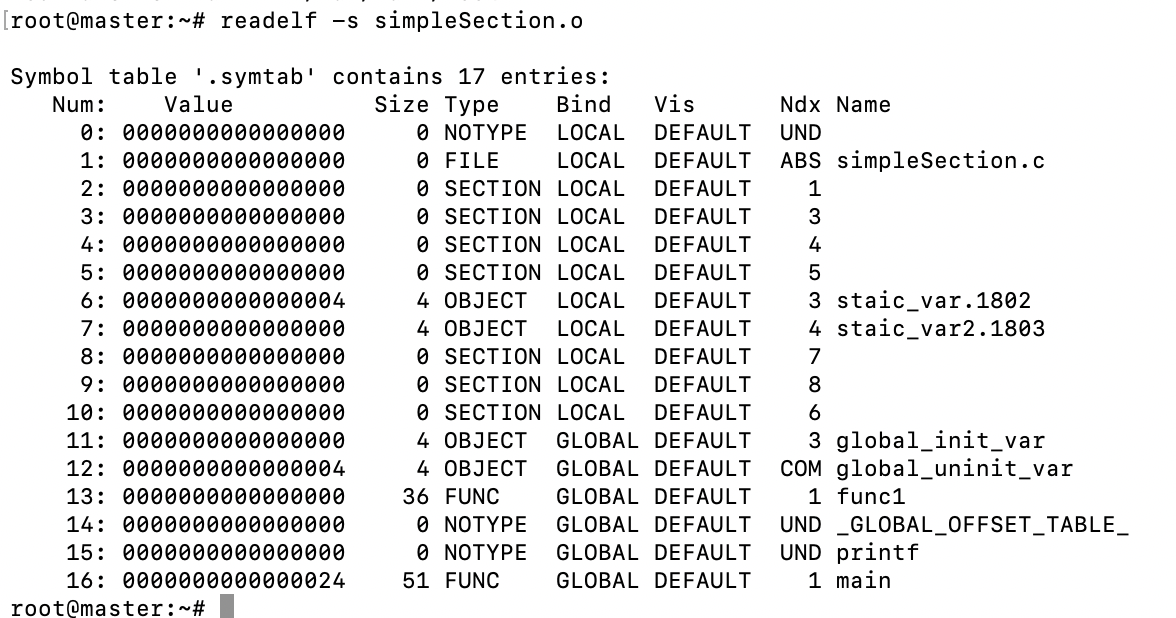
也可以使用readelf -s simpleSection.o来查看
/* Symbol table entry. */
typedef struct
{
Elf32_Word st_name; /* Symbol name (string tbl index) */
Elf32_Addr st_value; /* Symbol value */
Elf32_Word st_size; /* Symbol size */
unsigned char st_info; /* Symbol type and binding */
unsigned char st_other; /* Symbol visibility */
Elf32_Section st_shndx; /* Section index */
} Elf32_Sym;
2.3.6 调试
在目标代码里,保存了源代码和目标代码之间的映射。
2.4 静态链接
空间和地址分配,符号解析与重定位,common块,静态库链接,链接过程控制,BFD库 。
使用a.c和b.c来做为演示:
//a.c
extern int shared;
int main(){
int a=100;
swap(&a,&shared);
}
//b.c
int shared=1;
void swap(int *a,int *b){
*a^=*b^=*a^=*b;
}
2.4.1 空间和地址分配
我们想把a.o,b.o输出为ab,那么问题来了,多个目标文件的各个段怎么进行合并。
- 按序叠加:
- 优点:简单
- 缺点:浪费空间
- 相似段合并:
分配地址和空间有2层含义:第一个指的是可执行文件中的空间,第二个执行的是装载后在虚拟地址中的空间。 对于有实际数据的段,比如data和text的,在可执行文件和虚拟地址中都要分配空间。对于bss段,仅仅在虚拟地址分配空间。
链接分为2步,第一步是空间与地址分配,第二步是符号解析与重定位(核心)。
gcc -c a.c b.c生成a.o和b.o
使用gcc a.o b.o -e main可以进行链接,生成a.out(注,书上是ld,但是我用ld不可以)
接下来我们使用objdump来查看链接前后的地址分配情况:

其中,vma(virtual memory address)表示虚拟地址,lma(load memory address)表示加载地址。一般情况下,二者是相同的。
我们可以发现,在链接之前,VMA的值都是0,链接后,VMA中被赋予了值,就是虚拟地址。
上面我们已经确定了段的地址,然后我们确定符号的地址,事实上符号的地址是在段内是相对固定的。
2.4.2 符号地址解析与重定位
上面的研究完成之后,我们需要进行符号解析和重定位。
在此之前,我们需要研究研究下a.o是怎么使用shared和swap两个外部变量的。使用objdump -d a.o进行反汇编来看下效果:
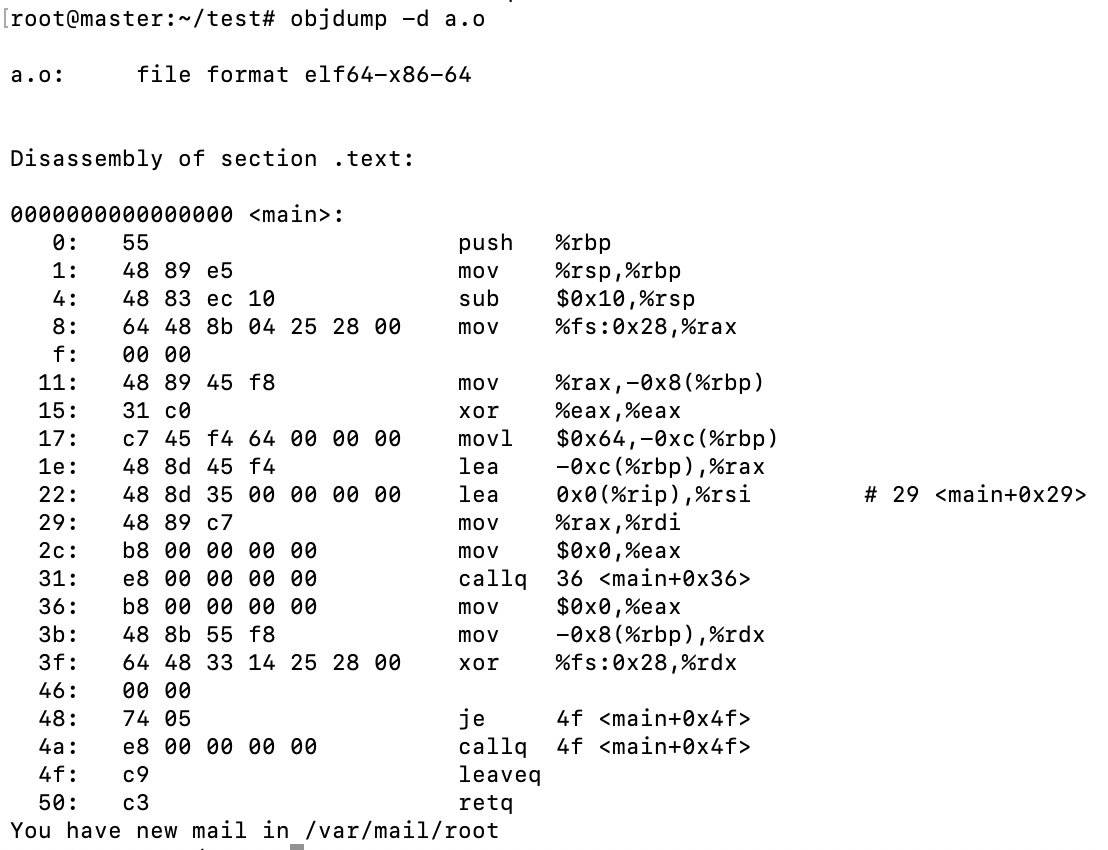
我们可以看到调用的地址(shared和swap)并不是真正的地址,而是00。
然后,我们在来用objdump -d a.out来看下重定位的效果:
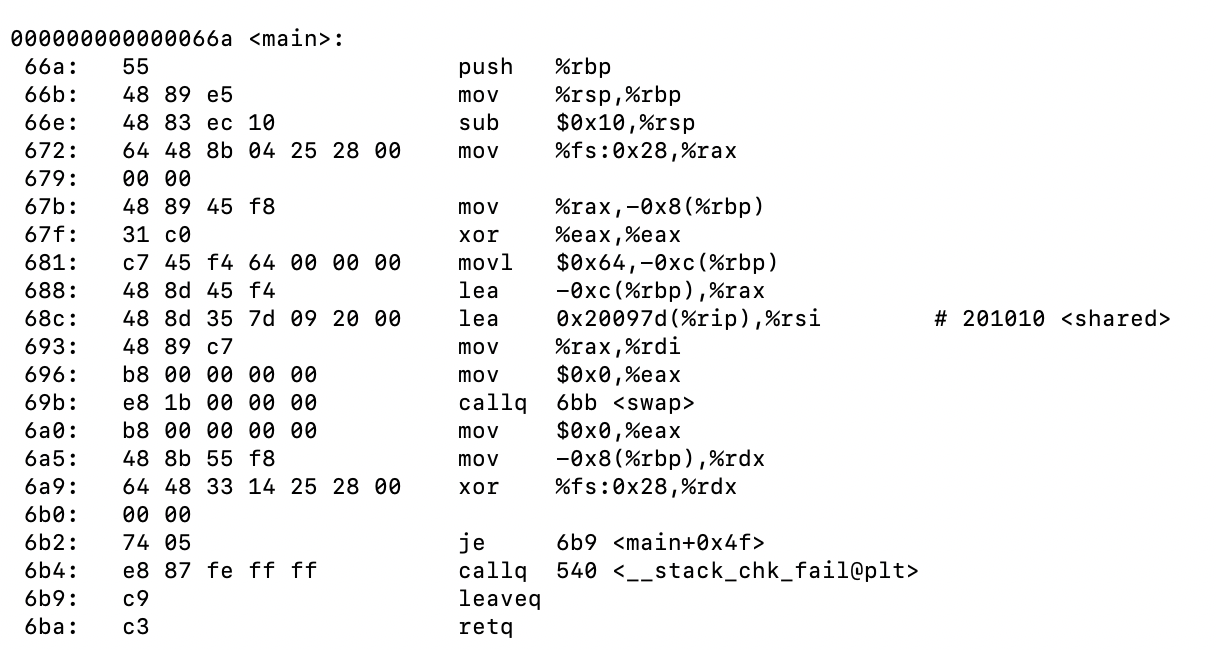
我们可以看到,已经是真正的地址了。
那么问题来了,链接器怎么知道如何调整指令呢?这就引入了下一个话题,重定位表(Relocation Table)。重定位表的规则是:如果.data段有需要重定位的,那么还有一个段叫做.rel.data。我们可以使用objdump -r a.o来进行查看:
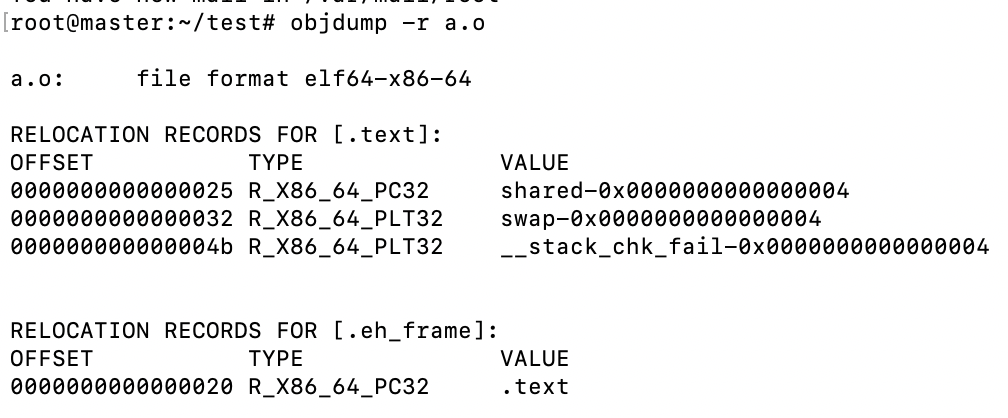
/* Relocation table entry without addend (in section of type SHT_REL). */
typedef struct
{
Elf32_Addr r_offset; /* Address */
Elf32_Word r_info; /* Relocation type and symbol index */
} Elf32_Rel;
事情还没有完,在重定位的过程中,往往还伴随着符号解析,所以在符号表里面必须进行定义。我们可以使用readelf -s a.o来查看符号表。
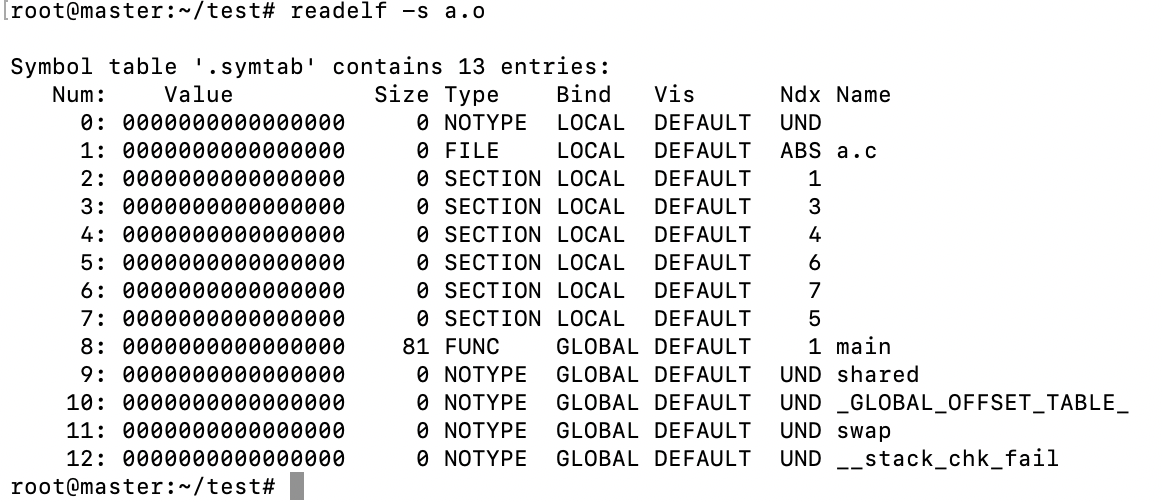
2.4.5 静态库链接
一个静态库可以看做是一组目标文件的集合。我们使用ar -t /usr/lib/x86_64-linux-gnu/libc.a来查看c语言所提供的库包含哪些静态库:

| 我们使用objdump -t /usr/lib/x86_64-linux-gnu/libc.a | grep printf.o来查看目标print.o文件。 |
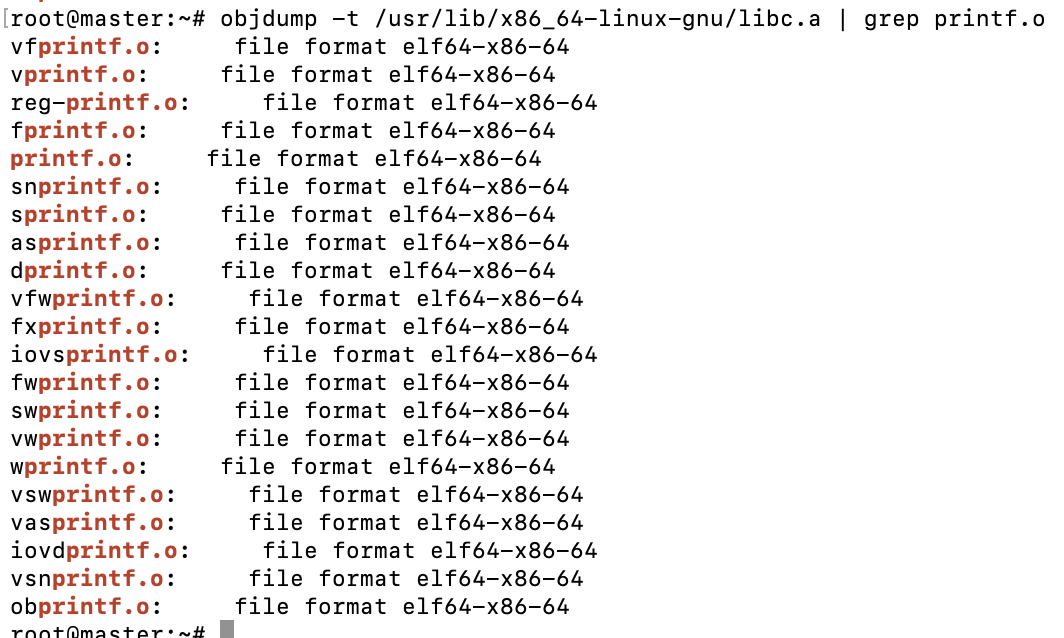
我们发现一个仅仅打印hello world的程序需要和很多其他的库进行链接。
我们可以使用 gcc -static –verbose -fno-builtin hello.c来把编译链接的过程的中间步骤打印出来。
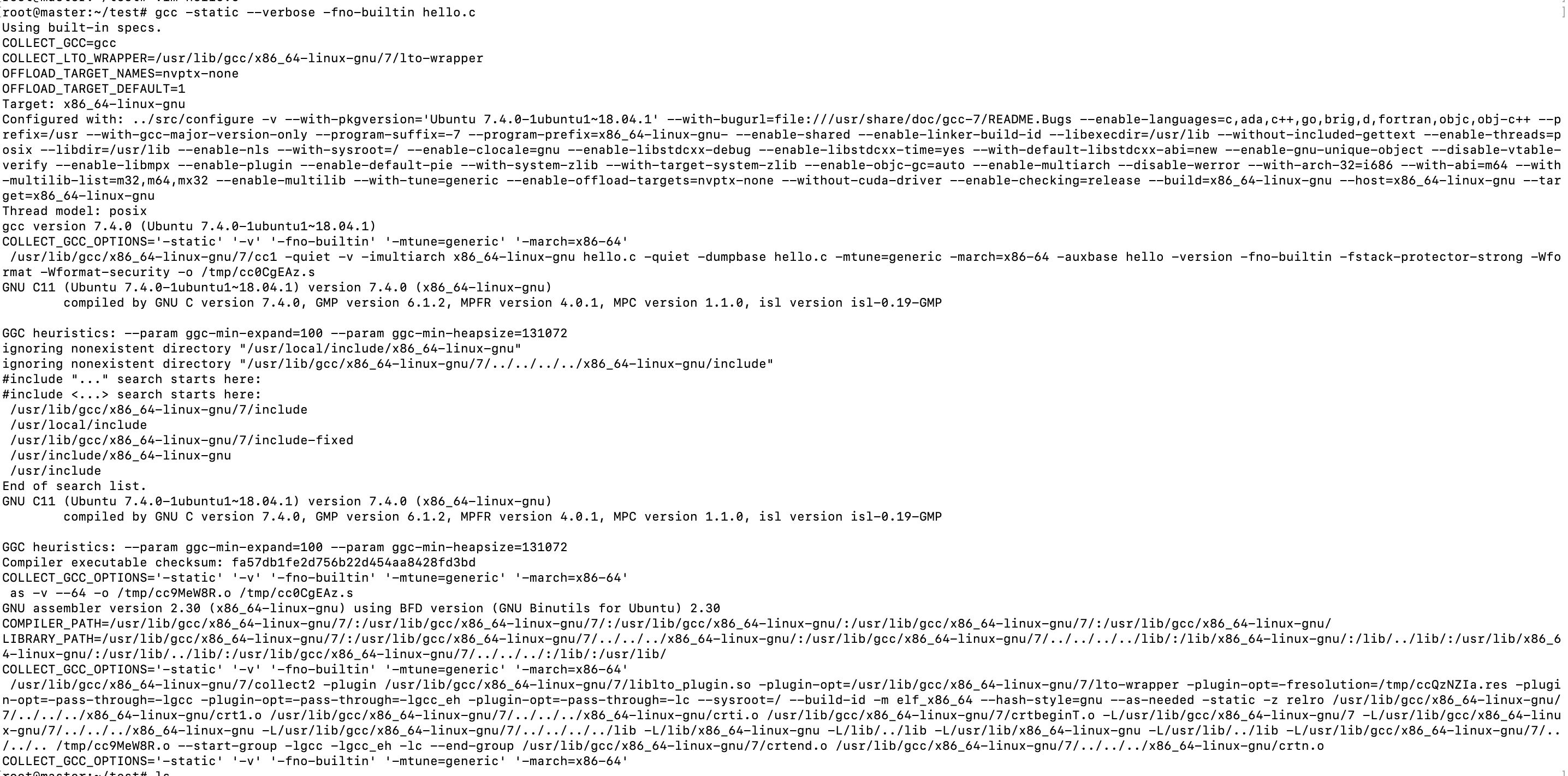
总结下,三个关键步骤,第一个调用ccl程序(gcc的c语言编译器)把hello.c变成/tmp/ccUhtGSB.s。
第二步调用as(GNU的编译器)把/tmp/ccUhtGSB.s变成/tmp/ccQZRPL5o,其实就是hello.o;
最后一步是用collect2来完成链接。
2.4.6 链接过程控制
我们来尝试自己实现一个hello world,不同的是我们不在使用main,printf这样的库函数。 print使用了linux的系统调用WRITE,exit使用了Linux的系统调用EXIT
// TinyHelloWorld.c
char *str = "Hello World!\n";
// use Linux WRITE system call
void print(){
asm("movl $13,%%edx \n\t"
"movl %0,%%ecx \n\t"
"movl $0,%%ebx \n\t"
"movl $4,%%eax \n\t"
"int $0x80 \n\t"
::"r"(str):"edx","ecx","ebx");
}
// use Linux EXIT system call
void exit(){
asm("movl $42,%ebx \n\t"
"movl $1,%eax \n\t"
"int $0x80 \n\t");
}
void nomain(){
print();
exit();
}
gcc -c -fno-builtin TinyHelloWorld.c
ld -static -e nomain -o TinyHelloWorld TinyHelloWorld.o
到了喜闻乐见的总结了:我们是先确定段的地址,然后进行符号解析和重定位,使他们指向正确的地址。
到这里了,我们生成了一个可执行文件,现在的寻址是基址+偏移。事情到这里并没有结束,我们还需要进行分页,来把程序分块装入内存。
3.装载与动态链接
6 可执行文件的装载与进程
研究可执行文件装载的本质,什么是进程的虚拟地址空间?为什么进程要有自己的虚拟地址空间?从历史的角度来看装载的几种方式,包括覆盖装载,页映射。接着会研究进程虚拟地址空间的分布情况,比如代码段,数据段,BSS段,堆,栈在进程的地址空间是怎么分布的,他们的位置和长度如何决定?
6.1 进程虚拟地址空间
32位cpu和64位cpu的区别:32位指的是寻址空间,即4G,64位的寻址空间很大,2^64。不是实际内存的大小。
每个进程的寻址空间可以是4G(32位CPU),如果不够的话,可以借助PAE技术。
6.2 装载的方式
覆盖装入(Overlay)和页映射(Paging),也就是分页机制,前者已经被抛弃。
6.3 从操作系统角度看可执行文件的装载
首先我们来看下进程的创建,分为以下几步,
-
创建一个独立的虚拟地址空间,映射了虚拟内存和物理内存,实际上是创建映射函数所需要的数据结构,创建页目录。(这一步建立的是虚拟空间和物理内存的映射关系)
- 读取可执行文件头,并且建立虚拟空间与可执行文件的映射关系。
- Linux中将进程虚拟空间中的一个段叫做虚拟内存区域(Virtual Memory Area,VMA),
- 将CPU的指令寄存器设置成可执行文件的入口地址,启动执行。

6.4 进程虚存空间分布
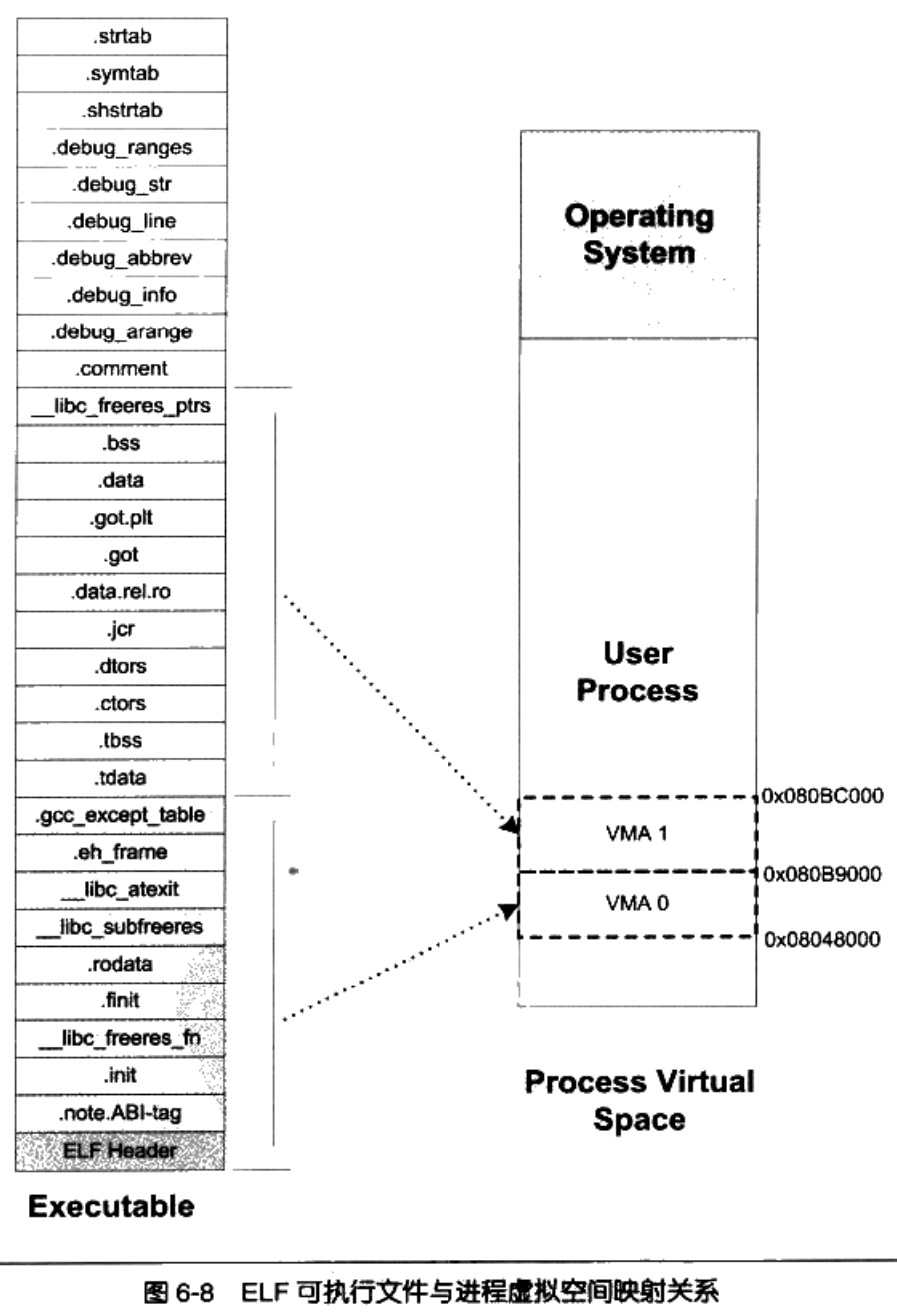
6.4.1 ELF文件链接视图和执行视图
本质上来讲,分段是为了避免代码段被修改,分页是为了解决物理内存不够的问题。
为了减少段的数量多导致的空间的浪费,我们按照段的权限把段进行合并。我们引入了一个新的概念,Section表示链接视图,Segment表示执行视图,我们来看一下具体的例子:
SectionMapping.c
#include "stdlib.h"
int main(){
while(1){
sleep(10);
}
return 0;
}
先进行静态链接:gcc -static SectionMapping.c -o SectionMapping.elf
然后我们按Section来看,总共32个段:readelf -S SectionMapping.elf

然后我们按Segment来看,总共5个,readelf -l SectionMapping.elf

程序头表。
/* Program segment header. */
typedef struct
{
Elf32_Word p_type; /* Segment type */
Elf32_Off p_offset; /* Segment file offset */
Elf32_Addr p_vaddr; /* Segment virtual address */
Elf32_Addr p_paddr; /* Segment physical address */
Elf32_Word p_filesz; /* Segment size in file */
Elf32_Word p_memsz; /* Segment size in memory */
Elf32_Word p_flags; /* Segment flags */
Elf32_Word p_align; /* Segment alignment */
} Elf32_Phdr;
6.4.2 堆和栈
VMA的用途:映射可执行文件中的Segment,对进程的地址空间进行管理(包括堆和栈)。
我们使用./SectionMapping.elf &
cat /proc/16148/maps 来查看进程的虚拟空间分布。
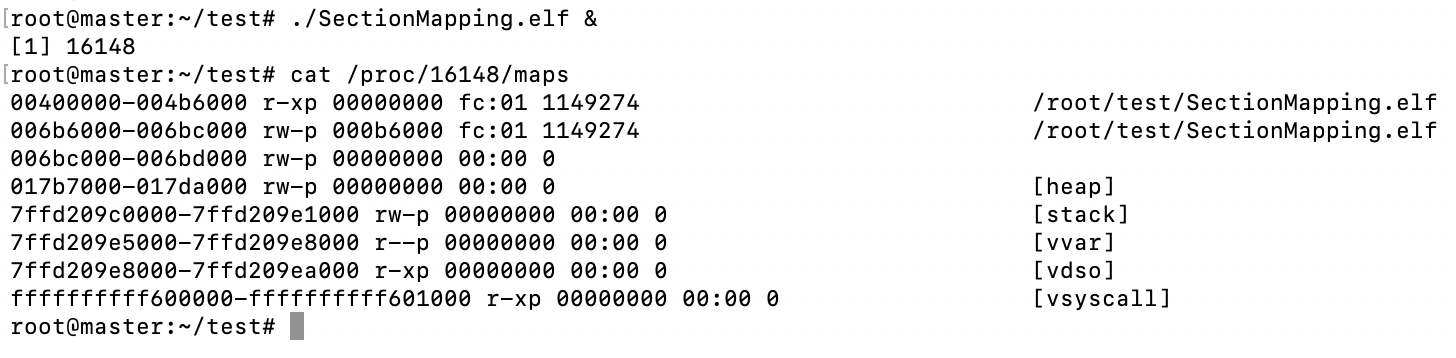
第一列表示VMA的地址范围,第二列表示权限(r读,w写,x执行,p私有,s共享),第三列表示偏移,第四列是主次设备号,第五列节点号,第六列文件的路径。
一个进程可以分为如下几种VMA区域:
-
代码VMA:只读,可执行,有映像文件;
-
数据VMA; 可读,可执行,有映像文件;
-
堆VMA;无映像文件,可向上扩展
-
栈VMA:无映像文件,可向下扩展
6.4.3 堆的最大申请数量
6.5 Linux内核装载ELF过程简介
我们从fork和execlp来实现minibash:
// minibash.c
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main(){
char buf[1024] = {0};
pid_t pid;
while(1){
printf("minibash$");
scanf("%s",buf);
pid = fork();
if(pid == 0){
if(execlp(buf,0) < 0){
printf("exec error\n");
}
}else if(pid > 0){
int status;
waitpid(pid,&status,0);
}else{
printf("fork error %d\n", pid);
}
}
return 0;
}
do_execve()(处理128字节的文件头部)–»search_binary_handle()–>load_elf_binary()(装载可执行脚本),在然后就是返回do_execve,在返回sys_execve,然后在返回到用户态。
我们来详细看下load_elf_binary的实现:
- 检查ELF可执行文件格式的有效性,比如魔数;
- 寻找动态链接中的”interp”段,设置动态链接路径;
- 根据ELF可执行文件的程序头表的描述,对ELF文件进行映射,比如代码,数据,只读数据;
- 初始化ELF进程环境
- 将系统调用的返回地址修改为ELF可执行文件的入口点。
总结:程序使用内存空间的问题,程序如何被操作系统加载到内存,页映射的好处,从操作系统的角度观察了进程如何被建立,程序开始运行时发生错误该如何处理。
还介绍了进程虚拟地址空间的分布,操作系统如何为程序的代码,数据,堆,栈在进程地址空间中的分配,以及如何分布的,然后我们谁让你如学习了Linux是如何装载并且运行ELF的。
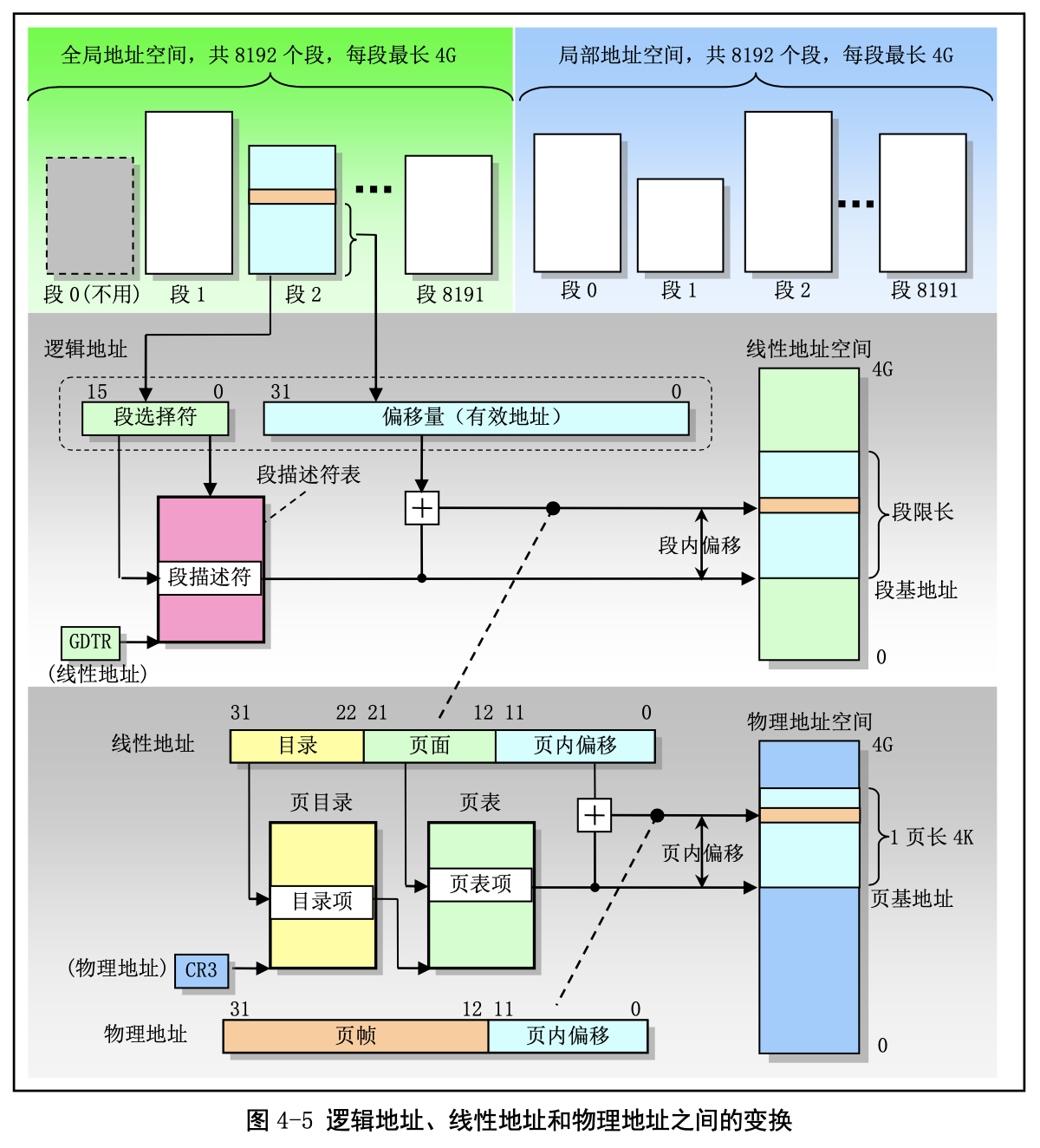
6.6 逻辑地址VS线性地址VS物理地址
这个地方,终于搞明白了,原来说的都不是一回事,逻辑地址指的是链接之后的可执行文件,线性地址指的是加载后的,物理地址指的是运行时的。如果没有页机制,线性地址就是物理地址。当CPU发生缺页中断时,会从硬盘调用,同时在Linear Address建立映射关系。
顺便吐槽下,中文技术社区的质量真是一言难尽,哎。。。
看一张mit的图片:
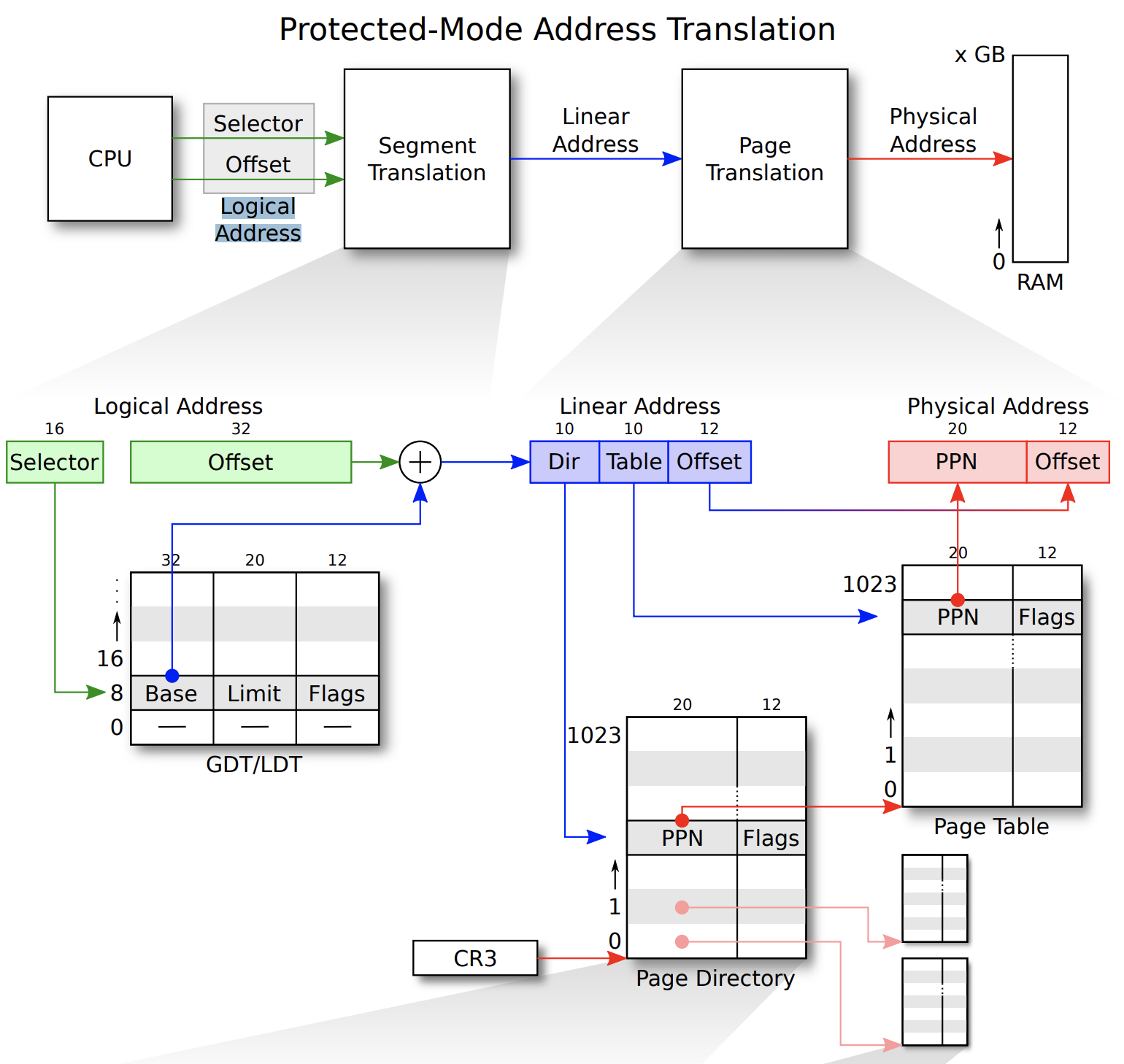
来自《Linux内核完全注释》5.3节。
Linux内存翻译的细节:
代码和数据在逻辑地址,线性地址和物理地址之间的对应关系。
为了有效地使用机器中的物理内存,在系统初始化阶段内存被划分成几个功 能区域 :
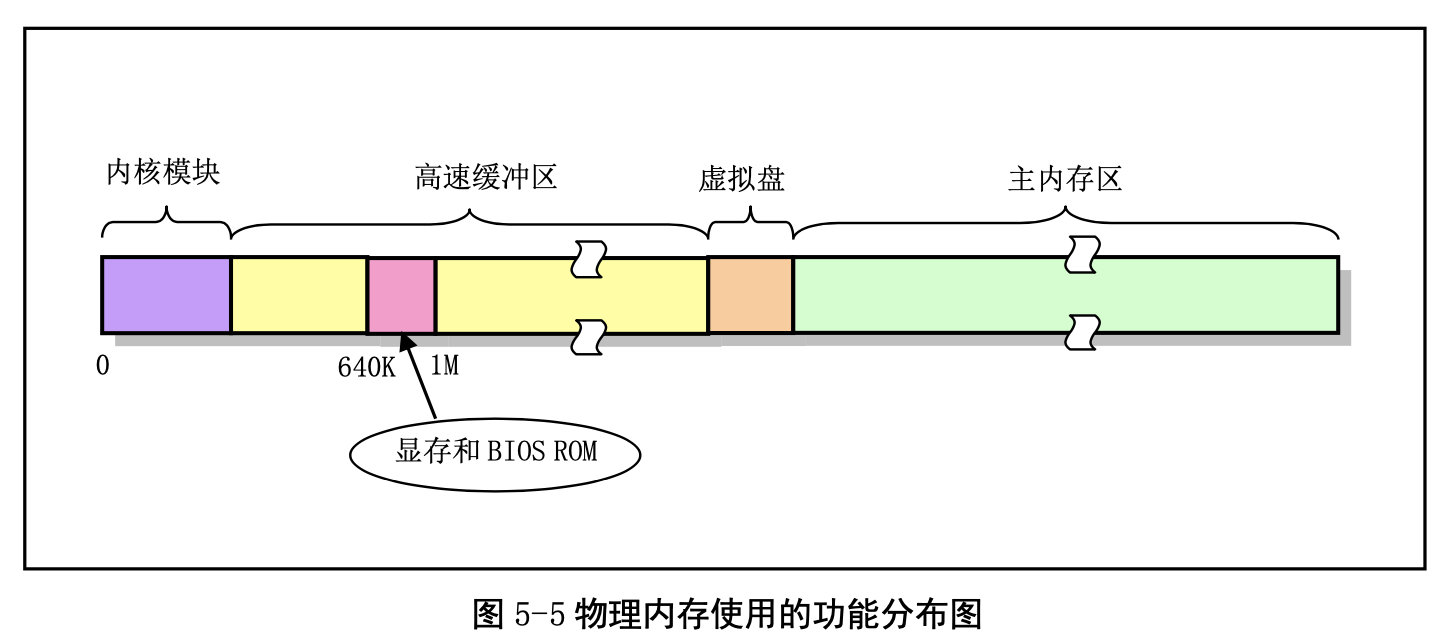
我们再来看内存地址空间的概念:
我们需要区分:进程的逻辑地址,CPU的线性地址,实际的物理内存。
-
逻辑地址:由 GDT 映射的全局地址空间和 由 LDT 映射的局部地址空间组成。由程序产生的与段相关的偏移地址部分。所以程序员可以使用的逻辑地址空间是4G。
- 线性地址(Linear Address)是逻辑地址到物理地址变换之间的中间层,是处理器可寻址的内存空间 (称为线性地址空间)中的地址。 32位的为4G。
- 物理地址(Physical Address)是指出现在 CPU 外部地址总线上的寻址物理内存的地址信号,是地址变换的最终结果地址。
在 Linux 0.12 内核中,给每个程序(进程)都划分了总容量为 64MB 的虚拟内存空间。因此程序的逻辑地址范围是 0x0000000 到 0x4000000。虚拟内存面向用户:好像给用户提供了一个很大的内存,提供一个假象。面向计算机,使用分页机制,把虚拟地址映射到物理内存,加快了读取的速度。
所以,给每个进程提供了4G的逻辑地址(即寻址空间),给每个程序提供了64M的虚拟内存空间,注意体会之间的区别。
下面我们来看下内存分段机制:
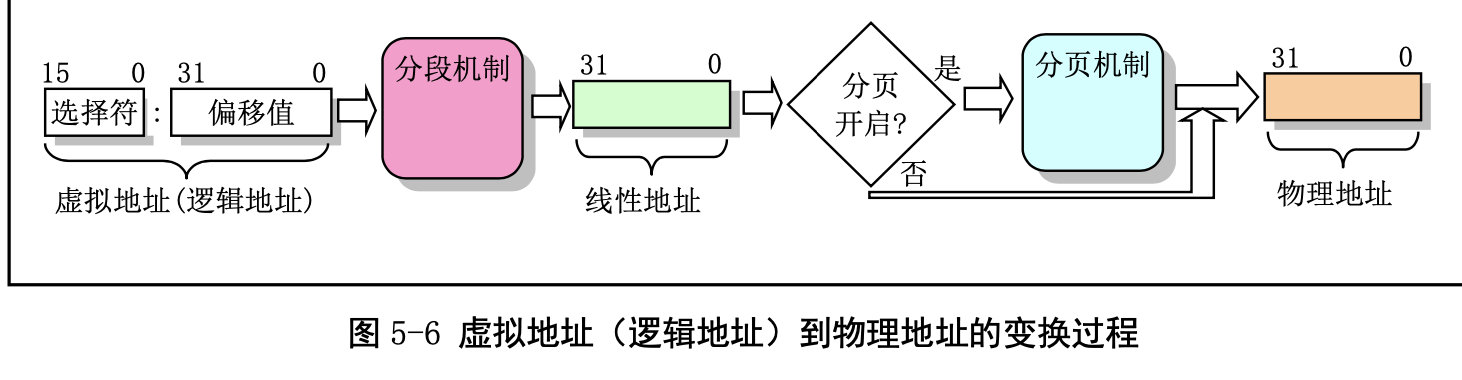
CPU 进行地址变换(映射)的主要目的是为了解决虚拟内存空间到物理内存空间的映射问题。虚拟 内存空间的含义是指一种利用二级或外部存储空间,使程序能不受实际物理内存量限制而使用内存的一种方法。通常虚拟内存空间要比实际物理内存量大得多。
那么虚拟存储管理是怎样实现的呢?首先,当一个程序需要使用 一块不存在的内存时(也即在内存页表项中已标出相应内存页面不在内存中),CPU 就需要一种方法来 得知这个情况。这是通过 80386 的页错误异常中断来实现的。当一个进程引用一个不存在页面中的内存 地址时,就会触发 CPU 产生页出错异常中断,并把引起中断的线性地址放到 CR2 控制寄存器中。因此 处理该中断的过程就可以知道发生页异常的确切地址,从而可以把进程要求的页面从二级存储空间(比 如硬盘上)加载到物理内存中。如果此时物理内存已经被全部占用,那么可以借助二级存储空间的一部 分作为交换缓冲区(Swapper)把内存中暂时不使用的页面交换到二级缓冲区中,然后把要求的页面调入 内存中。这也就是内存管理的缺页加载机制,在 Linux 0.12 内核中是在程序 mm/memory.c 中实现。
在实模式下,寻址一个内存地址主要是使用段和偏移值,段值被存放在段寄存器中(例如 ds),并 且段的长度被固定为 64KB。段内偏移地址存放在任意一个可用于寻址的寄存器中(例如 si)。因此,根
据段寄存器和偏移寄存器中的值,就可以算出实际指向的内存地址,见图 5-7 (a)所示。 而在保护模式运行方式下,段寄存器中存放的不再是被寻址段的基地址,而是一个段描述符表 (Segment Descriptor Table)中某一描述符项在表中的索引值。索引值指定的段描述符项中含有需要寻址 的内存段的基地址、段的长度值和段的访问特权级别等信息。寻址的内存位置是由该段描述符项中指定 的段基地址值与一个段内偏移值组合而成。段的长度可变,由描述符中的内容指定。可见,和实模式下 的寻址相比,段寄存器值换成了段描述符表中相应段描述符的索引值以及段表选择位和特权级,称为段 选择符(Segment Selector),但偏移值还是使用了原实模式下的概念。这样,在保护模式下寻址一个内 存地址就需要比实模式下多一道手续,也即需要使用段描述符表。这是由于在保护模式下访问一个内存 段需要的信息比较多,而一个 16 位的段寄存器放不下这么多内容。示意图见图 5-7 (b)所示。注意,如果 你不在一个段描述符中定义一个内存线性地址空间区域,那么该地址区域就完全不能被寻址,CPU 将拒 绝访问该地址区域。
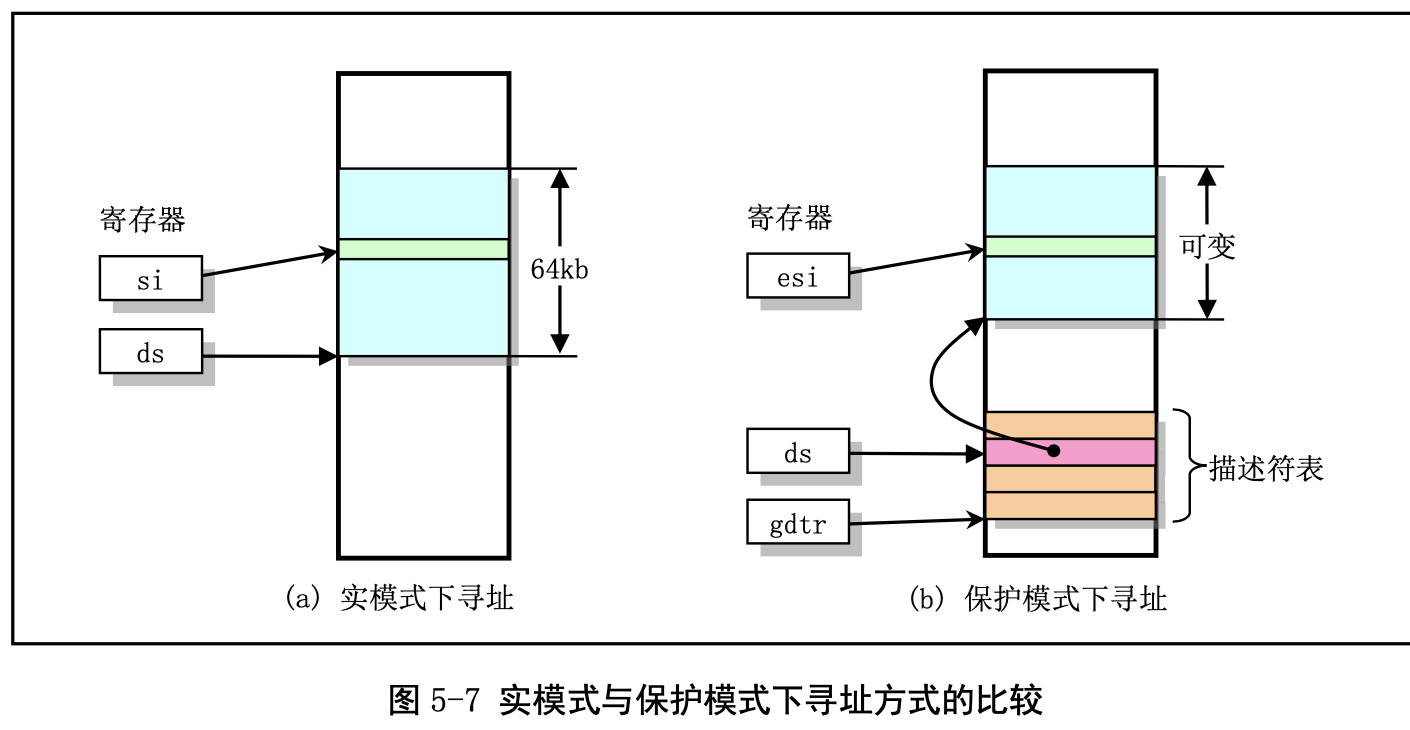
每个描述符占用 8 个字节,其中含有所描述段在线性地址空间中的起始地址(基址)、段的长度、段 的类型(例如代码段和数据段)、段的特权级别和其他一些信息。一个段可以定义的最大长度是 4GB。
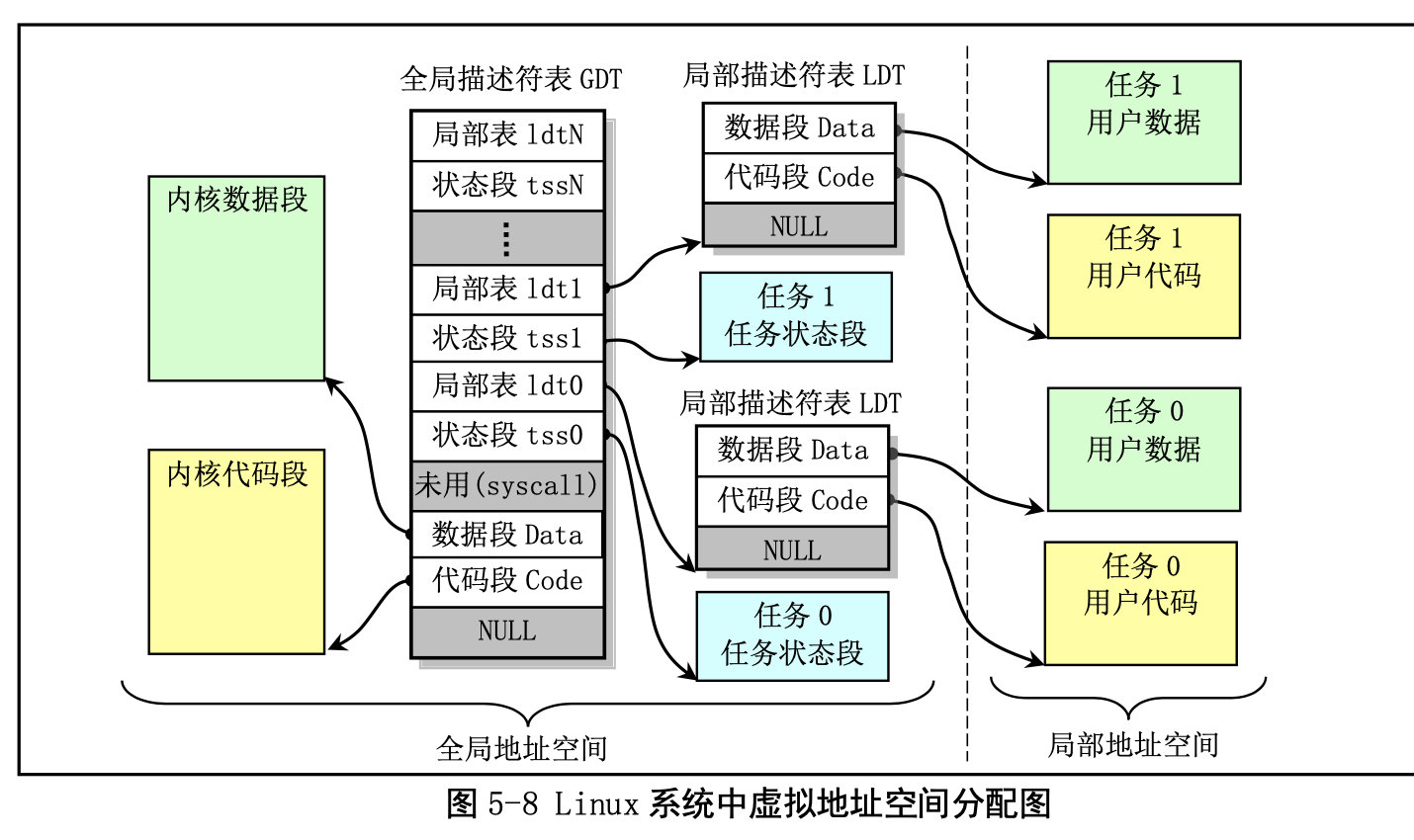
保存描述符项的描述符表有 3 种类型,每种用于不同目的。全局描述符表 GDT(Global Descriptor Table)是主要的基本描述符表,该表可被所有程序用于引用访问一个内存段。中断描述符表 IDT(Interrupt Descriptor Table)保存有定义中断或异常处理过程的段描述符。IDT 表直接替代了 8086 系统中的中断向 量表。为了能在 80X86 保护模式下正常运行,我们必须为 CPU 定义一个 GDT 表和一个 IDT 表。最后一 种类型的表是局部描述符表 LDT(Local Descriptor Table)。该表应用于多任务系统中,通常每个任务使 用一个 LDT 表。作为对 GDT 表的扩充,每个 LDT 表为对应任务提供了更多的可用描述符项,因而也为 每个任务提供了可寻址内存空间的范围。这些表可以保存在线性地址空间的任何地方。为了让 CPU 能定 位 GDT 表、IDT 表和当前的 LDT 表,需要为 CPU 分别设置 GDTR、IDTR 和 LDTR 三个特殊寄存器。 这些寄存器中将存储对应表的 32 位线性基地址和表的限长字节值。表限长值是表的长度值-1。
当 CPU 要寻址一个段时,就会使用 16 位的段寄存器中的选择符来定位一个段描述符。在 80X86 CPU 中,段寄存器中的值右移 3 位即是描述符表中一个描述符的索引值。13 位的索引值最多可定位 8192 (0–8191)个的描述符项。选择符中位 2(TI)用来指定使用哪个表。若该位是 0 则选择符指定的是 GDT 表中的描述符,否则是 LDT 表中的描述符。 每个程序都可有若干个内存段组成。程序的逻辑地址(或称为虚拟地址)即是用于寻址这些段和段中具体地址位置。在 Linux 0.12 中,程序逻辑地址到线性地址的变换过程使用了 CPU 的全局段描述符表 GDT 和局部段描述符表 LDT。由 GDT 映射的地址空间称为全局地址空间,由 LDT 映射的地址空间则称 为局部地址空间,而这两者构成了虚拟地址的空间。具体的使用方式见图 5-8 所示。
下面我们再来看下内存的分页管理:
内存分页管理机制的基本原理是将 CPU 整个线性内存区域划分成 4096 字节为 1 页的内存页面。
线性地址到物理地址的变换过程。由于Linux 0.1x系统中内核和所有任务都共用同一个页目录表,使得任何时刻处理器线性地址空间 到物理地址空间的映射函数都一样。因此为了让内核和所有任务都不互相重叠和干扰,它们都必须从虚 拟地址空间映射到线性地址空间的不同位置,即占用不同的线性地址空间范围。
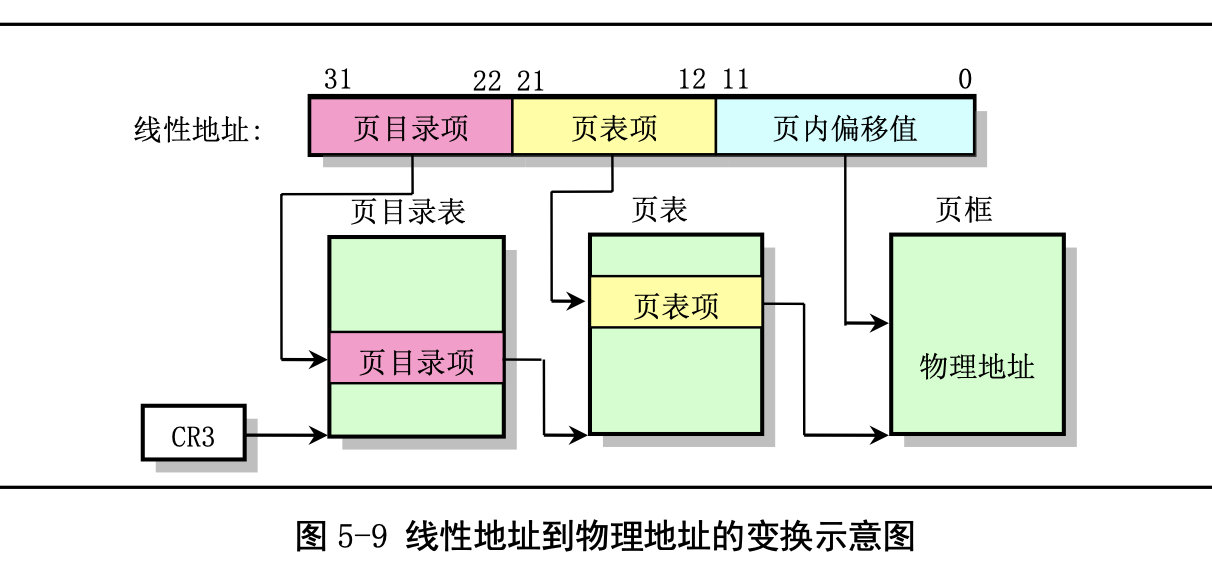
一个任务的虚拟地址需要首先通 过其局部段描述符变换为 CPU 整个线性地址空间中的地址,然后再使用页目录表 PDT(一级页表)和 页表 PT(二级页表)映射到实际物理地址页上。为了使用实际物理内存,每个进程的线性地址通过二级内存页表动态地映射到主内存区域的不同物理内存页上。由于 Linux 0.12 中把每个进程最大可用虚拟内 存空间定义为 64MB,因此每个进程的逻辑地址通过加上(任务号)*64MB,即可转换为线性空间中的地址。
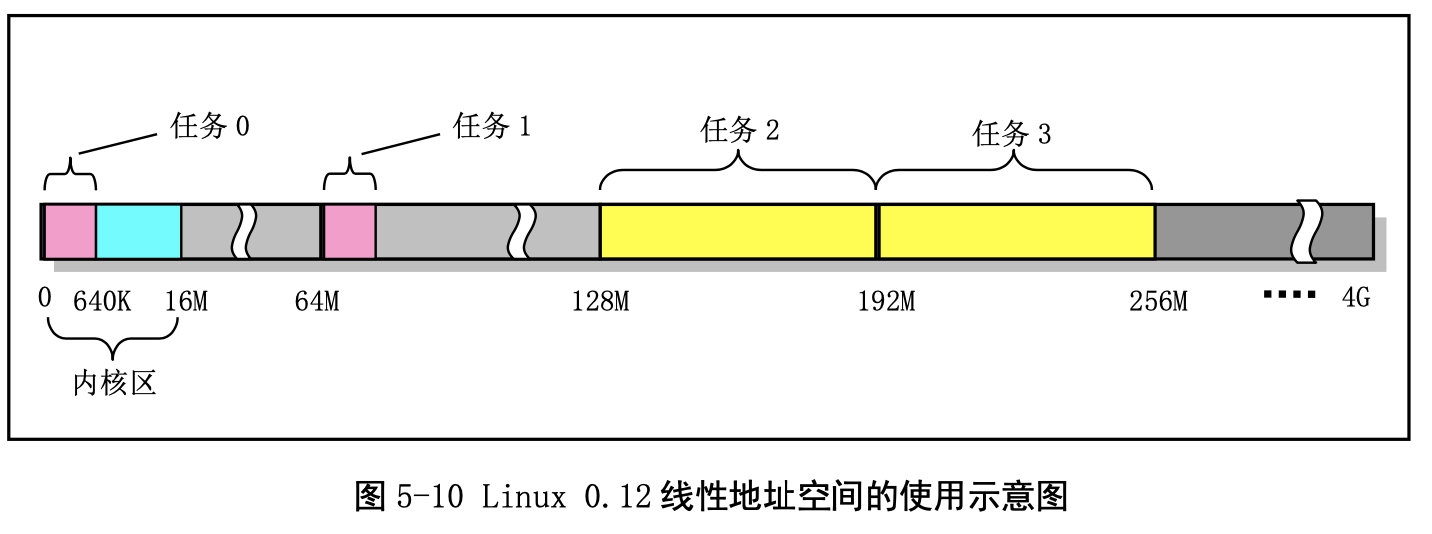
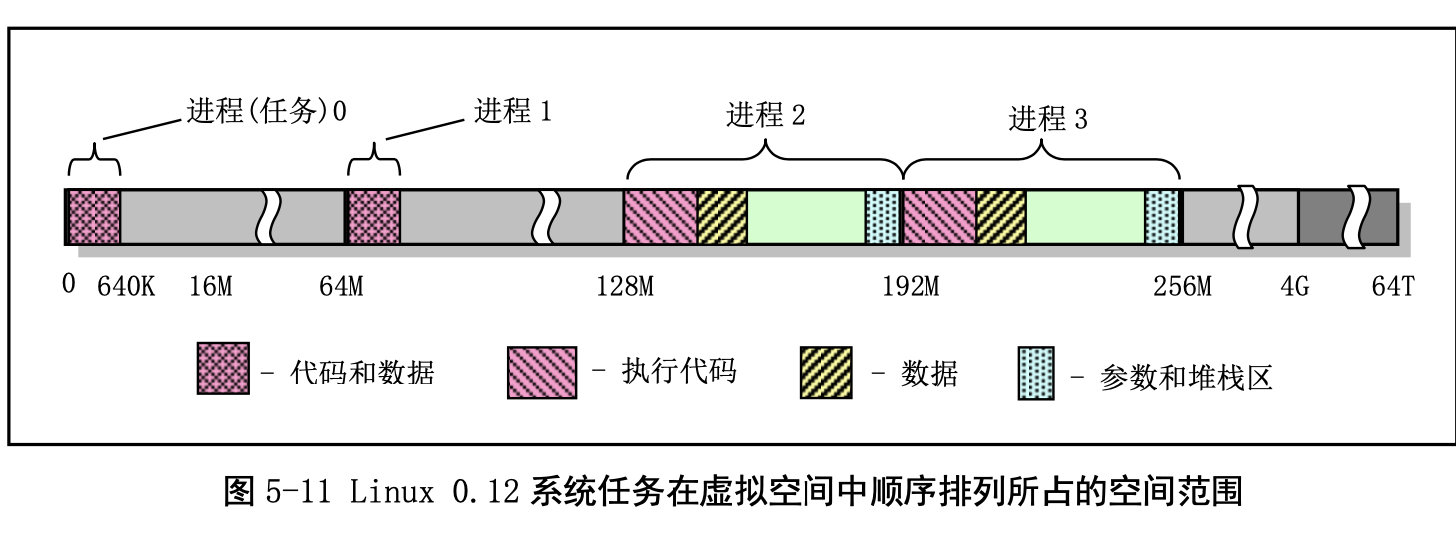
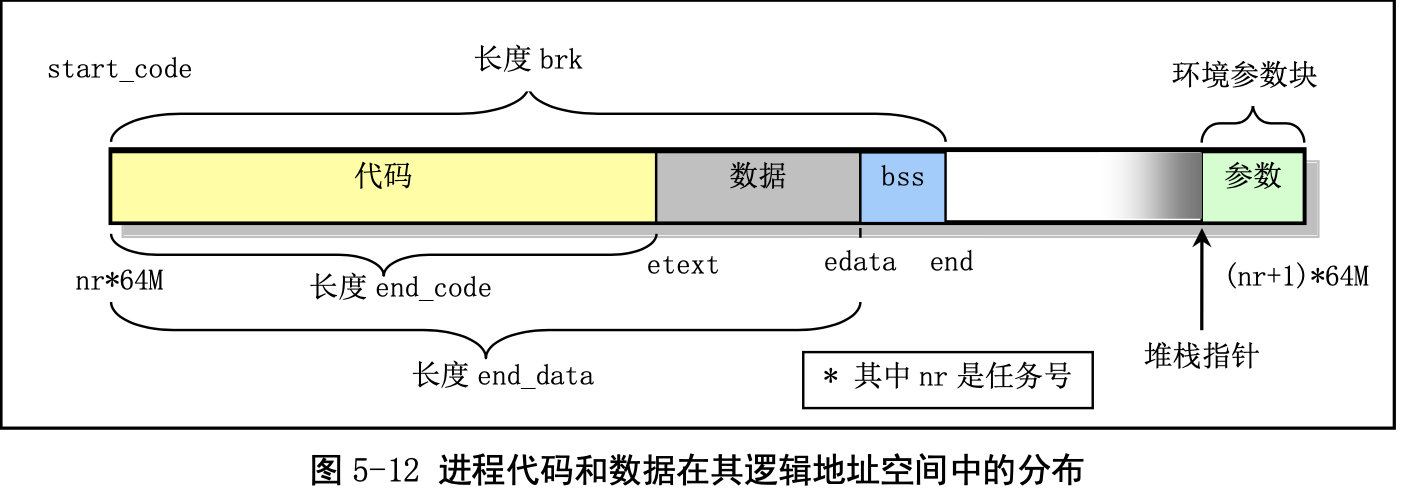
进程逻辑地址空间中代码段(Code Section)和数据段(Data Section)的概念与CPU 分段机制中的代码段和数据段不是同一个概念。CPU 分段机制中段的概念确定了在线性地址空间中一个 段的用途以及被执行或访问的约束和限制,每个段可以设置在 4GB 线性地址空间中的任何地方,它们可 以相互独立也可以完全重叠或部分重叠。而进程在其逻辑地址空间中的代码段和数据段则是指由编译器 在编译程序和操作系统在加载程序时规定的在进程逻辑空间中顺序排列的代码区域、初始化和未初始化 的数据区域以及堆栈区域。进程逻辑地址空间中代码段和数据段等结构形式见图所示。有关逻辑地址空 间的说明请参见内存管理一章内容。其中 nr 是任务号,start_code 是进程或任务在线性地址空间的起始 位置。其他变量均表示进程在逻辑空间中的值。
虚拟地址、线性地址和物理地址之间的关系:
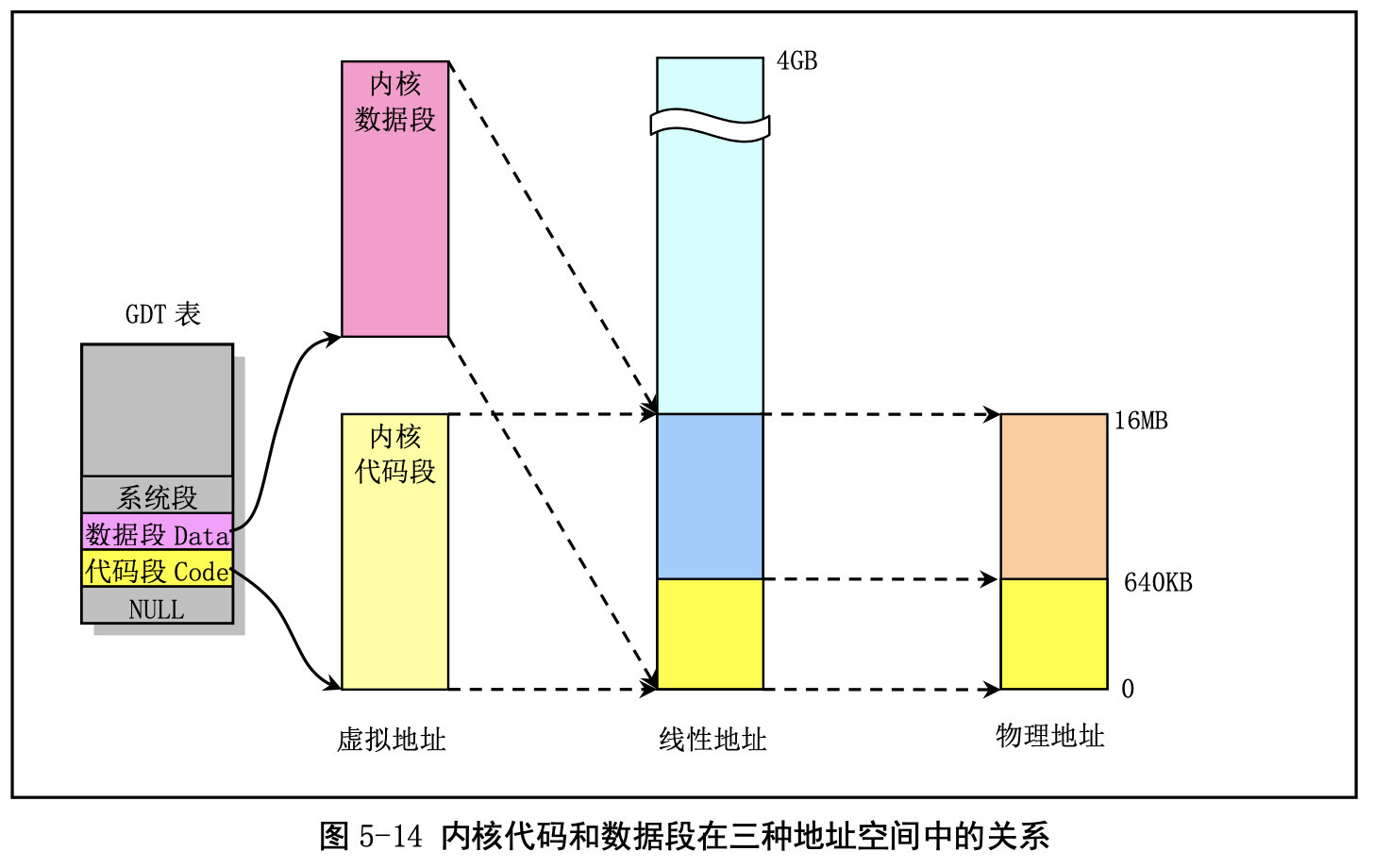
任务 0 的地址对应关系:
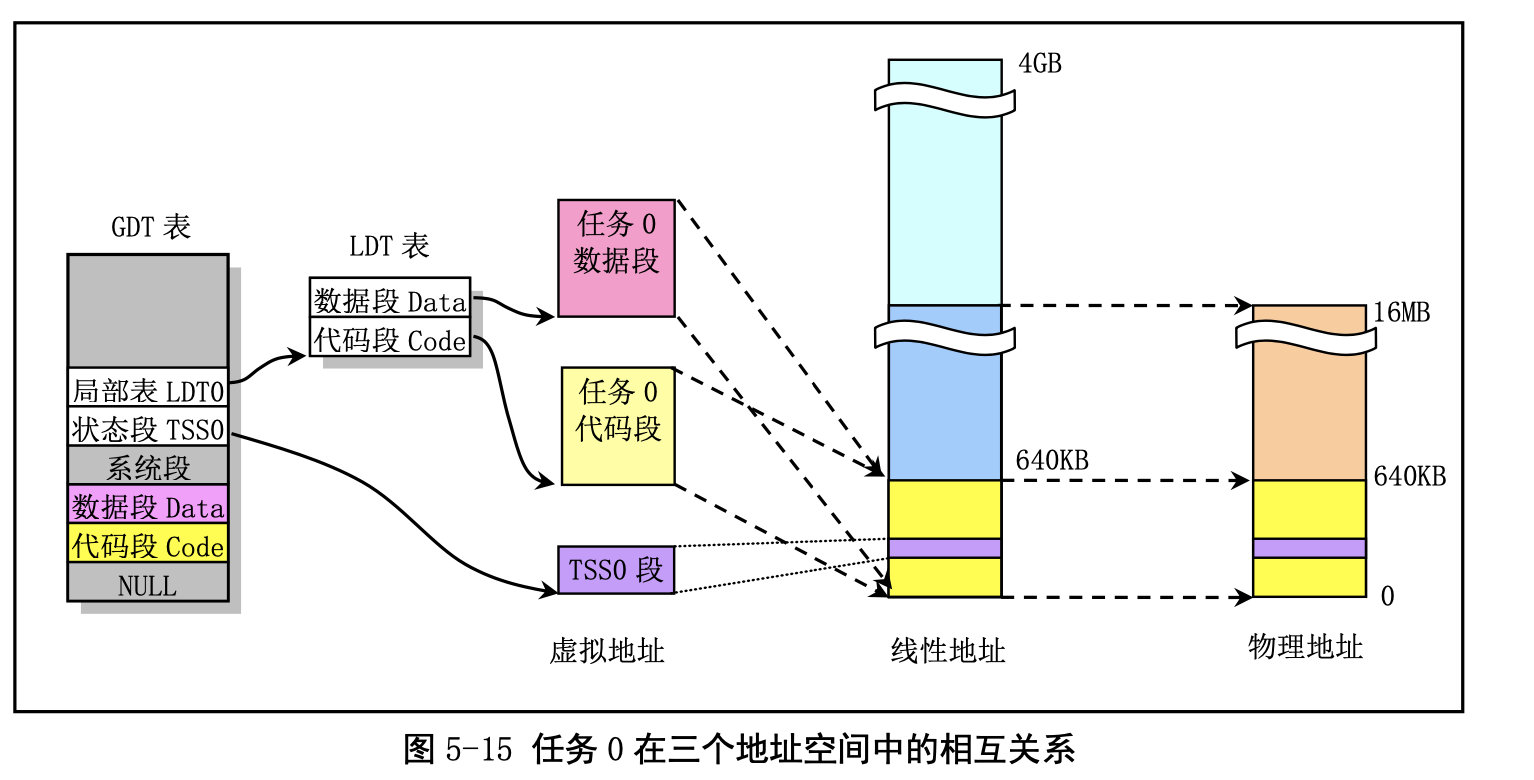
任务 1 的地址对应关系:
与任务 0 类似,任务 1 也是一个特殊的任务。它的代码也在内核代码区域中。与任务 0 不同的是在 线性地址空间中,系统在使用 fork()创建任务 1(init 进程)时为存放任务 1 的二级页表而在主内存区申 请了一页内存来存放,并复制了父进程(任务 0)的页目录和二级页表项。
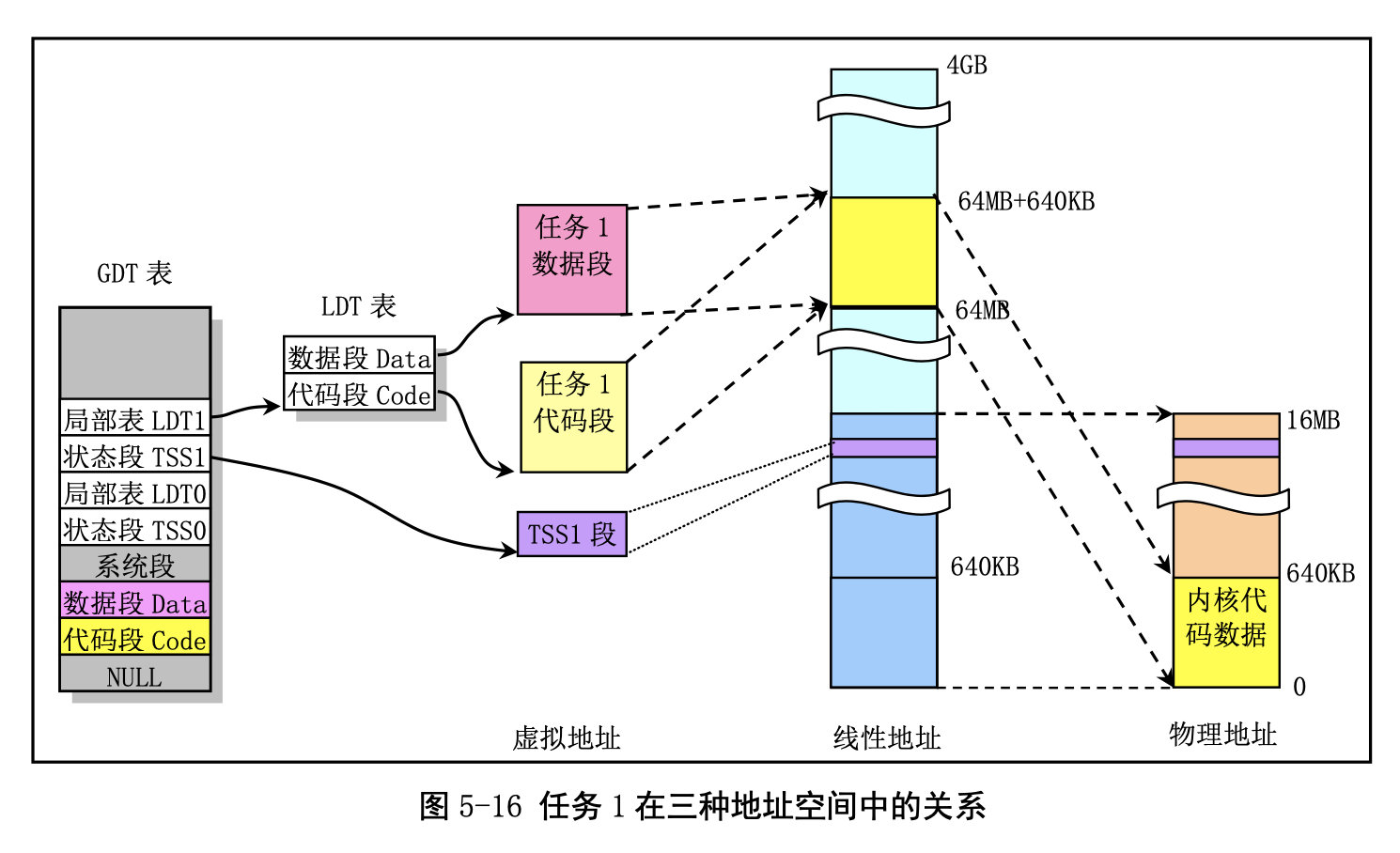
其他任务的地址对应关系:
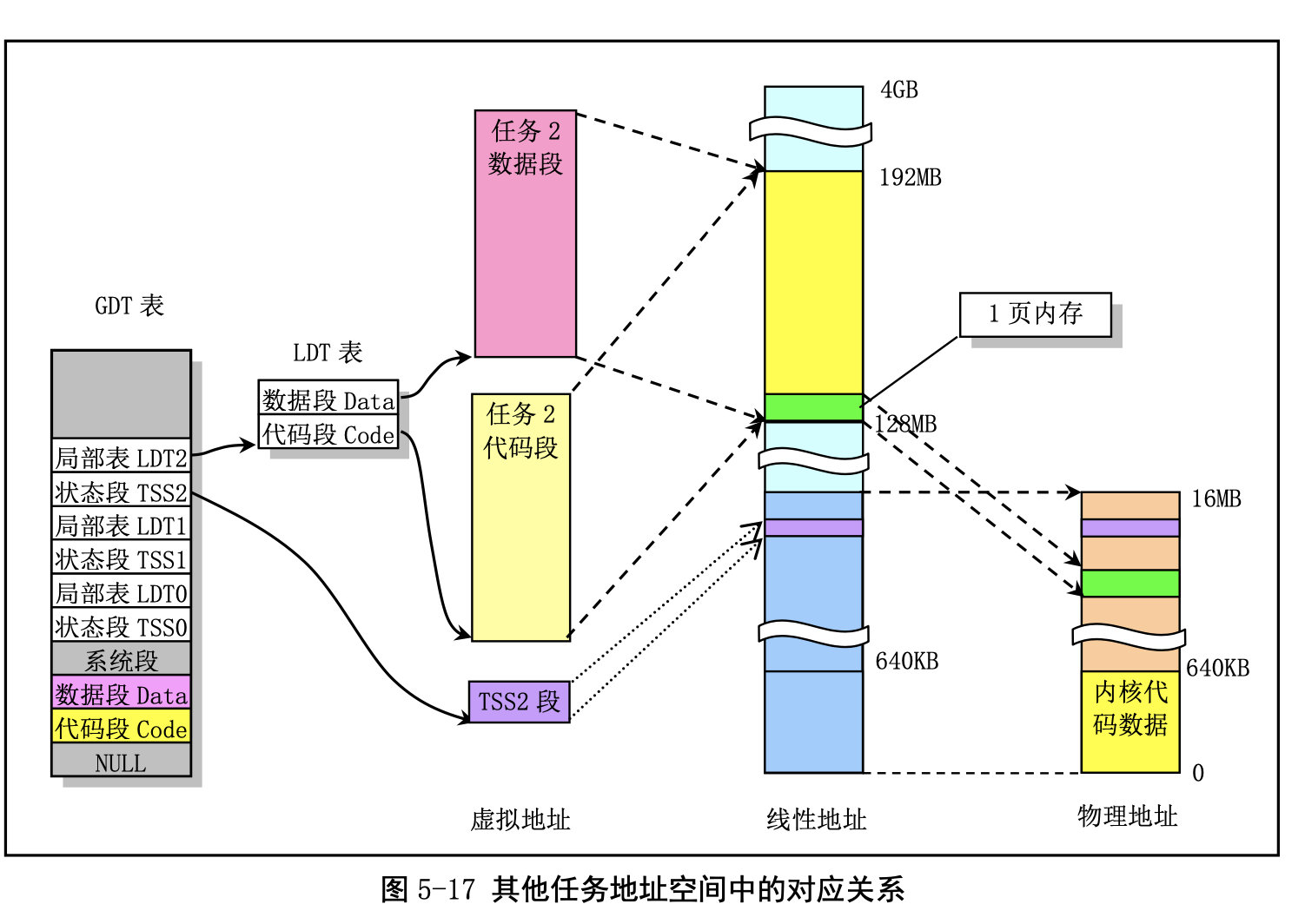
总体来看下:
7. 动态链接
7.1 为什么要动态链接
浪费空间,模块更新困难引入了动态链接,节省了内存,减少了物理页面的换入换出,增加了CPU的命中率,易于升级。 但是动态链接也不是万能的,也有其他的缺点,新旧版本无法兼容是最大的问题。
动态链接的基本实现:程序被分为主要模块和动态链接库。当程序被装载的时候,动态链接器会把所有的动态链接库装载到程序的进程空间,真正的链接工作是由动态链接器完成的,也就是说,被延后了。但是性能会损失5%左右,还是十分划算的。
动态共享对象(Dynamic Shared Object)。
7.2 简单的动态链接例子
//Program1.c
#include "Lib.h"
int main(){
foobar(1);
return 0;
}
//Program2.c
#include "Lib.h"
int main(){
foobar(2);
return 0;
}
//Lib.c
#include "stdio.h"
void foobar(int i){
printf("Printing from Lib.so %d\n",i);
}
//Lib.h
#ifndef LIB_H
#define LIB_H
void foobar(int i);
#endif
使用方法:
gcc -fPIC -shared -o Lib.so Lib.c
gcc -o Program1 Program1.c ./Lib.so
gcc -o Program2 Program2.c ./Lib.so
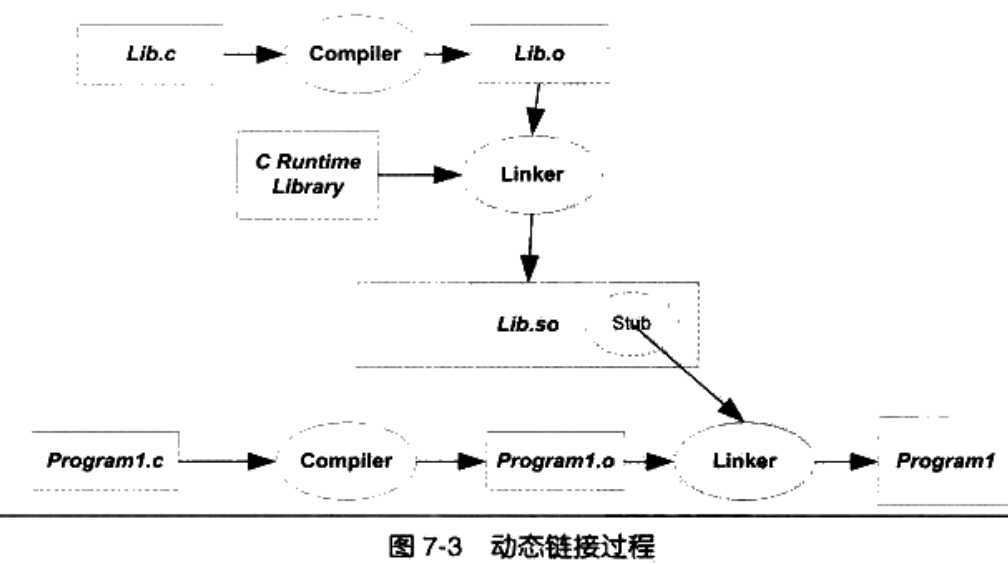
从这张图片中,我们可以看到,貌似Lib.so也参与了链接过程,这是为什么呢?原来,在静态链接中,目标文件直接参与了链接,地址进行了重定位。在动态链接中,只是进行了标记,实质上还是在运行中进行链接的。
下面我们来看下动态链接程序在运行时的地址空间分布:
对于动态链接来讲,分为可执行文件和动态共享库,首先我们需要在Lib.c中加入sleep函数,即:
//Lib.c
#include "stdio.h"
void foobar(int i){
printf("Printing from Lib.so %d\n",i);
sleep(-1);
}
然后重新编译,看进程的虚拟地址空间分布:
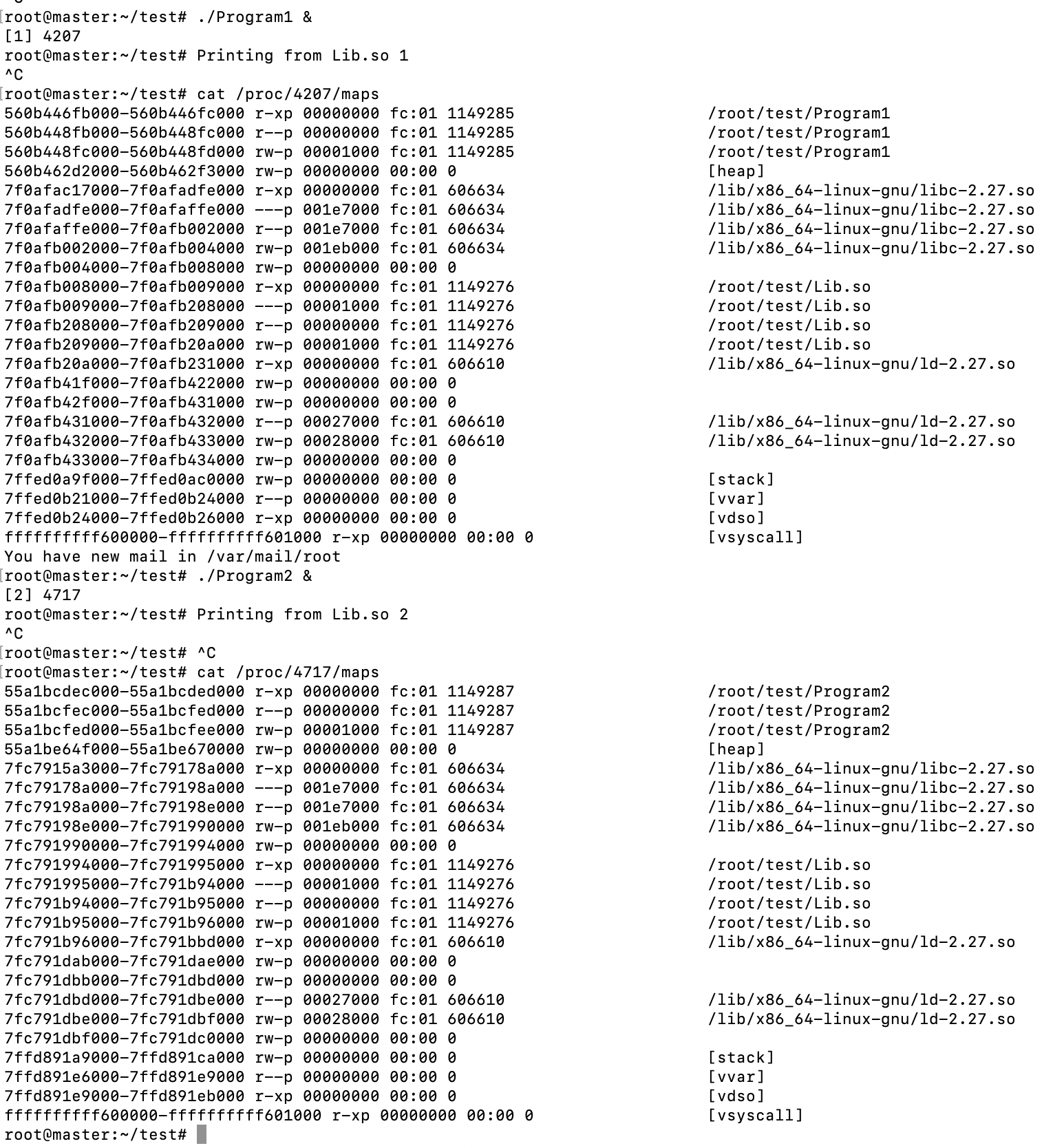
可以看到,二者被操作系统用同样的方法映射到进程中。
我们再次使用readelf -l Lib.so来查看装载属性:
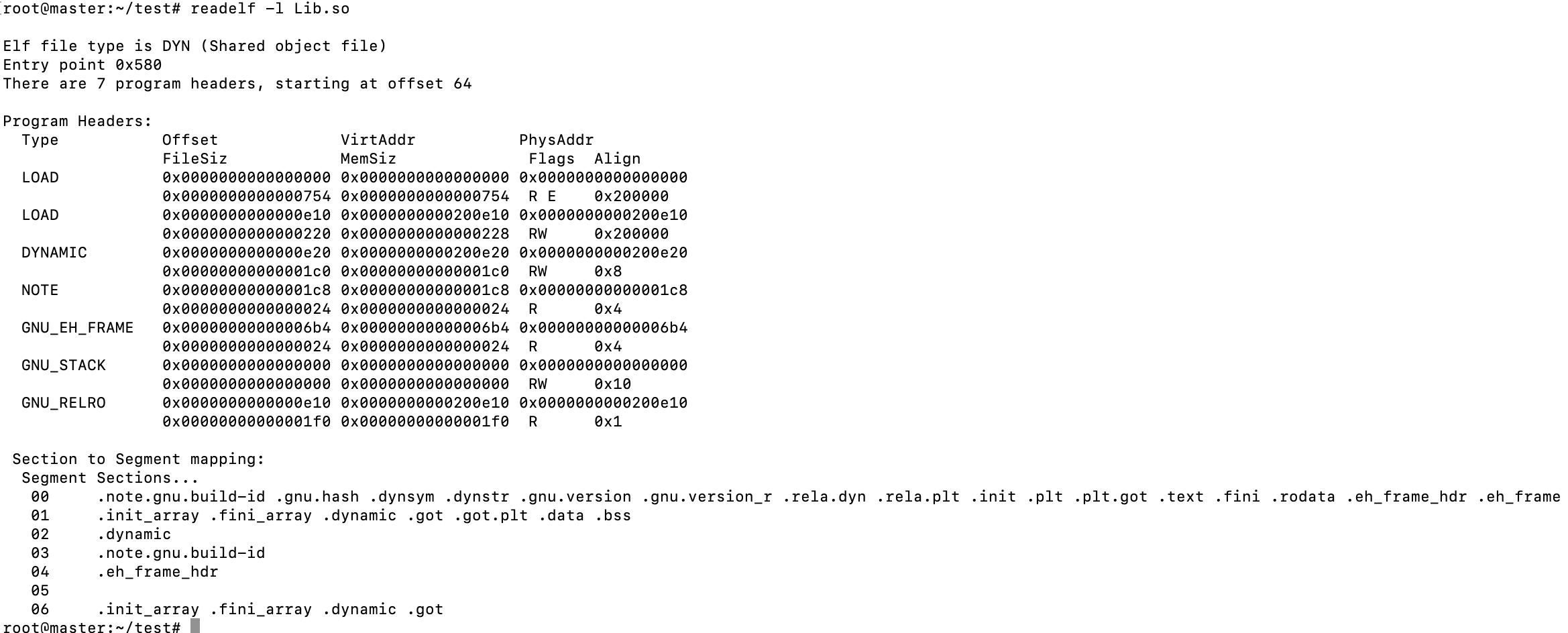
我们竟然看到是从0开始的,这明显是无效地址,我们来推断:共享对象的最终装载地址在编译时不确定,在装载时动态分配一块空间给相应的共享对象。
下面我们来进行验证。
7.3 地址无关代码
共享对象在装载的时候,我们如何确定它在进程虚拟地址空间中的位置?
如果我们采用固定装载地址的话,我们第一个面临的问题就是共享对象地址冲突的问题。 比如模块A占用0x1000-0x2000,B占用0x2000-0x3000,如果一个人开发一个程序,使用了模块B,可能会把0x1000-0x2000分给C,那么就出问题了。
为了解决地址冲突的问题,我们要让共享对象在编译时不能假设自己在进程虚拟地址空间中的位置。(与之对应的是,可执行文件在编译的时候基本就可以知道自己在虚拟地址空间中的位置)
于是我们引入了装载时重定位:即在装载时对所有的绝对地址的引用不做重定位,在装载的时候在做。假设foobar相对于代码段的位置是0x100,当该模块的地址装载在0x1000,那么foobar的地址是0x1100。
但是事情并没有得到完美的解决,指令无法在多个进程之间共享,我们需要去寻找更加牛逼的方法。在来看我们的目的,希望程序模块中共享的指令不因装载地址的改变而改变,所以我们需要把共享模块中需要修改的部门抽取出来,和数据模块放在一块,然后指令部门就抽取出来了,这就叫做指令无关码(PIC,Position-Independent Code)。
在此之前,我们需要分析模块中各种类型地址的引用方式:
在此之前,我们需要分析模块中各种类型地址的引用方式:
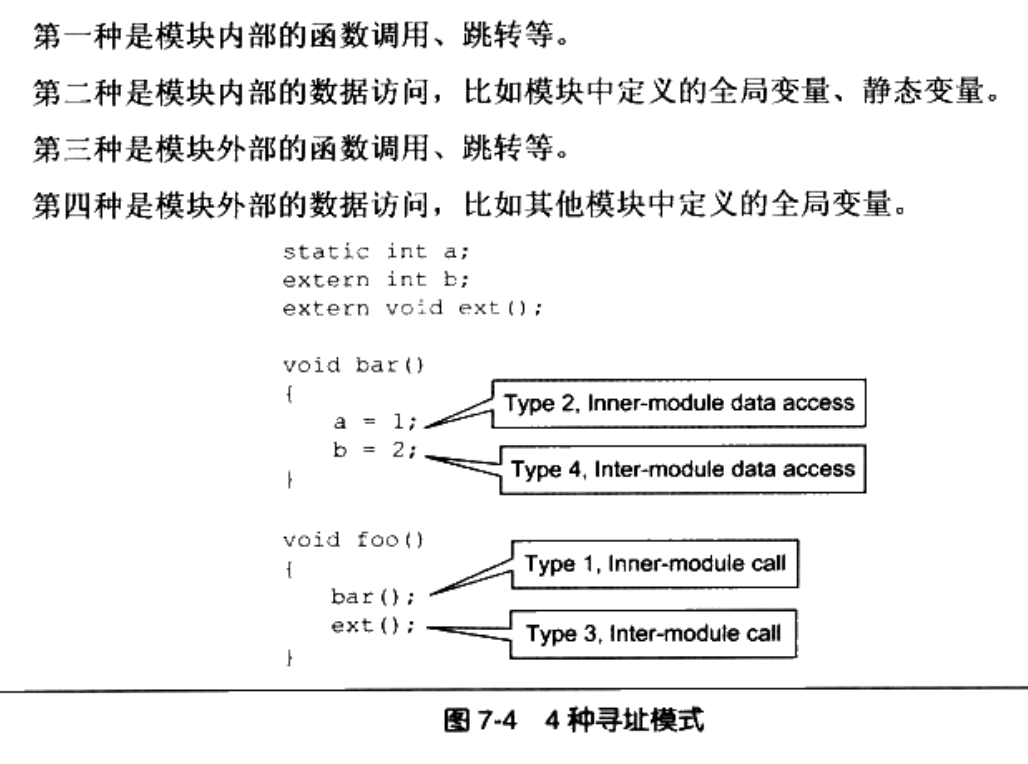
总结一下指令无关码:

7.4 延迟绑定(PLT)
上面的地址无关码这个话题告一段落,下面我来看下下一个话题,延迟绑定。
延迟绑定主要想解决的问题是动态链接造成的性能损耗的问题,我们再来考虑下,如果我们真的动态链接的话,那么我们真的需要全部都进行链接吗?代码的所有部分都会被访问吗?不尽然吧。我们可不可以在用到的时候,在进行链接呢?这就引入了延迟绑定的概念,这个概念在软件开发中也是很有用的,Java中有一个叫做懒汉模式。
7.5 动态链接相关结构
我们在上面了解了动态链接的基本原理,现在我们尝试进行实现动态链接。
在动态链接情况下,操作系统在装载完可执行文件后,会先启动一个动态链接器(Dynamic Linker)。ld.so也是一个共享对象,同样需要加载到进程的地址空间中,然后由动态链接器对可执行文件进行链接,完成之后,程序才可以真正执行。
那么问题来了,是不是所有的动态链接器都是/lib/ld.so呢,实际上并不是(因为环境不同),这个是由ELF文件中的.interp段来决定的,我们可以使用objdump -s a.out来查看:
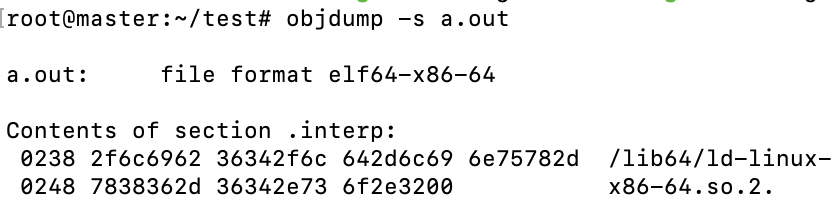
可以看到在我的机器上是/lib64/ld-linux-x86-64.so.2。我们找到了动态链接器,接着我们看dynamic段,这个段里面保存了动态链接器需要的基本信息,比如依赖的共享对象,动态链接符号表的位置,动态链接重定位表的位置,共享对象初始化代码的地址,结构定义在elf.h中。
/* Dynamic section entry. */
typedef struct
{
Elf32_Sword d_tag; /* Dynamic entry type */
union
{
Elf32_Word d_val; /* Integer value */
Elf32_Addr d_ptr; /* Address value */
} d_un;
} Elf32_Dyn;
我们使用readelf -d Lib.so来查看dynamic段的内容。
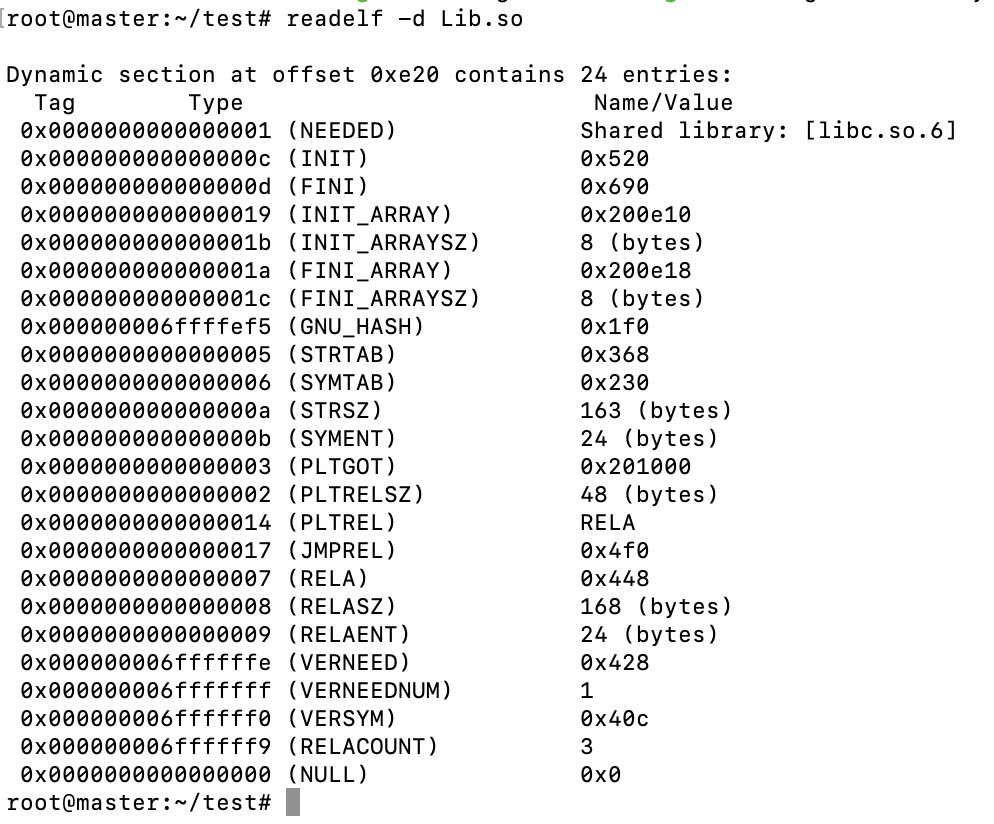
我们还可以使用,ldd Program1来查看该程序依赖哪些共享模块。

下面我们来看动态符号表。和静态链接中的符号表systab相似,我们定义了动态符号表(Dynamic table)来表示动态连接中的模块之间的导入导出关系。除此之外,我们还需要辅助表dynstr表。
我们继续看,动态链接重定位表,使用readelf -r Lib.so 和readelf -S Lib.so来查看:
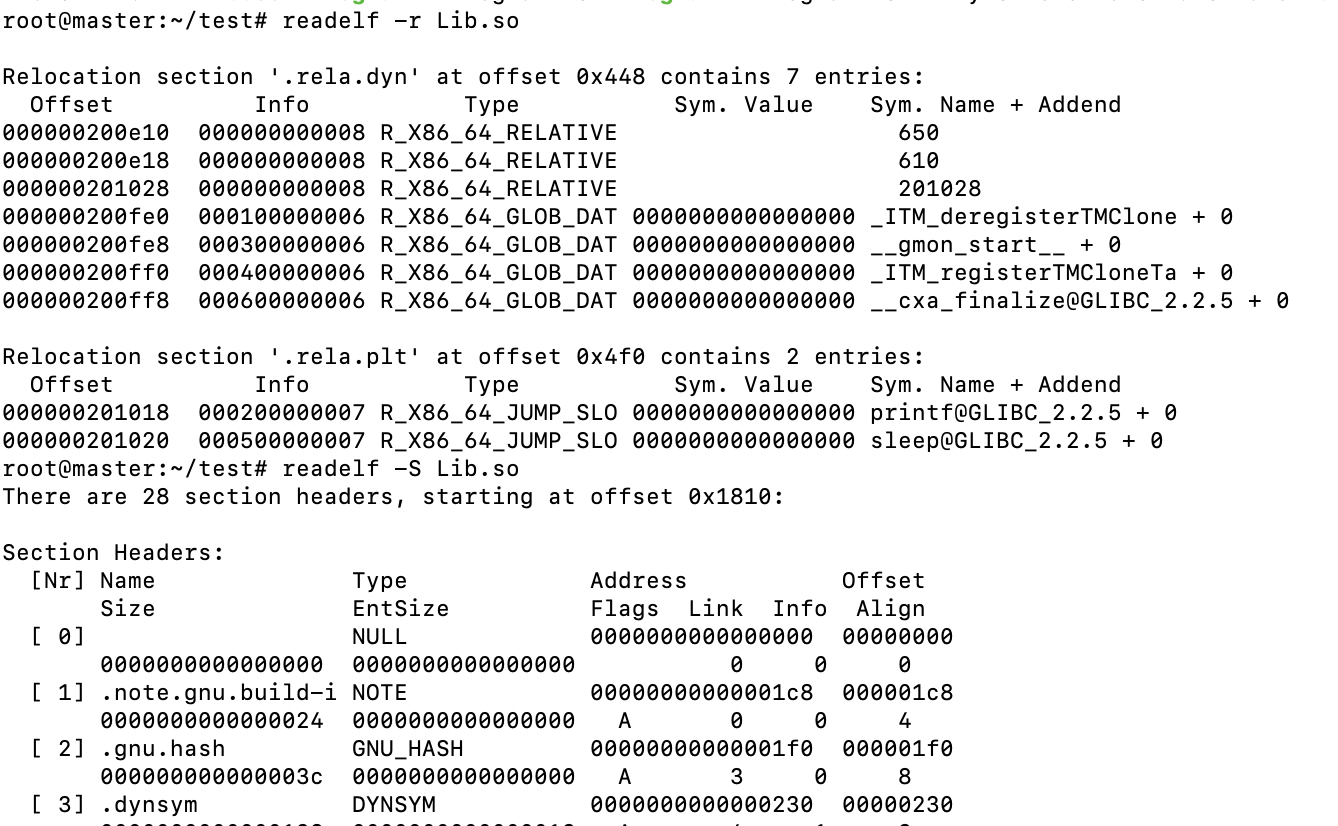
结构图如下所示:

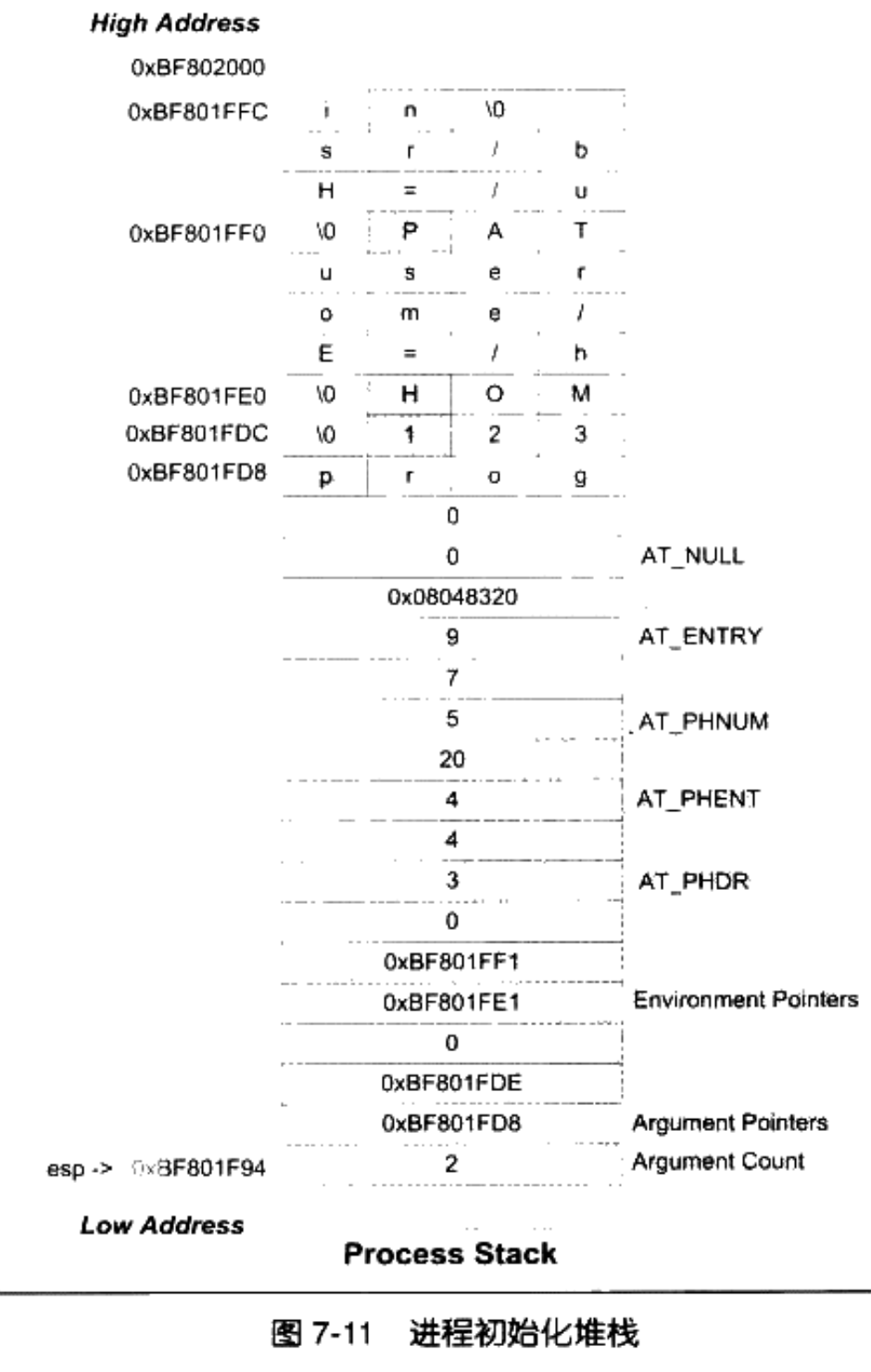
我们接着看动态链接时进程堆栈初始化信息:
进程初始化的时候,堆栈里面保存了关于进程执行环境和命令行参数等信息,以及动态链接器需要的辅助信息数组(Auxiliary Vector)。
/* Auxiliary vector. */
/* This vector is normally only used by the program interpreter. The
usual definition in an ABI supplement uses the name auxv_t. The
vector is not usually defined in a standard <elf.h> file, but it
can't hurt. We rename it to avoid conflicts. The sizes of these
types are an arrangement between the exec server and the program
interpreter, so we don't fully specify them here. */
typedef struct
{
uint32_t a_type; /* Entry type */
union
{
uint32_t a_val; /* Integer value */
/* We use to have pointer elements added here. We cannot do that,
though, since it does not work when using 32-bit definitions
on 64-bit platforms and vice versa. */
} a_un;
} Elf32_auxv_t;
我们可以写个小程序来打印堆栈中的初始化信息:
//auxiliary_vestor.c
#include<stdio.h>
#include<elf.h>
int main(int argc, char * argv[])
{
int *p = (int *)argv;
int i;
Elf32_auxv_t *aux;
printf("Argument count:%d\n", *(p-1) );
for(i=0; i<*(p-1); i++)
{
printf("Argument %d : %s\n", i, *(p+i) );
}
p += i;
p++;
printf("Environment:\n");
while(*p)
{
printf("%s\n", *p);
p++;
}
p++;
printf("Auxiliary Vectors:\n");
aux = (Elf32_auxv_t *)p;
while(aux->a_type != AT_NULL)
{
printf("Type: %02d Value: %x\n", aux->a_type, aux->a_un.a_val);
aux++;
}
return 0;
}
然后编译:gcc -g auxiliary_vestor.c -o auxiliary_vestor
最后运行:./auxiliary_vestor haojs
初始化堆栈如下图所示:
7.6 动态链接的步骤和实现
我们在前面学习了动态链接的基本知识,下面我们开始着手实现。主要是分为3步,第一步是启动动态链接器本身,然后装载所需要的共享对象,最后是重定位和初始化。
我们首先来看动态链接器自举,我们需要思考这个问题,动态链接器这个共享对象是由谁来重定位的问题呢?鸡生蛋,蛋生鸡的问题啊。我们必须打破这个循环,首先动态链接器不可以依赖其他共享对象,然后动态链接器依赖的需要的全局变量和和静态变量的重定位工作由自身完成。
然后我们来看共享对象的装载。自举完成后,所有的符号都合并到全局符号表中。
我们接着来看重定位和初始化。
最后我们来看Linux动态链接器的实现。
4 库与运行库
10 内存
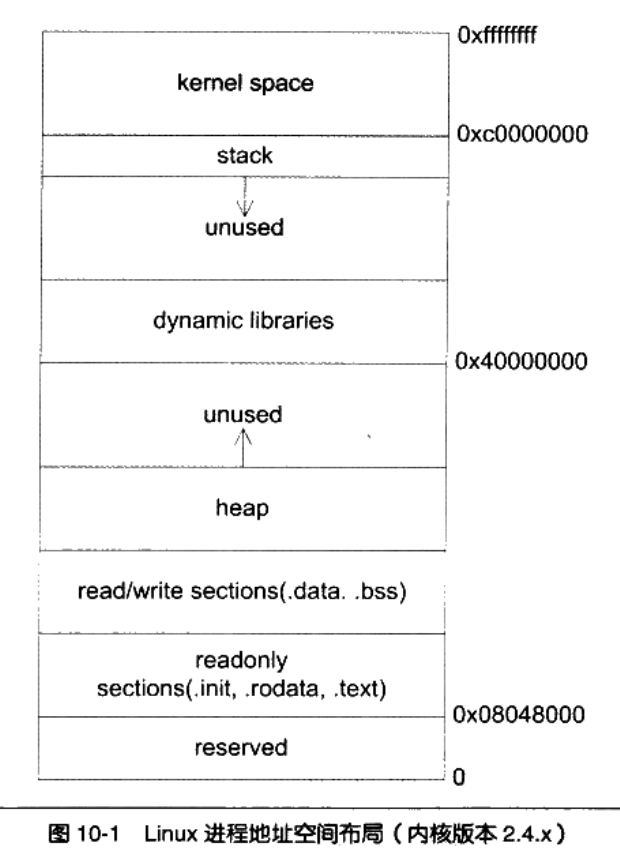
10.1 程序的内存布局
一般情况下,我们的内存可以分为:
-
内核空间
-
用户空间
-
栈:用于维护函数调用的上下文;
-
堆:用来动态分配的区域;
-
可执行文件映像:存储着可执行文件在内存里的映像,装载时将可执行文件的内存读取到这里;
-
保留区:不是单一的,比如NULL是受保护的。
10.2 栈与调用惯例
我们为什么要用栈?–主要是为了处理函数调用。
栈里面的2个重要概念,esp(栈指针)和ebp(帧指针),堆栈一般包含下面的内容:
-
函数的返回地址和参数;
-
临时变量:函数的非静态局部变量;
-
保存的上下文:在函数调用前后需要保持不变的寄存器。
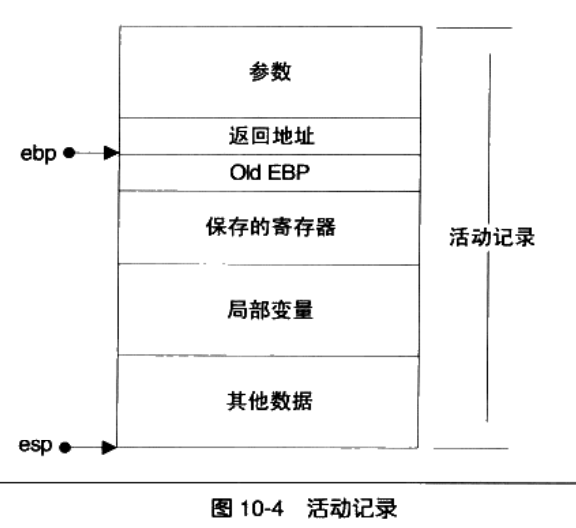
稍微解释下这个图:ebp固定不变,指向调用该函数前ebp的值,用于函数返回时使用。ebp-4是函数的返回地址,ebp-8,ebp-12是参数等。
下面我们来看下函数调用究竟是怎么实现的:
-
把所有或者一部分参数压入栈中;
-
把当前指令的下一条指令的地址压入栈中;
-
调到函数体执行;
- push ebp; ebp压入栈中(俗称old ebp)
- mov ebp,esp;ebp=esp(ebp指向栈顶,也即old ebp)
- sub esp,XXX;在栈上分配空间
- push XXX:保存寄存器的值,因为有些函数要求寄存器在调用前后不能发生改变
- pop XXX:恢复保存的寄存器
- mov esp,ebp:恢复ESP同时回收局部变量空间
- pop ebp:恢复ebp
- ret:取出返回地址
下面我们来举个例子:
int foo(){
return 123;
}
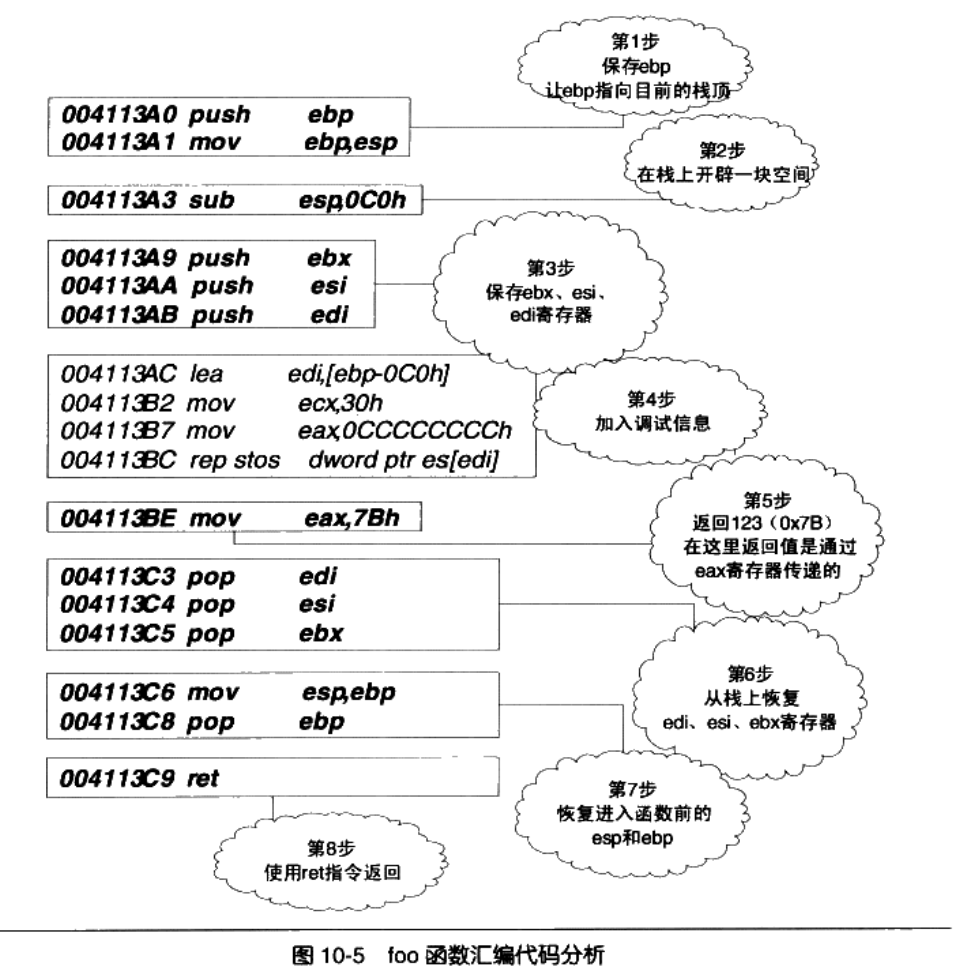
不知道大家发现问题没,在上面的过程中,有些我们必须进行约定,才能正常的处理函数之间的调用,标准如下所示:

我们再来举个例子:
void f(int x,int y){
return;
}
int main(){
f(1,3);
return 0;
}
函数的实际执行流程如下所示:
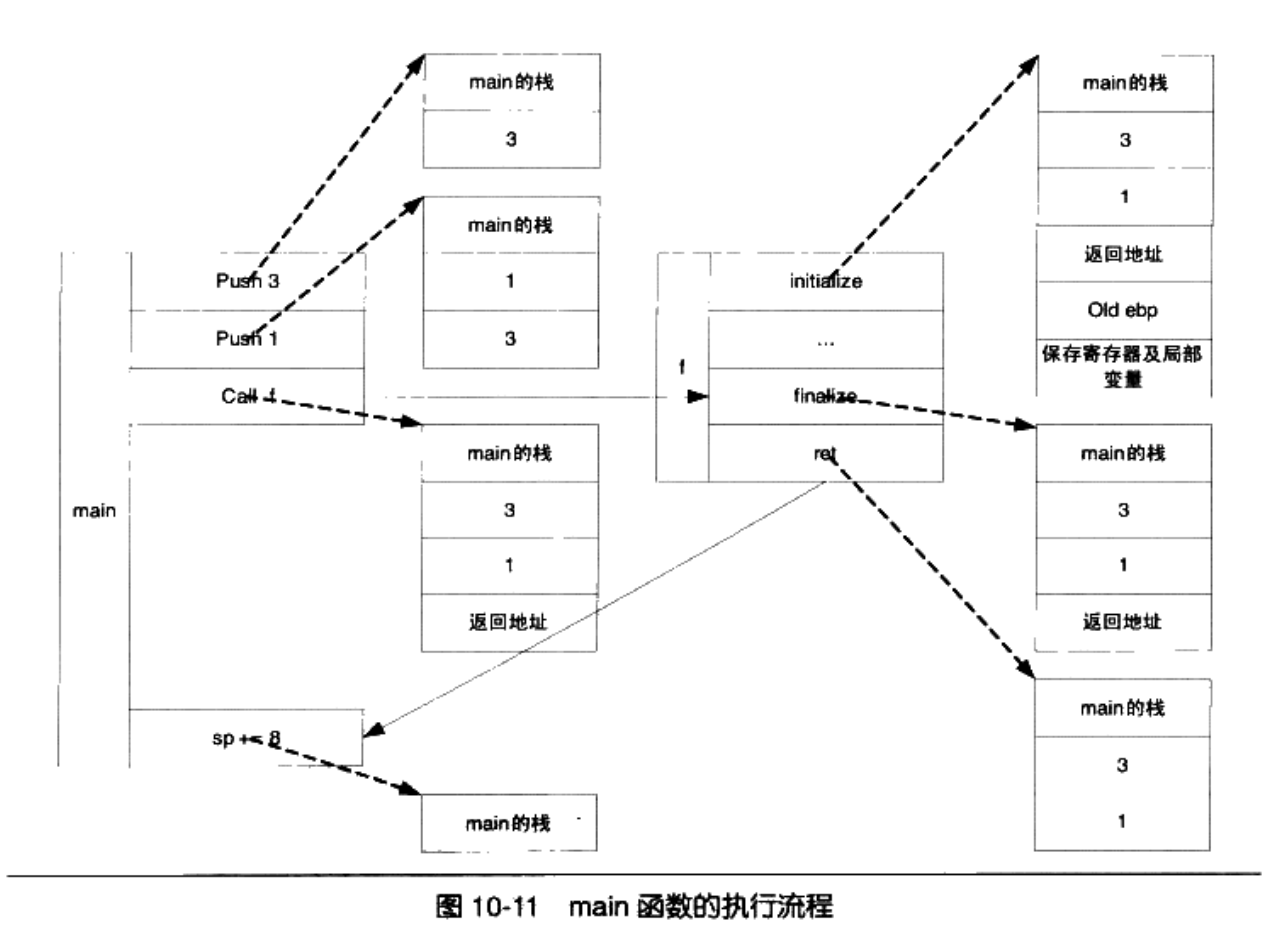
到现在,我们还有一个非常棘手的问题,就是函数的返回值我们需要怎么进行处理:
我们分为以下几类情况:
* 返回值小于4个字节:把值存储在eax寄存器中,然后从eax中读取;
* 大于4小于8:eax+edx;
* 大于8字节:这才是复杂的,可以明确的是肯定在寄存器中存地址;
我们通过一个实例来研究:

可以明确的是128字节是不可能在eax里存下的,所以肯定是地址,步骤如下:
-
main函数在栈上额外开辟一个空间,成为temp
-
将temp的地址作为隐藏参数传递给return_test函数
-
return_test把数据拷贝给temp,并把temp的地址放在eax寄存器中
-
return_test返回后,main函数将eax执行的temp对象拷贝给n
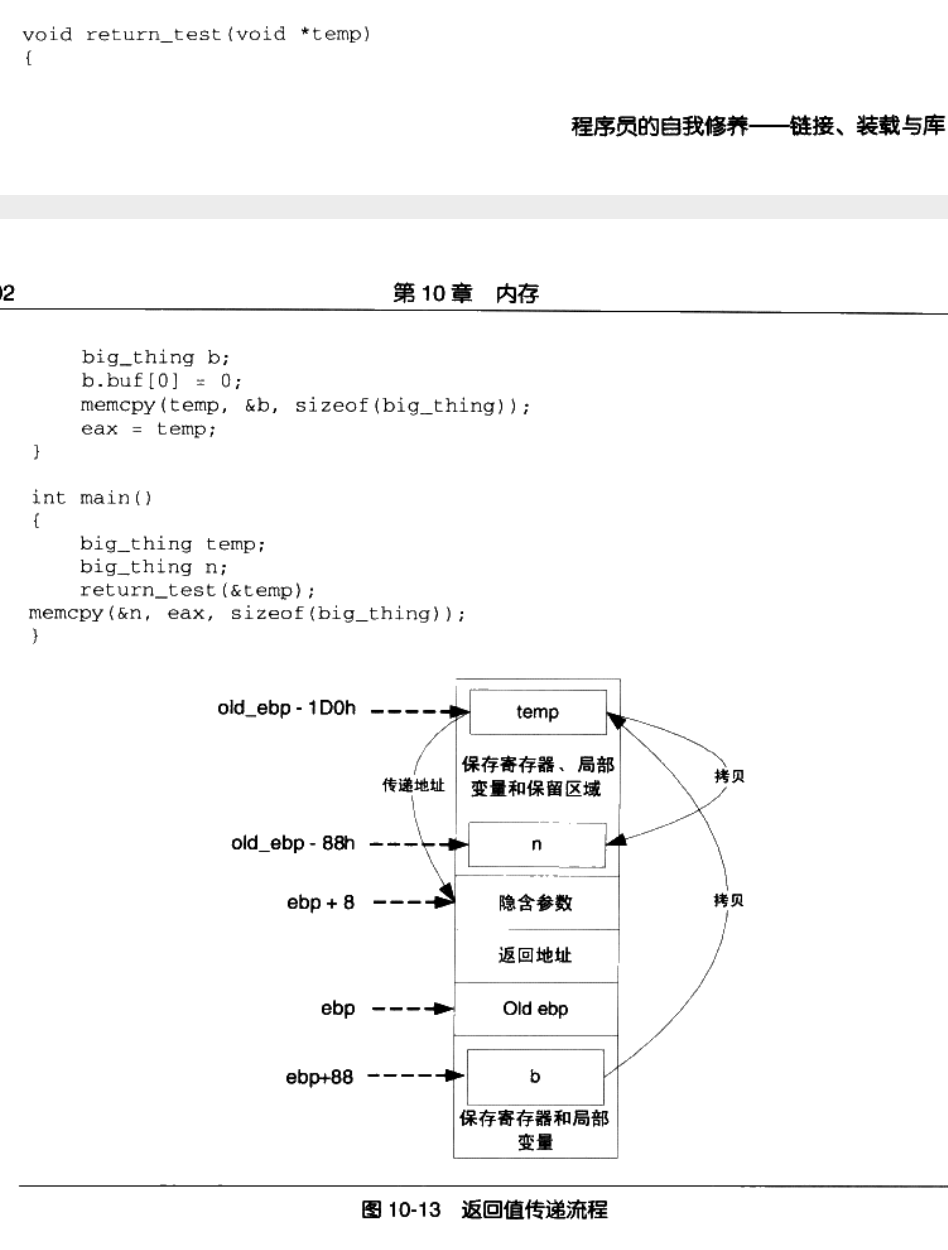
我们可以看到,2次拷贝还是十分浪费空间的,我们应该尽量减少返回大对象。
10.3 堆与内存管理
为什么我们有了栈,还要有堆呢?
我们知道变量的声明周期会随着函数的结束而结束,如果我们想要让变量的声明周期增长,那么我们必须使用全局变量,但是全局变量的缺点也是十分的明显的,首先太多的全局变量无法维护,然后全局变量只可以在编译前进行分配内存,无法在运行时分配内存。所以我们引入了堆。
在c语言中,我们是通过malloc来实现的,我们的思路有2个,一是由操作系统来做,但是缺点也很明显,会影响性能,而是由程序来实现。做法是程序向内核申请一块内存,然后由程序把这段内存分配下去。简而言之,就是批量申请,逐个分配。
linux系统的进程堆管理,主要依靠两个函数:brk和mmap。
int brk(void* end_data_segment);
void *mmap(void *start,
size_t length,
int prot,
int flags,
int fd,
off_t offset);
我们还有一个复杂的问题要处理,就是堆分配算法。
我们究竟要如何管理一大块连续的内存空间,按需分配,释放空间。
常见的有以下几种方法:
空闲链表:把空闲的块串成一个链表,需要的时候,拆分下来,释放的时候,合并到链表中。
位图:
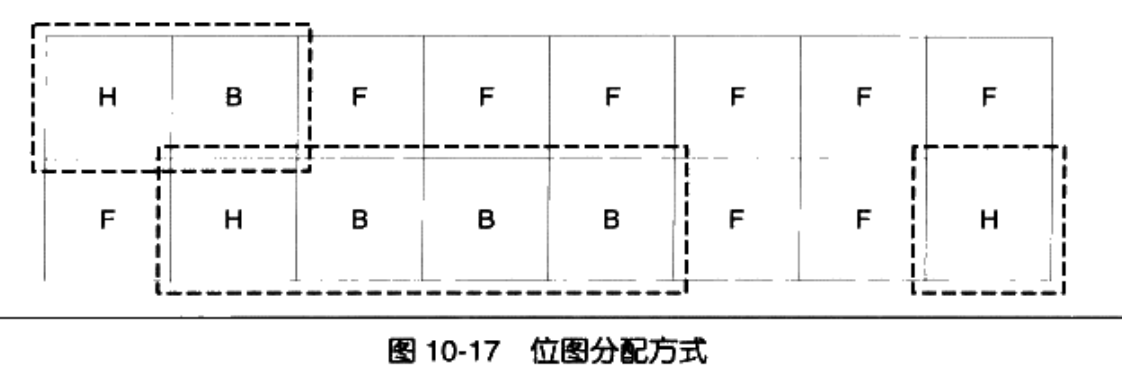
对象池:
11 虚拟存储器
内容来自深入理解计算机系统,CSAPP。
为了更好的管理存储器,操作系统提出了一个叫做虚拟存储器的概念。我们为什么需要理解虚拟存储器呢?
虚拟存储器是十分核心的,强大的,又是危险的。
我们将尝试描述虚拟存储器的工作机制,然后使用和管理虚拟存储器。
11.1 物理和虚拟寻址
我们先来看物理和虚拟寻址。内存被划分为一个大数组,有其编号。早期的系统直接使用物理地址,后期的系统使用虚拟地址来寻址。
在虚拟寻址中,CPU通过生成一个虚拟地址来访问主存,虚拟地址被送到存储器前需要先转换为物理地址,这部分叫做MMU,内存管理单元(其中有各种表,由操作系统来进行管理)。
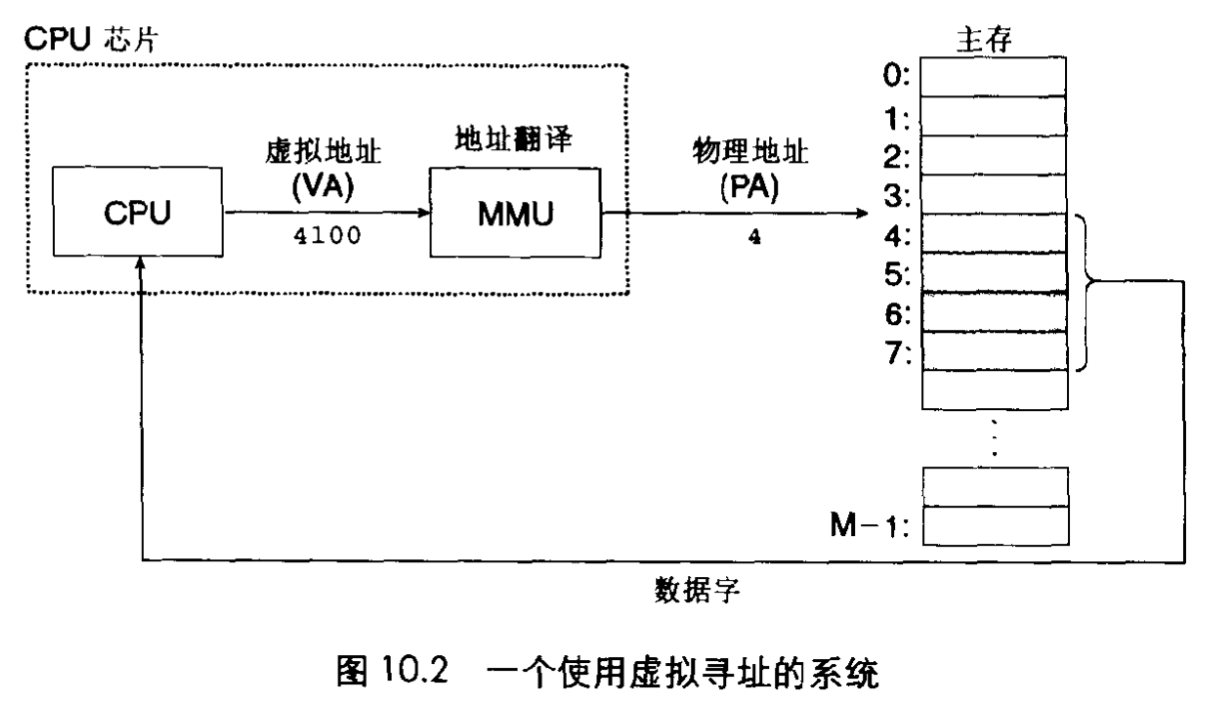
11.2 地址空间
地址空间主要有三种,分别是虚拟地址空间,线性地址空间和物理地址空间。
11.3 虚拟内存作为缓存的工具
这句话概括了虚拟内存的作用。虚拟内存是一个由存放在磁盘上的N个连续的字节大小的单元组成的数组,每字节有一个唯一的虚拟地址,这个地址是数组的的索引,内容在内存中。虚拟内存被切割为页(Virtual Page),物理存储器划分为页祯。
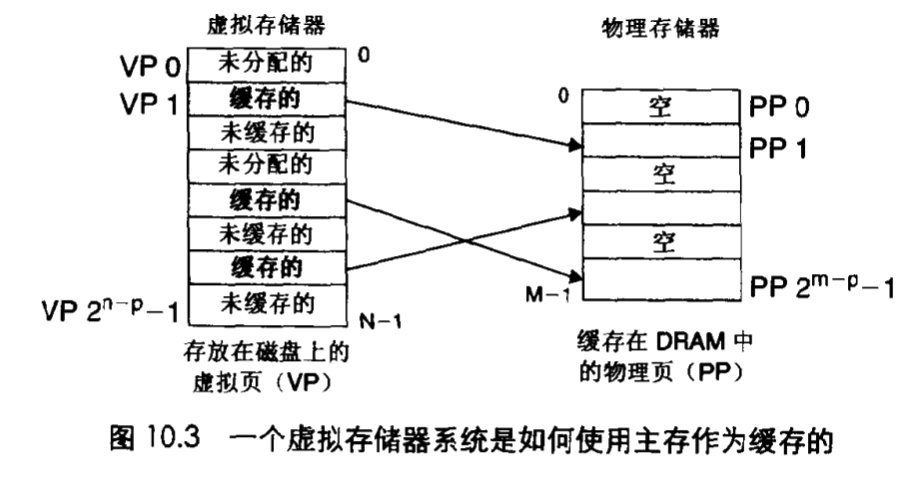
下面我们来看页表的概念:
操作系统必须维护虚拟页和物理页,虚拟页和磁盘之间的关系。页表就是一个PTE(Page table entry,页表数目)的数组。

接下来是页命中的概念,直接使用就行了,麻烦的是缺页的概念:
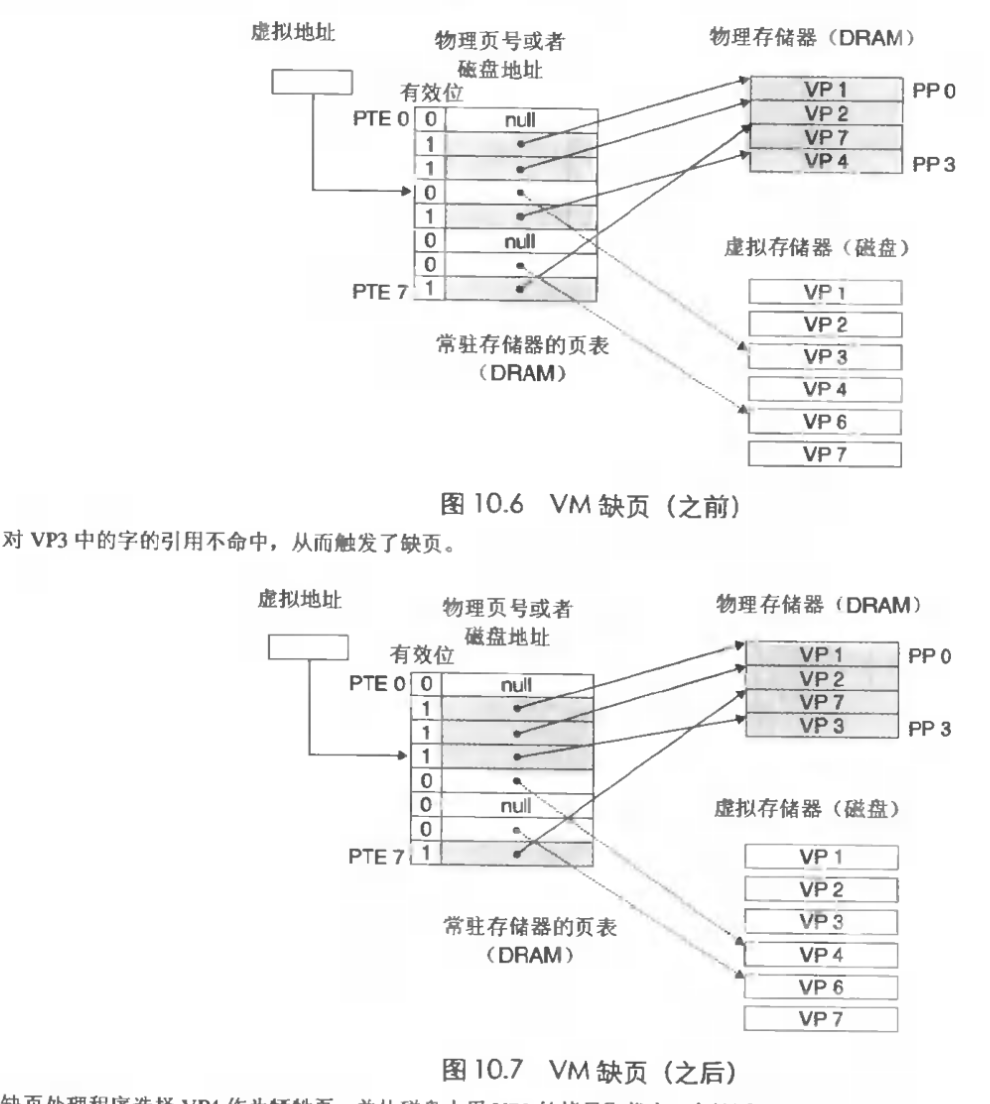
11.4 虚拟存储器作为存储器管理的工具
11.6 地址翻译
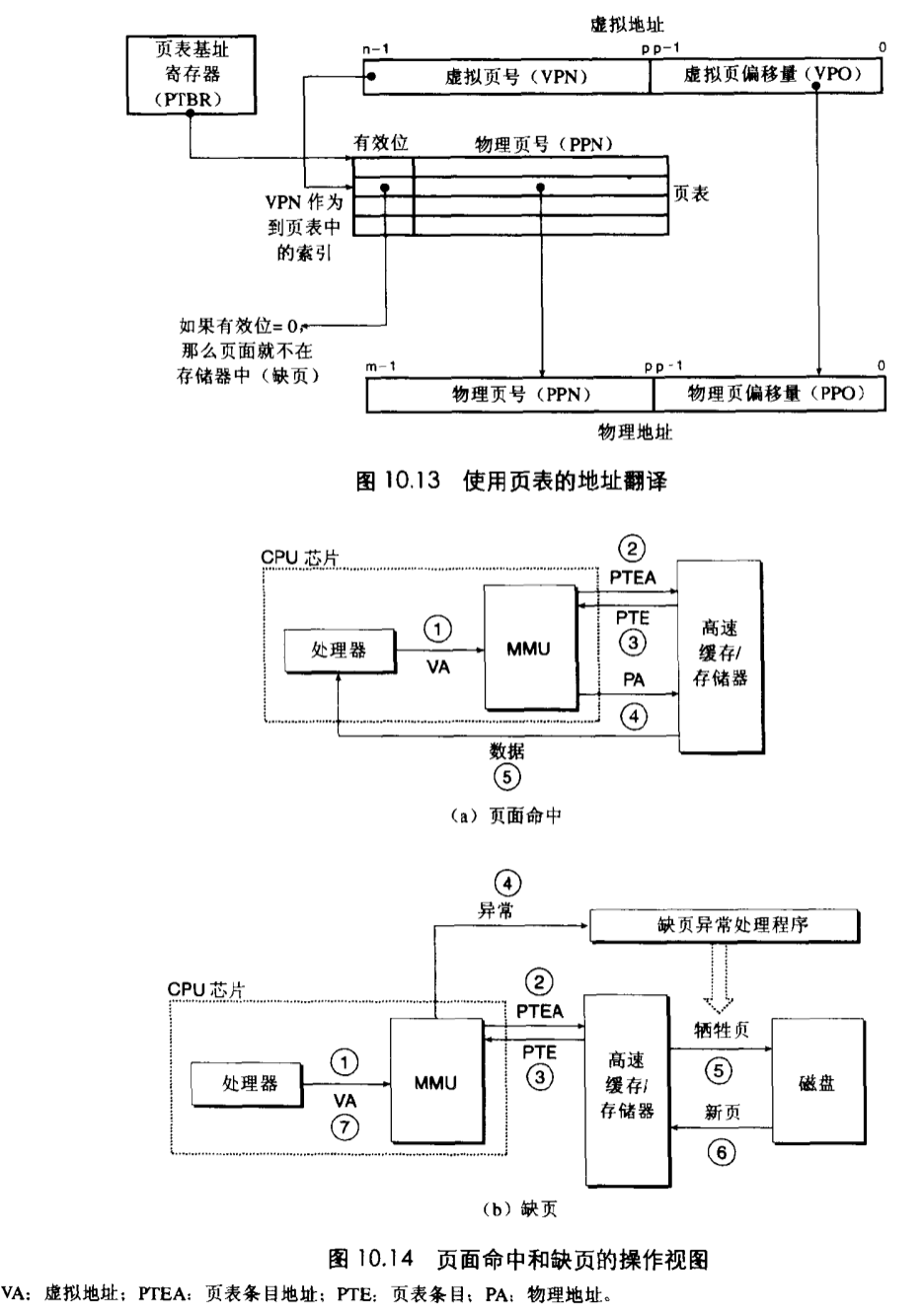
12 系统调用
12.1 系统调用介绍
我们首先来看看什么是系统调用?
为了让应用程序访问系统资源。
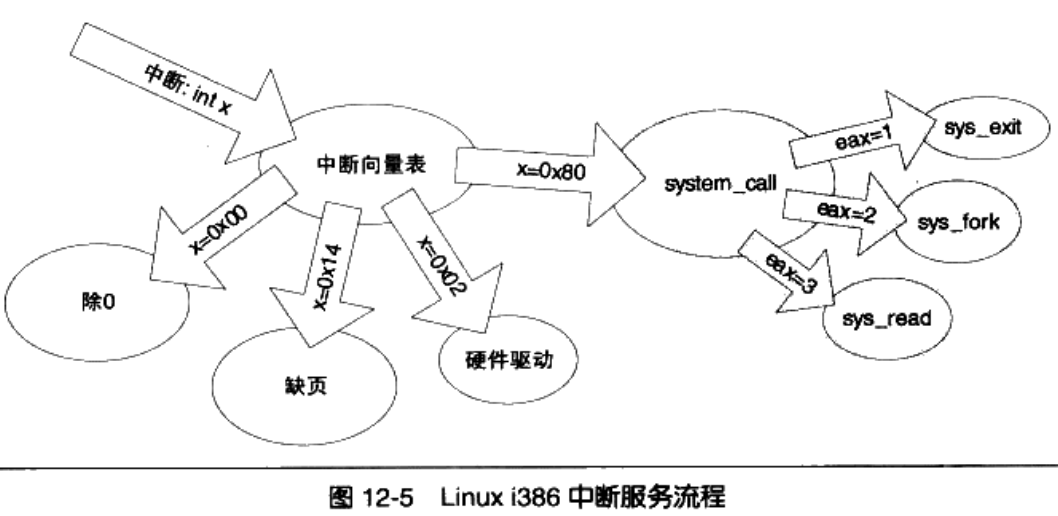
具体来看下,EAX寄存器用来表示系统调用的接口号,具体的见下表。Linux系统差不多有300多个系统调用。
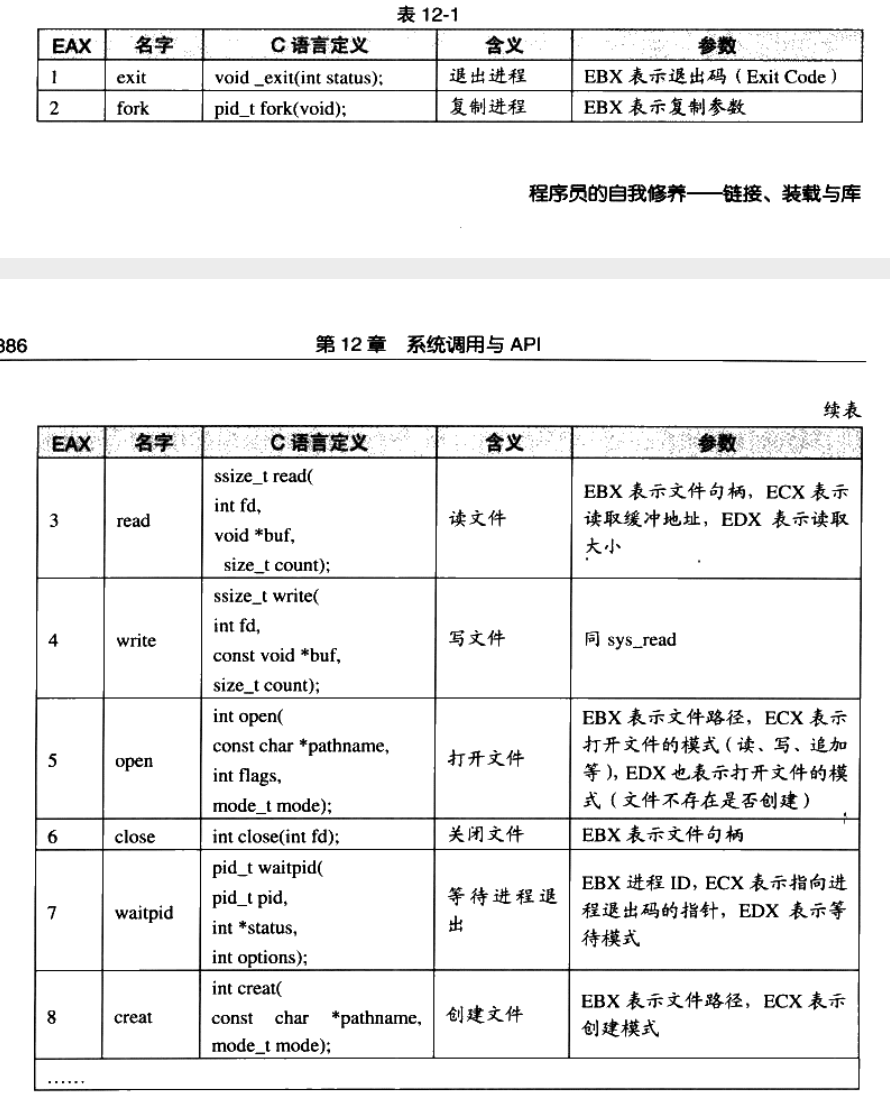
12.2 系统调用的原理
下面我们来看下系统调用的原理。用户模式和内核模式,由用户模式进入进入内核模式,有2中方法,一是轮询,2是信号。
中断有2个属性,1是中断号,2是中断处理程序,在内核中,有一个数组被称为中断向量表,保存了所有的中断类型。
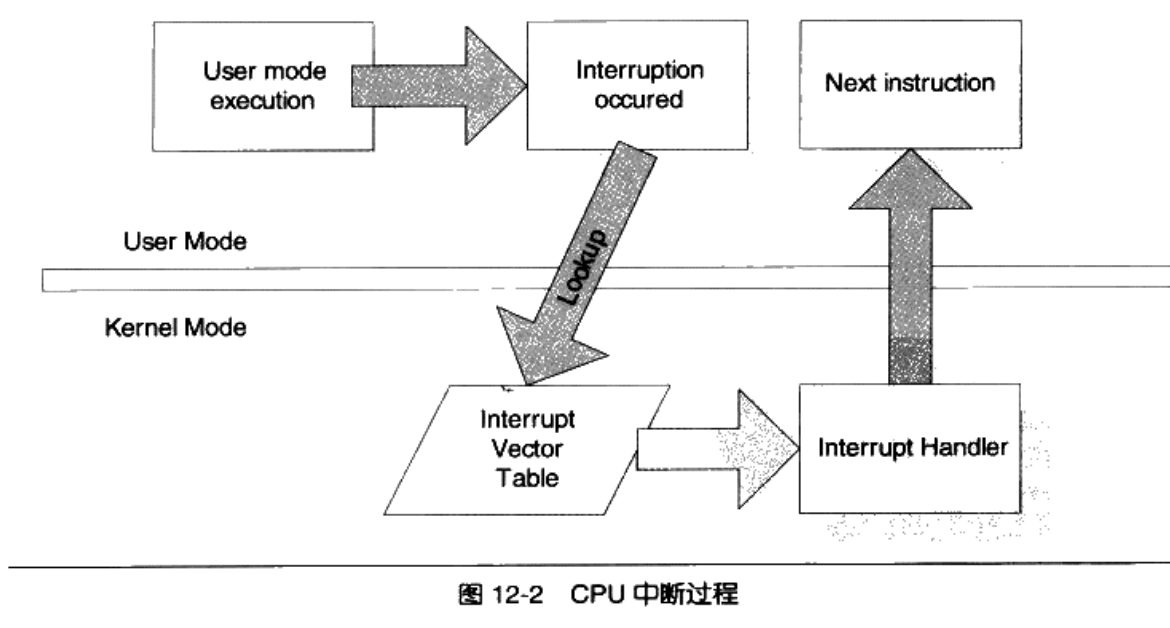
我们用中断号+系统调用号来表示一个具体的中断。一般int指令表示进入中断,0x80表示系统调用。
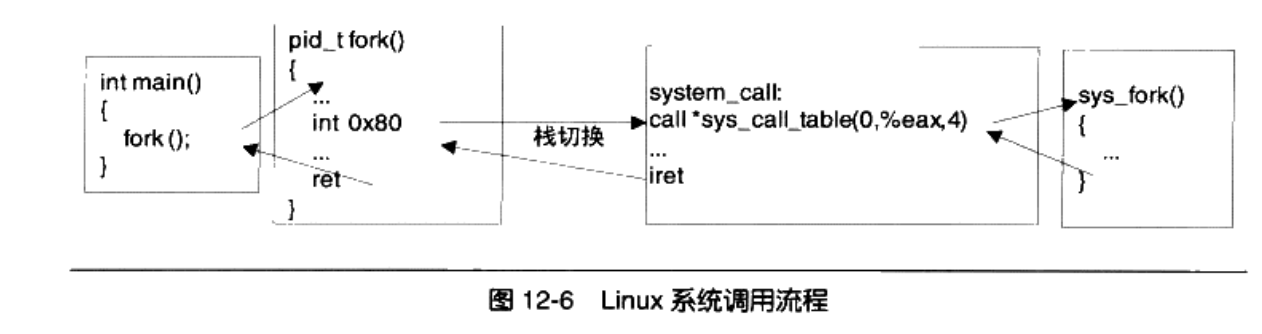
下面我们来看下基于int的Linux经典系统调用:
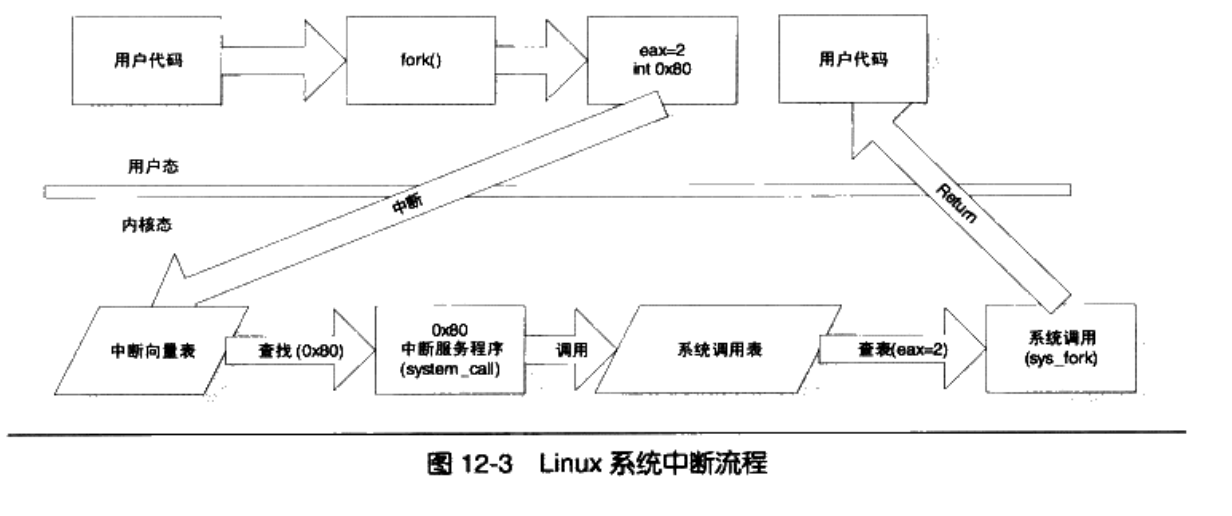
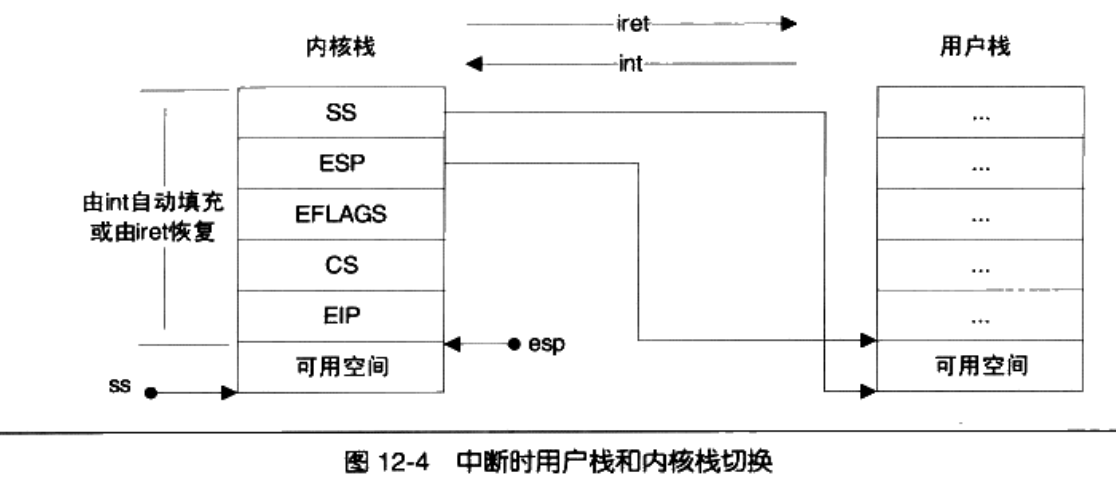
第一步是触发中断,第二步是切换堆栈,具体来讲,我们需要从用户太的堆栈切换到内核态的堆栈,需要如下步骤:
-
保存当前的ESP和SS的值;
-
将ESP和SS的值设置为内核栈的相应值;
- 找到当前进程的内核栈(每一个进程都有自己的内核栈)
- 在内核中依次压入用户的寄存器SS,ESP,EFLAGS,CS,EIP
- 恢复原来的ESP和SS的值(iret)
第三步是中断处理程序,

附录
ELF常见段:

常见开发工具命令行:







