
前言
本篇文章主要学习http的相关知识。主要学习以下内容。
这方面最经典的书应该是《Unix网络编程了》。
1. Http的前世今生
HTTP (Hypertext transfer protocol) 翻译成中文是超文本传输协议,是互联网上重要的一个协议,由欧洲核子研究委员会CERN的英国工程师 Tim Berners-Lee v发明的,同时,他也是WWW的发明人,最初的主要是用于传递通过HTML封装过的数据。在1991年发布了HTTP 0.9版,在1996年发布1.0版,1997年是1.1版,1.1版也是到今天为止传输最广泛的版本(初始RFC 2068 在1997年发布, 然后在1999年被 RFC 2616 取代,再在2014年被 RFC 7230 /7231/7232/7233/7234/7235取代),2015年发布了2.0版,其极大的优化了HTTP/1.1的性能和安全性,而2018年发布的3.0版,继续优化HTTP/2,激进地使用UDP取代TCP协议,目前,HTTP/3 在2019年9月26日 被 Chrome,Firefox,和Cloudflare支持,所以我想写下这篇文章,简单地说一下HTTP的前世今生,让大家学到一些知识,并希望可以在推动一下HTTP标准协议的发展。
1.1 HTTP 0.9 / 1.0
0.9和1.0这两个版本,就是最传统的 request – response的模式了,HTTP 0.9版本的协议简单到极点,请求时,不支持请求头,只支持 GET 方法,没了。HTTP 1.0 扩展了0.9版,其中主要增加了几个变化:
- 在请求中加入了HTTP版本号,如:
GET /coolshell/index.html HTTP/1.0 - HTTP 开始有 header了,不管是request还是response 都有header了。
- 增加了HTTP Status Code 标识相关的状态码。
- 还有
Content-Type可以传输其它的文件了。
我们可以看到,HTTP 1.0 开始让这个协议变得很文明了,一种工程文明。因为:
- 一个协议有没有版本管理,是一个工程化的象征。
- header是协议可以说是把元数据和业务数据解耦,也可以说是控制逻辑和业务逻辑的分离。
- Status Code 的出现可以让请求双方以及第三方的监控或管理程序有了统一的认识。最关键是还是控制错误和业务错误的分离。
(注:国内很多公司HTTP无论对错只返回200,这种把HTTP Status Code 全部抹掉完全是一种工程界的倒退)
但是,HTTP1.0性能上有一个很大的问题,那就是每请求一个资源都要新建一个TCP链接,而且是串行请求,所以,就算网络变快了,打开网页的速度也还是很慢。所以,HTTP 1.0 应该是一个必需要淘汰的协议了。
1.2 HTTP/1.1
HTTP/1.1 主要解决了HTTP 1.0的网络性能的问题,以及增加了一些新的东西:
- 可以设置
keepalive来让HTTP重用TCP链接,重用TCP链接可以省了每次请求都要在广域网上进行的TCP的三次握手的巨大开销。这是所谓的“HTTP 长链接” 或是 “请求响应式的HTTP 持久链接”。英文叫 HTTP Persistent connection. - 然后支持pipeline网络传输,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。(注:非幂等的POST 方法或是有依赖的请求是不能被pipeline化的)
- 支持 Chunked Responses ,也就是说,在Response的时候,不必说明
Content-Length这样,客户端就不能断连接,直到收到服务端的EOF标识。这种技术又叫 “服务端Push模型”,或是 “服务端Push式的HTTP 持久链接” - 还增加了 cache control 机制。
- 协议头注增加了 Language, Encoding, Type 等等头,让客户端可以跟服务器端进行更多的协商。
- 还正式加入了一个很重要的头——
HOST这样的话,服务器就知道你要请求哪个网站了。因为可以有多个域名解析到同一个IP上,要区分用户是请求的哪个域名,就需要在HTTP的协议中加入域名的信息,而不是被DNS转换过的IP信息。 - 正式加入了
OPTIONS方法,其主要用于 CORS – Cross Origin Resource Sharing 应用。
HTTP/1.1应该分成两个时代,一个是2014年前,一个是2014年后,因为2014年HTTP/1.1有了一组RFC(7230 /7231/7232/7233/7234/7235),这组RFC又叫“HTTP/2 预览版”。其中影响HTTP发展的是两个大的需求:
- 一个需要是加大了HTTP的安全性,这样就可以让HTTP应用得广泛,比如,使用TLS协议。
- 另一个是让HTTP可以支持更多的应用,在HTTP/1.1 下,HTTP已经支持四种网络协议:
- 传统的短链接。
- 可重用TCP的的长链接模型。
- 服务端push的模型。
- WebSocket模型。
自从2005年以来,整个世界的应用API越来多,这些都造就了整个世界在推动HTTP的前进,我们可以看到,自2014的HTTP/1.1 以来,这个世界基本的应用协议的标准基本上都是向HTTP看齐了,也许2014年前,还有一些专用的RPC协议,但是2014年以后,HTTP协议的增强,让我们实在找不出什么理由不向标准靠拢,还要重新发明轮子了。
1.3 HTTP/2
虽然 HTTP/1.1 已经开始变成应用层通讯协议的一等公民了,但是还是有性能问题,虽然HTTP/1.1 可以重用TCP链接,但是请求还是一个一个串行发的,需要保证其顺序。然而,大量的网页请求中都是些资源类的东西,这些东西占了整个HTTP请求中最多的传输数据量。所以,理论上来说,如果能够并行这些请求,那就会增加更大的网络吞吐和性能。
另外,HTTP/1.1传输数据时,是以文本的方式,借助耗CPU的zip压缩的方式减少网络带宽,但是耗了前端和后端的CPU。这也是为什么很多RPC协议诟病HTTP的一个原因,就是数据传输的成本比较大。
其实,在2010年时,Google 就在搞一个实验型的协议,这个协议叫SPDY,这个协议成为了HTTP/2的基础(也可以说成HTTP/2就是SPDY的复刻)。HTTP/2基本上解决了之前的这些性能问题,其和HTTP/1.1最主要的不同是:
- HTTP/2是一个二进制协议,增加了数据传输的效率。
- HTTP/2是可以在一个TCP链接中并发请求多个HTTP请求,移除了HTTP/1.1中的串行请求。
- HTTP/2会压缩头,如果你同时发出多个请求,他们的头是一样的或是相似的,那么,协议会帮你消除重复的部分。这就是所谓的HPACK算法(参看RFC 7541 附录A)
- HTTP/2允许服务端在客户端放cache,又叫服务端push,也就是说,你没有请求的东西,我服务端可以先送给你放在你的本地缓存中。比如,你请求X,我服务端知道X依赖于Y,虽然你没有的请求Y,但我把把Y跟着X的请求一起返回客户端。
对于这些性能上的改善,在Medium上有篇文章你可看一下相关的细节说明和测试“HTTP/2: the difference between HTTP/1.1, benefits and how to use it”
当然,还需要注意到的是HTTP/2的协议复杂度比之前所有的HTTP协议的复杂度都上升了许多许多,其内部还有很多看不见的东西,比如其需要维护一个“优先级树”来用于来做一些资源和请求的调度和控制。如此复杂的协议,自然会产生一些不同的声音,或是降低协议的可维护和可扩展性。所以也有一些争议。尽管如此,HTTP/2还是很快地被世界所采用。
HTTP/2 是2015年推出的,其发布后,Google 宣布移除对SPDY的支持,拥抱标准的 HTTP/2。过了一年后,就有8.7%的网站开启了HTTP/2,根据 这份报告 ,截止至本文发布时(2019年10月1日 ), 在全世界范围内已经有41%的网站开启了HTTP/2。
HTTP/2的官方组织在 Github 上维护了一份各种语言对HTTP/2的实现列表,大家可以去看看。
我们可以看到,HTTP/2 在性能上对HTTP有质的提高,所以,HTTP/2 被采用的也很快,所以,如果你在你的公司内负责架构的话,HTTP/2是你一个非常重要的需要推动的一个事,除了因为性能上的问题,推动标准落地也是架构师的主要职责,因为,你企业内部的架构越标准,你可以使用到开源软件,或是开发方式就会越有效率,跟随着工业界的标准的发展,你的企业会非常自然的享受到标准所带来的红利。
1.4 HTTP/3
然而,这个世界没有完美的解决方案,HTTP/2也不例外,其主要的问题是:若干个HTTP的请求在复用一个TCP的连接,底层的TCP协议是不知道上层有多少个HTTP的请求的,所以,一旦发生丢包,造成的问题就是所有的HTTP请求都必需等待这个丢了的包被重传回来,哪怕丢的那个包不是我这个HTTP请求的。因为TCP底层是没有这个知识了。
这个问题又叫Head-of-Line Blocking问题,这也是一个比较经典的流量调度的问题。这个问题最早主要的发生的交换机上。下图来自Wikipedia。
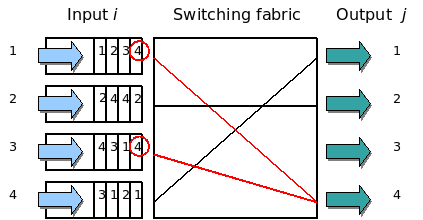
图中,左边的是输入队列,其中的1,2,3,4表示四个队列,四个队列中的1,2,3,4要去的右边的output的端口号。此时,第一个队列和第三个队列都要写右边的第四个端口,然后,一个时刻只能处理一个包,所以,一个队列只能在那等另一个队列写完后。然后,其此时的3号或1号端口是空闲的,而队列中的要去1和3号端号的数据,被第四号端口给block住了。这就是所谓的HOL blocking问题。
HTTP/1.1中的pipeline中如果有一个请求block了,那么队列后请求也统统被block住了;HTTP/2 多请求复用一个TCP连接,一旦发生丢包,就会block住所有的HTTP请求。这样的问题很讨厌。好像基本无解了。
是的TCP是无解了,但是UDP是有解的 !于是HTTP/3破天荒地把HTTP底层的TCP协议改成了UDP!
然后又是Google 家的协议进入了标准 – QUIC (Quick UDP Internet Connections)。接下来是QUIC协议的几个重要的特性,为了讲清楚这些特性,我需要带着问题来讲(注:下面的网络知识,如果你看不懂的话,你需要学习一下《TCP/IP详解》一书(在我写blog的这15年里,这本书推荐了无数次了),或是看一下本站的《TCP的那些事》。):
- 首先是上面的Head-of-Line blocking问题,在UDP的世界中,这个就没了。这个应该比较好理解,因为UDP不管顺序,不管丢包(当然,QUIC的一个任务是要像TCP的一个稳定,所以QUIC有自己的丢包重传的机制)
- TCP是一个无私的协议,也就是说,如果网络上出现拥塞,大家都会丢包,于是大家都会进入拥塞控制的算法中,这个算法会让所有人都“冷静”下来,然后进入一个“慢启动”的过程,包括在TCP连接建立时,这个慢启动也在,所以导致TCP性能迸发地比较慢。QUIC基于UDP,使用更为激进的方式。同时,QUIC有一套自己的丢包重传和拥塞控制的协,一开始QUIC是重新实现一TCP 的 CUBIC算法,但是随着BBR算法的成熟(BBR也在借鉴CUBIC算法的数学模型),QUIC也可以使用BBR算法。这里,多说几句,从模型来说,以前的TCP的拥塞控制算法玩的是数学模型,而新型的TCP拥塞控制算法是以BBR为代表的测量模型,理论上来说,后者会更好,但QUIC的团队在一开始觉得BBR不如CUBIC的算法好,所以没有用。现在的BBR 2.x借鉴了CUBIC数学模型让拥塞控制更公平。这里有文章大家可以一读“TCP BBR : Magic dust for network performance.”
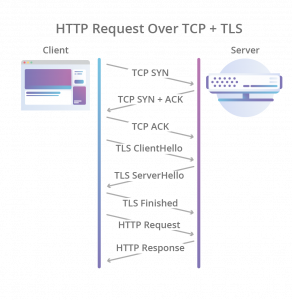
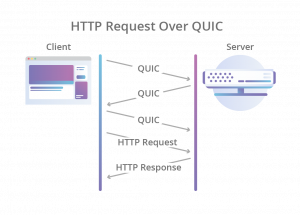
- 接下来,现在要建立一个HTTPS的连接,先是TCP的三次握手,然后是TLS的三次握手,要整出六次网络交互,一个链接才建好,虽说HTTP/1.1和HTTP/2的连接复用解决这个问题,但是基于UDP后,UDP也得要实现这个事。于是QUIC直接把TCP的和TLS的合并成了三次握手(对此,在HTTP/2的时候,是否默认开启TLS业内是有争议的,反对派说,TLS在一些情况下是不需要的,比如企业内网的时候,而支持派则说,TLS的那些开销,什么也不算了)。
 |
 |
|---|---|
所以,QUIC是一个在UDP之上的伪TCP +TLS +HTTP/2的多路复用的协议。
但是对于UDP还是有一些挑战的,这个挑战主要来自互联网上的各种网络设备,这些设备根本不知道是什么QUIC,他们看QUIC就只能看到的就是UDP,所以,在一些情况下,UDP就是有问题的,
-
比如在NAT的环境下,如果是TCP的话,NAT路由或是代理服务器,可以通过记录TCP的四元组(源地址、源端口,目标地址,目标端口)来做连接映射的,然而,在UDP的情况下不行了。于是,QUIC引入了个叫connection id的不透明的ID来标识一个链接,用这种业务ID很爽的一个事是,如果你从你的3G/4G的网络切到WiFi网络(或是反过来),你的链接不会断,因为我们用的是connection id,而不是四元组。
-
然而就算引用了connection id,也还是会有问题 ,比如一些不够“聪明”的等价路由交换机,这些交换机会通过四元组来做hash把你的请求的IP转到后端的实际的服务器上,然而,他们不懂connection id,只懂四元组,这么导致属于同一个connection id但是四元组不同的网络包就转到了不同的服务器上,这就是导致数据不能传到同一台服务器上,数据不完整,链接只能断了。所以,你需要更聪明的算法(可以参看 Facebook 的 Katran 开源项目 )
好了,就算搞定上面的东西,还有一些业务层的事没解,这个事就是 HTTP/2的头压缩算法 HPACK,HPACK需要维护一个动态的字典表来分析请求的头中哪些是重复的,HPACK的这个数据结构需要在encoder和decoder端同步这个东西。在TCP上,这种同步是透明的,然而在UDP上这个事不好干了。所以,这个事也必需要重新设计了,基于QUIC的QPACK就出来了,利用两个附加的QUIC steam,一个用来发送这个字典表的更新给对方,另一个用来ack对方发过来的update。
目前看下来,HTTP/3目前看上去没有太多的协议业务逻辑上的东西,更多是HTTP/2 + QUIC协议。但,HTTP/3 因为动到了底层协议,所以,在普及方面上可能会比 HTTP/2要慢的多的多。但是,可以看到QUIC协议的强大,细思及恐,QUIC这个协议真对TCP是个威胁,如果QUIC成熟了,TCP是不是会有可能成为历史呢?
未来十年,让我们看看UDP是否能够逆袭TCP……
2. http必备知识
2.1 http的诞生
最后我们来看应用层http(HyperText Transfer Protocol )。早在1989年,我们http就诞生了,CERN(欧洲核子研究组织 )设计了最初的理念:借助多文档之间相互关联形成的超文本 (HyperText),连成可相互参阅的 WWW(World Wide Web,万维 网)。 并且提出了3项www构建技术,把 SGML(Standard Generalized Markup Language,标准通用标记语言)作为页面的文本标 记语言的 HTML(HyperText Markup Language,超文本标记语言); 作为文档传递协议的 HTTP ;指定文档所在地址的 URL(Uniform Resource Locator,统一资源定位符)。
http协议主要由以下几个,可以参考https://coolshell.cn/articles/19840.html,很好的发展史。
概括下,http/0.9 1990问世,并不完善,然后出了http/1.0,添加了版本号,header,状态码,Content-Type等。但是缺点是网络性能,于是http/1.1修复了这个问题,还加入了新的功能。后面还有http/2,http/3。
2.2 编码
我们再来回顾一下:

在之前的报文拆解过程中,我们看到多了很多 %22,其实, 0x22是单引号 "的ascii值,
一方面,URL描述的资源为了能通过其他各种协议传送,但是有些协议在传输过程中会剥去一些特定的字符;另一方面,URL还是可读的,所以那些不可打印的字符就不能在URL中使用了,比如空格;最后,URL还得是完整的,它需要支持所有语言的字符。
总之,基于很多原因,URL设计者将US-ASCII码和其转义序列集成到URL中,通过转义序列,就可以用US-ASCII字符集的有限子集对任意字符或数据进行编码了。
转义的方法:百分号( %)后跟着两个表示ASCII码的十六进制数。比如:

2.3 URI和URL
我们需要在这里区分下URI和URL。
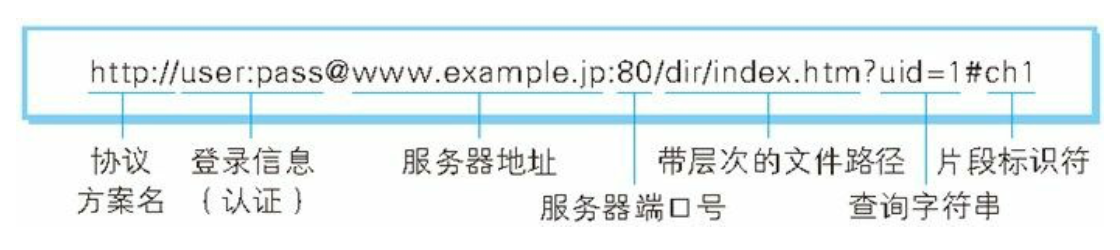
URI 是 Uniform Resource Identifier 的缩写,Request For Comments(RFC2396)进行了定义。URI的一个例子
ftp://ftp.is.co.za/rfc/rfc1808.txt
http://www.ietf.org/rfc/rfc2396.txt
ldap://[2001:db8::7]/c=GB?objectClass?one
mailto:John.Doe@example.com
news:comp.infosystems.www.servers.unix
tel:+1-816-555-1212
telnet://192.0.2.16:80/
urn:oasis:names:specification:docbook:dtd:xml:4.1.2
URI 用字符串标识某一互联网资源,而 URL 表示资源的地点(互联 网上所处的位置)。可见 URL 是 URI 的子集。
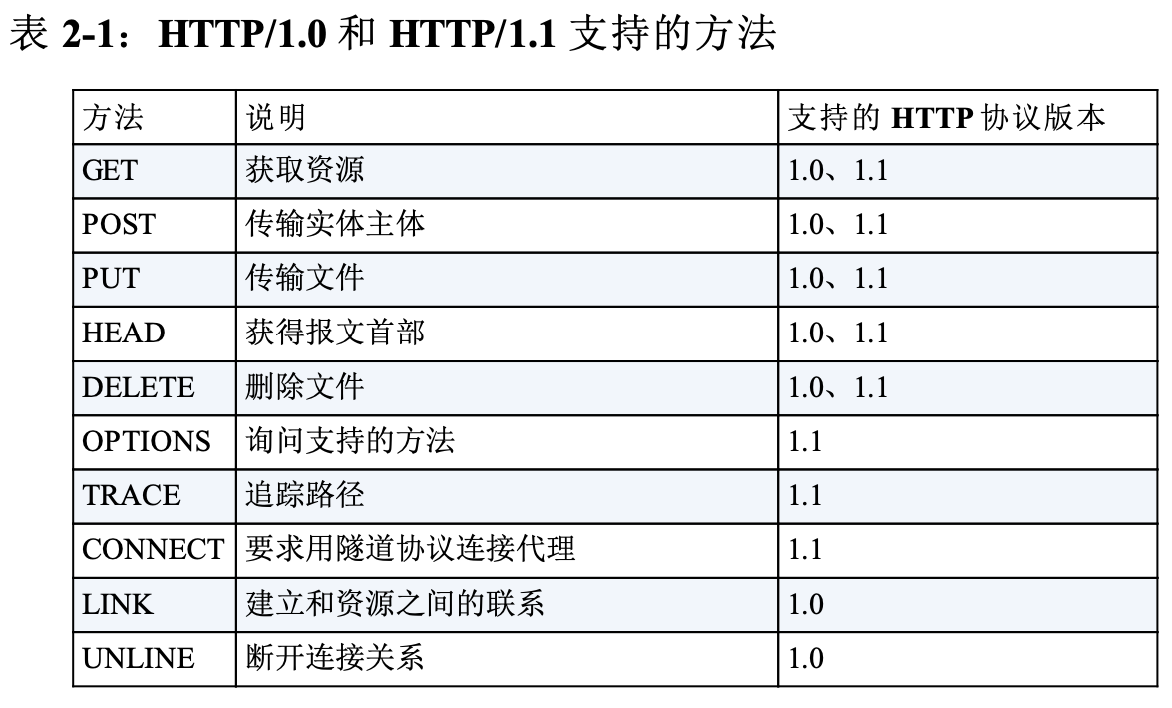
2.4 http方法
HTTP支持几种不同的请求方法,每种方法对服务器要求的动作不同,如下图是几种常见的方法:

HEAD方法只获取头部,不获取数据部分。通过头部可以获取比如资源的类型(Content-Type)、资源的长度(Content-Length)这些信息。这样,客户端可以获取即将请求资源的一些情况,可以做到心中有数。
POST用于向服务器发送数据,常见的是提交表单;PUT用于向服务器上的资源存储数据。
2.5 持久连接
我们知道http使用了TCP,每次建立连接需要经过三次握手,很少消耗资源,为了优化,引入了HTTP Persistent Connections,也称作HTTP keep-alive。持久连接的特点是,只要任意一端 没有明确提出断开连接,则保持 TCP 连接状态。
在 HTTP/1.1 中,所有的连接默认都是持久连接,但在 HTTP/1.0 内并 未标准化。
HTTP有keep-alive机制,目的是可以在一个TCP 连接上传输多个HTTP事务,以此提高通信效率。底层的TCP其实也有keep-alive机制,它是为了探测TCP连接的活跃性。TCP层的keepalive可以在任何一方设置,可以是一端设置、两端同时设置或者两端都没有设置。新建socket的时候需要设置,从而使得协议栈调用相关函数tcpsetkeepalive,来激活连接的keep-alive属性。
当网络两端建立了TCP连接之后,闲置(双方没有任何数据流发送往来)时间超过 tcp_keepalive_time后,服务器内核就会尝试向客户端发送侦测包,来判断TCP连接状况(有可能客户端崩溃、强制关闭了应用、主机不可达等等)。如果没有收到对方的回答(ack包),则会在 tcp_keepalive_intvl后再次尝试发送侦测包,直到收到对方的ack,如果一直没有收到对方的ack,一共会尝试 tcpkeepaliveprobes次,每次的间隔时间在这里分别是15s, 30s, 45s, 60s, 75s。如果尝试 tcp_keepalive_probes次后,依然没有收到对方的ack包,则会丢弃该TCP连接。TCP连接默认闲置时间是2小时,一般设置为30分钟足够了。
2.6 cookie
我们知道http是无状态的,请求和响应都没有序列化,所以我们引入了cookie技术。Cookie 技术通过在请求和响应报文中写入 Cookie 信 息来控制客户端的状态。
- Name:就是cookieName
- value:cookieName对应的值。
-
domain:域,表示当前cookie所属于哪个域或子域下面
- path:表示cookie的所属路径,一般设为“/”,表示同一个站点的所有页面都可以访问这个cookie。
- expiration:表示了cookie的有效期。
- secure:表示该cookie只能用https传输。
cookie是服务器“贴在”客户端身上的标签,由客户端维护的状态片段,并且只会回送给合适的站点。有两类cookie: 会话cookie、持久cookie. 会话cookie在退出浏览器后就被删除了;而持久cookie则保存在硬盘中,计算机重启后仍然存在。
2.7 http报文
下面我们看下http的报文:


2.8 压缩
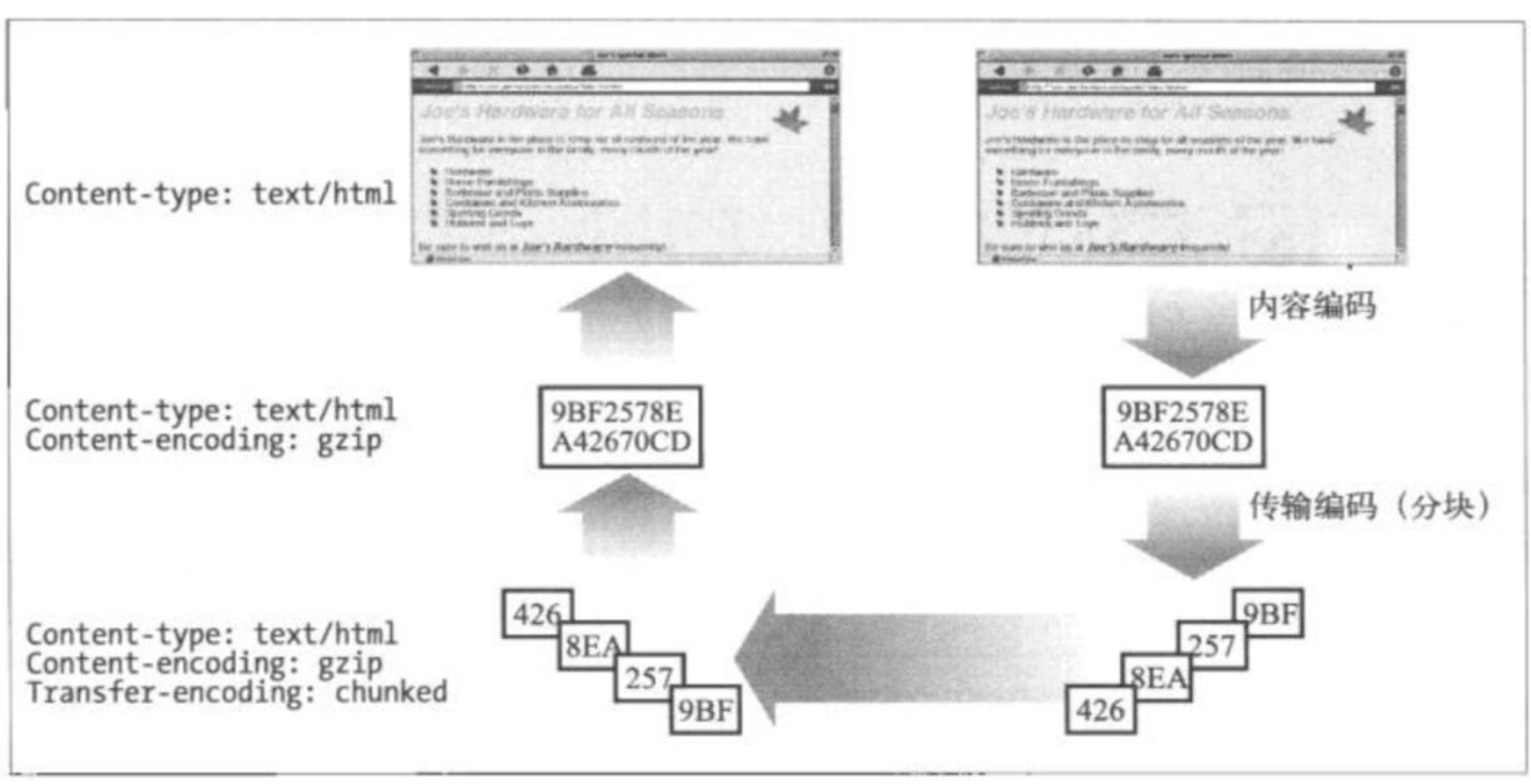
为了进行优化,我们可以进行压缩,常用的压缩有gzip,compress等。此外,在发送大文件的时候,我们可以把数据分块发送,分块传输编码(Chunked Transfer Coding) 。
主要有内容编码和传输编码。它与内容无关,它是为了改变报文数据在网络上传输的方式。传输编码是在HTTP 1.1中引入的一个新特性。通常,服务器需要先生成数据,再进行传输,这时,可以计算数据的长度,并将其编码到 Content-Length中。但是,有时,内容是动态生成的,服务器希望在数据生成之前就开始传输,这时,是没有办法知道数据大小的。这种情况下,就要用到 传输编码来标注数据的结束的。
HTTP协议中通过如下两个首部来描述和控制传输编码:

分块编码的报文形式是这样的:
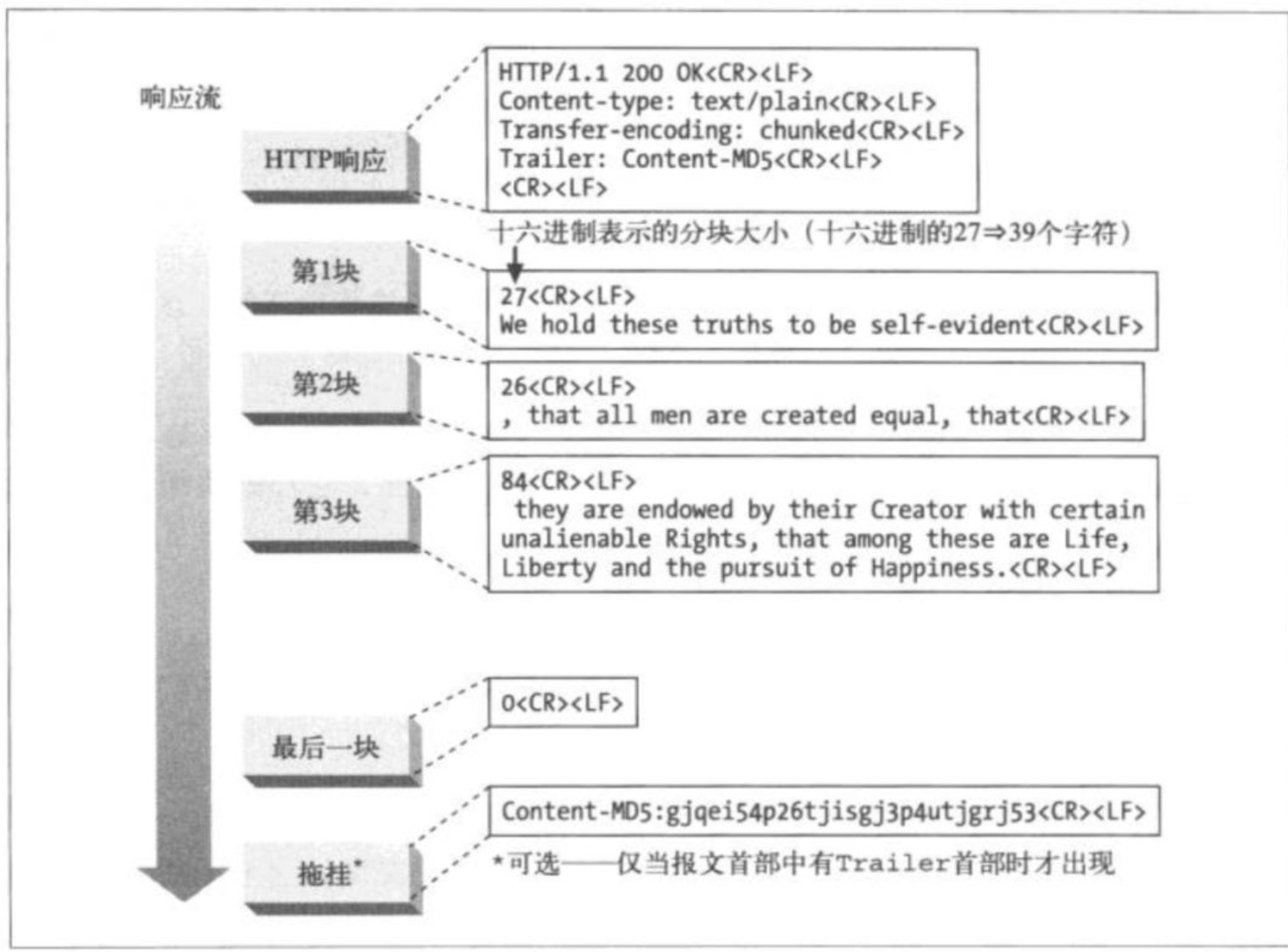
每个分块包含一个长度值(十六进制,字节数)和该分块的数据。 用于区隔长度值和数据。长度值不包含分块中的任何序列。最后一个分块,用长度值0来表示结束。注意报文首部包含一个 Trailer:Content-MD5, 所以在紧跟着最后一个报文结束之后,就是一个拖挂。其他如, Content-Length, Trailer, Transfer-Encoding也可以作为拖挂。
内容编码和传输编码是可以结合起来使用的。
2.9 MIME类型
随着网络的发展,我们可能需要发送越来越多类型的对象,图片,视频都是可能的,是因为引入了MIME(Multipurpose Internet Mail Extensions).
响应数据中,我们注意到有一个首部:
Content-Type: text/plain; charset=utf-8
互联网上有数千种不同的数据类型,HTTP给每种对象都打上了MIME(Multipurpose Internet Media Extension, 多用途因特网邮件扩展)标签,也就是响应数据中的 Content-Type. MIME本来是用在邮件协议中的,后来被移植到了HTTP中。浏览器从服务器上取回了一个对象时,会去查看MIME类型,从而得知如何处理这种对象,是该展示图片,还是调用声卡播放声音。MIME通过斜杠来标识对象的主类型和其中的特定的子类型,下表展示了一些常见的类型,其中的实体主体是指body部分:

2.10 状态码
此外,http的状态码也是十分重要的,先浏览下:
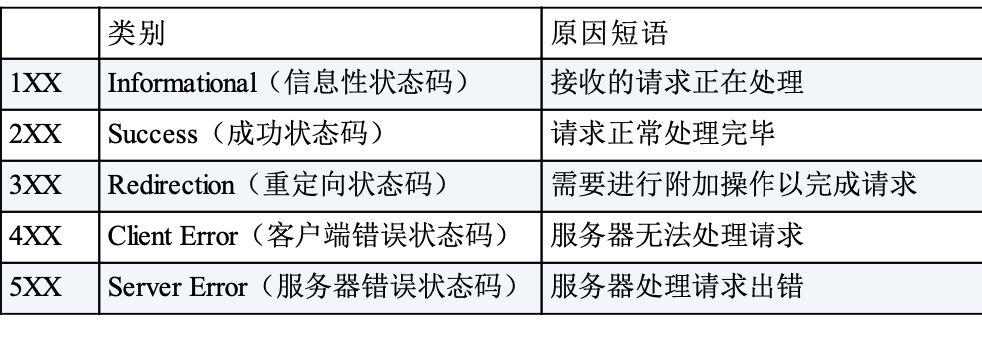
我们看几个常见的,先来看
- 2XX 的响应结果表明请求被正常处理了
- 200代表成功
- 204代表处理成功,但是没有可返回的资源
- 206 Partial Content 表示返回部分数据。
- 3重定向类的,表明浏览器需要执行某些特殊的处理以正确处理请求。
- 301 Moved Permanently,永久性重定向。
- 302临时性重定向,注意和301对比,
- 303See Other,注意区分,303 状态码和 302 Found 状态码有着相同的功能,但 303 状态码明确 表示客户端应当采用 GET 方法获取资源,
- 还有304 Not Modified ,和重定向没关系
- 307 Temporary Redirect。
- 4客户端错误的
- 400 Bad Request ,表示请求报文中存在语法错误 ;
- 401 Unauthorized ;
- 403 Forbidden ;
- 404 Not Found 。
- 5服务器错误。
- 500 Internal Server Error ;
- 503 Service Unavailable 。
其中,我们需要理解重定向技术,非常有用的技术,对理解OAuth, CAS(SSO)很有帮助。
2.11 一个机器部署多个域名
这个话题到此结束,我们来看下一个话题,想想这么一个场景,我们可能有一个需求,在一台服务器上部署多个应用,比如a.com,b.com。用户访问后,经过DNS解析后,请求到了同一台服务器,怎么区分呢?
这个时候是不能用端口来区分的,原因在于都是www服务,使用的是同一个端口,那么怎么办呢?答案是必须在 Host 首部内完整指定主机名或域名的 URI。
2.12 代理
HTTP的代理服务器既是Web服务器,又是Web客户端。
区分:正向代理/反向代理。
正向代理代理的是客户端,反向代理代理的是内部的服务器。
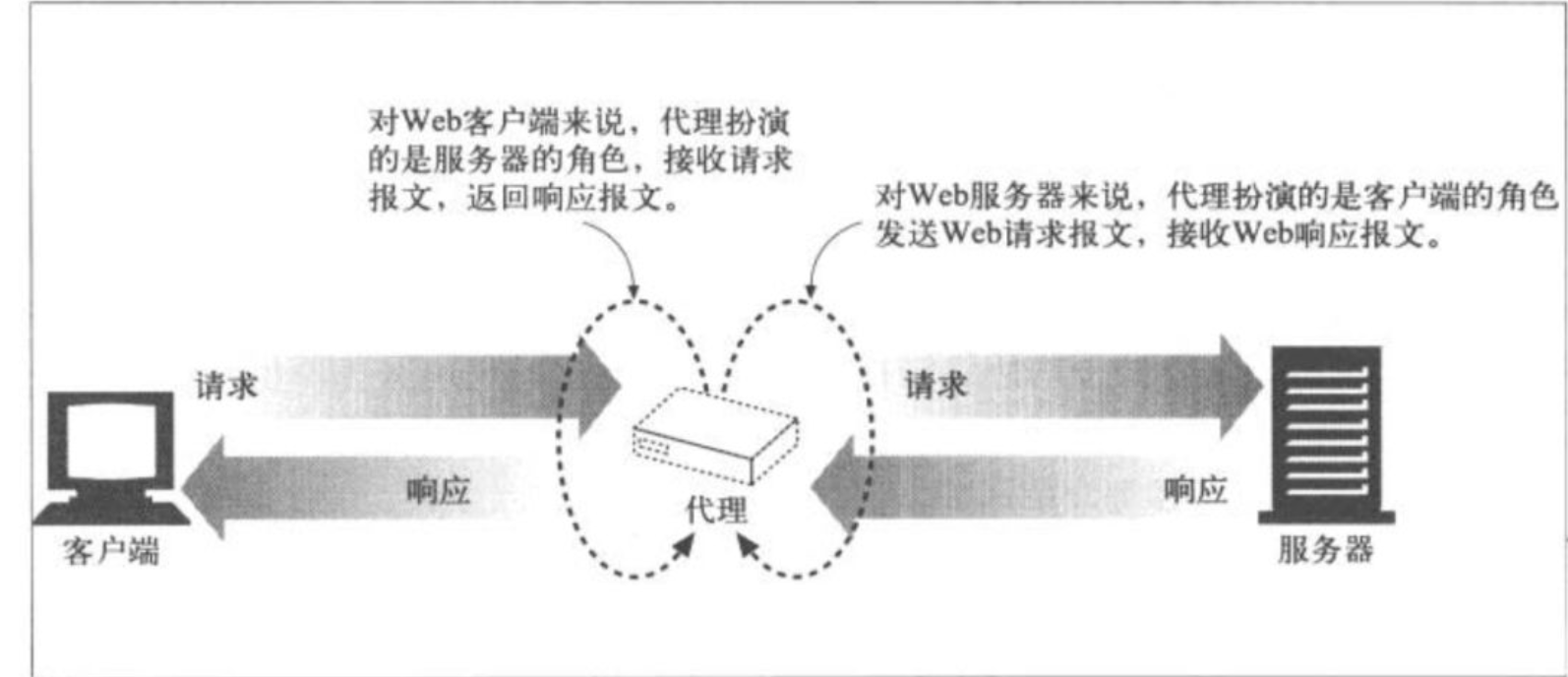
使用代理可以“接触”到所有流过的HTTP流量,代理可以对其进行监视和修改。常见的就是对儿童过滤一些“成人”内容;网络工程师会利用代理服务器来提高安全性,它可以限制哪些应用层的协议数据可以通过,过滤“病毒”等数据;代理可以存储缓存的文件,直接返回给访问者,无需请求原始的服务器资源;对于访问慢速网络上的公共内容时,可以假扮服务器提供服务,从而提高访问速度;这被称为 反向代理;可以作为内容路由器,如对付费用户,则将请求导到缓存服务器,提高访问速度;可以将页面的语言转换到与客户端相匹配,这称为 内容转码器; 匿名代理会主动从HTTP报文中删除身份相关的信息,如 User-Agent, Cookie等字段。
现实中,请求通过以下几种方式打到代理服务器上去:

报文每经过一个中间点(代理或网关),都需要在首部via字段的末尾插入一个可以代表本节点的独特的字符串,包含实现的协议版本和主机地址。注意图中的via字段。

请求和响应的报文传输路径通常都是一致的,只不过方向是相反的。因此,响应报文上的via字段表示的中间节点的顺序是刚好相反的。
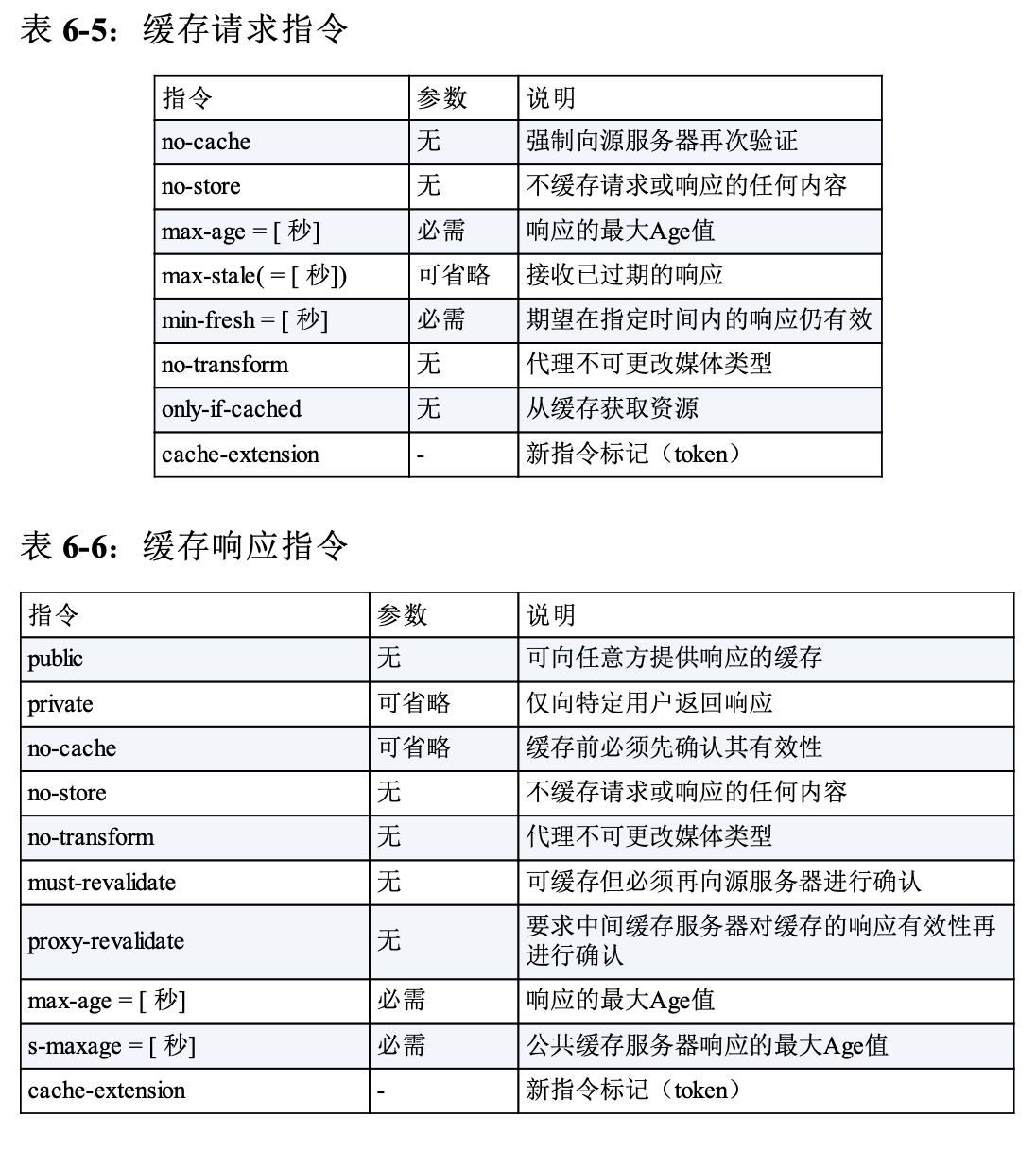
2.13 缓存
当有很多请求访问同一个页面时,服务器会多次传输同一份数据,这些数据重复地在网络中传输着,消耗着大量带宽。如果将这些数据缓存下来,就可以提高响应速度,节省网络带宽了。
大部分缓存只有在客户端发起请求,并且副本已经比较旧的情况下才会对副本的新鲜度进行检测。最常用的请求首部是 If-Modified-Since, 如果在xx时间(此时间即为If-Modified-Since的值)之后内容没有变化,服务器会回应一个 304NotModified. 否则,服务器会正常响应,并返回原始的文件数据,而这个过程中被称为 再验证命中。
再验证可能出现命中或未命中的情况。未命中时,服务器回复 200OK,并且返回完整的数据;命中时,服务器回复 304NotModified; 还有一种情况,缓存被删除了,那么根据响应状态码,缓存服务器也会删除自己缓存的副本。
顺带提一句,若要在项目中使用缓存,就一定要关注缓存命中比例。若命中比例不高,就要重新考虑设置缓存的必要性了。
缓存服务器返回响应的时候,是基于已缓存的服务器响应的首部,再对一些首部字段做一些微调。比如向其中插入新鲜度信息(如 Age, Expires首部等),而且通常会包含一个 via首部来说明缓存是由一个缓存代理提供的。注意,这时不要修改 Date字段,它表示原始服务器最初构建这条响应的日期。
HTTP通过 文档过期机制和 服务器再验证机制保持已缓存数据和服务器间的数据充分一致。
文档过期通过如下首部字段来表示缓存的有效期:

当上面两个字段暗示的过期时间已到,需要向服务器再次验证文档的新鲜度。如果这时缓存仍和服务器上的原始文档一致,缓存只需要更新头部的相关字段。如上表中提到的 Expires字段等。
为了更好的节省网络流量,缓存服务器可以通过相关首部向原始服务器发送一个 条件GET请求, 这样只有在缓存真正过期的情况下,才会返回原始的文档,否则只会返回相关的首部。 条件GET请求会用到如下的字段:

其中,Last-Modified和ETag是很重要的。
如果在 If-Modified-Since 字段指定的日期时间后,资源发生了 更新,服务器会接受请求。首部字段 If-Modified-Since,属附带条件之一,它会告知服务器若 If- Modified-Since 字段值早于资源的更新时间,则希望能处理该请求。 而在指定 If-Modified-Since 字段值的日期时间之后,如果请求的资源 都没有过更新,则返回状态码 304 Not Modified 的响应。If-Modified-Since 用于确认代理或客户端拥有的本地资源的有效性。 获取资源的更新日期时间,可通过确认首部字段 Last-Modified 来确定。
只有在 If-None-Match 的字段值与 ETag 值不一致时,可处理 该请求。与 If-Match 首部字段的作用相反。首部字段 If-None-Match 属于附带条件之一。它和首部字段 If-Match 作用相反。用于指定 If-None-Match 字段值的实体标记(ETag)值与 请求资源的 ETag 不一致时,它就告知服务器处理该请求。
2.14 重定向
重定向分为http重定向和DNS重定向。
http重定向:服务器收到客户端请求后,向客户端返回一条带有状态码 302重定向的报文,告诉他们应该去其他的地方试试。
DNS重定向:DNS将几个IP地址关联到一个域上,采用算法决定返回的IP地址。可以是简单的 轮转;也可以是更高级的算法,如返回负载最轻的服务器的IP地址,称为 负载均衡算法;如果考虑地理位置,返回给客户端最近位置的地址,称为 邻接路由算法;还有一种是绕过出现故障的地址,称为 故障屏蔽算法。
2.15 http首部
http的报文首部是十分重要的,我们来看下:

详细的看下面:


具体来看,几个比较重要的,Cache-Control ,Cache-Control: private, max-age=0, no-cache
Connection也是比较重要的,主要有两个作用,控制不再转发给代理的首部字段 ,管理持久连接。
Date是时间。
ransfer-Encoding 指定了编码格式。
Accept 指定接收文件的格式;
Referer 告知服务器请求的原始资源的 URI。
User-Agent 用于传达浏览器的种类。
还有很多的,需要不断的学习。
2.16 https
HTTP+ 加密 + 认证 + 完整性保护 =HTTPS
tls是加密+认证。
2.17 认证方式
- BASIC 认证(基本认证):Base64(用户名:密码),缺点是未加密
- DIGEST 认证(摘要认证):可以防止密码窃听,无法防止用户伪装
- SSL 客户端认证:需要收费
- FormBase 认证(基于表单认证)
- 用cookie来管理Session
我们知道,HTTP是无状态的,所以,当我们需要获得用户是否在登录的状态时,我们需要检查用户的登录状态,一般来说,用户的登录成功后,服务器会发一个登录凭证(又被叫作Token),就像你去访问某个公司,在前台被认证过合法后,这个公司的前台会给你的一个访客卡一样,之后,你在这个公司内去到哪都用这个访客卡来开门,而不再校验你是哪一个人。在计算机的世界里,这个登录凭证的相关数据会放在两种地方,一个地方在用户端,以Cookie的方式(一般不会放在浏览器的Local Storage,因为这很容易出现登录凭证被XSS攻击),另一个地方是放在服务器端,又叫Session的方式(SessonID存于Cookie)。
但是,这个世界还是比较复杂的,除了用户访问,还有用户委托的第三方的应用,还有企业和企业间的调用,这里,我想把业内常用的一些 API认证技术相对系统地总结归纳一下,这样可以让大家更为全面的了解这些技术。注意,这是一篇长文!
2.17.1 HTTP Basic
HTTP Basic 是一个非常传统的API认证技术,也是一个比较简单的技术。这个技术也就是使用 username和 password 来进行登录。整个过程被定义在了 RFC 2617 中,也被描述在了 Wikipedia: Basic Access Authentication 词条中,同时也可以参看 MDN HTTP Authentication
其技术原理如下:
- 把
username和password做成username:password的样子(用冒号分隔) - 进行Base64编码。
Base64("username:password")得到一个字符串(如:把haoel:coolshell进行base64 后可以得到aGFvZW86Y29vbHNoZWxsCg) - 把
aGFvZW86Y29vbHNoZWxsCg放到HTTP头中Authorization字段中,形成Authorization: Basic aGFvZW86Y29vbHNoZWxsCg,然后发送到服务端。 - 服务端如果没有在头里看到认证字段,则返回401错,以及一个个
WWW-Authenticate: Basic Realm='HelloWorld'之类的头要求客户端进行认证。之后如果没有认证通过,则返回一个401错。如果服务端认证通过,那么会返回200。
我们可以看到,使用Base64的目的无非就是为了把一些特殊的字符给搞掉,这样就可以放在HTTP协议里传输了。而这种方式的问题最大的问题就是把用户名和口令放在网络上传,所以,一般要配合TLS/SSL的安全加密方式来使用。我们可以看到 JIRA Cloud 的API认证支持HTTP Basic 这样的方式。
但我们还是要知道,这种把用户名和密码同时放在公网上传输的方式有点不太好,因为Base64不是加密协议,而是编码协议,所以就算是有HTTPS作为安全保护,给人的感觉还是不放心。
2.17.2 Digest Access
中文称“HTTP 摘要认证”,最初被定义在了 RFC 2069 文档中(后来被 RFC 2617 引入了一系列安全增强的选项;“保护质量”(qop)、随机数计数器由客户端增加、以及客户生成的随机数)。
其基本思路是,请求方把用户名口令和域做一个MD5 – MD5(username:realm:password) 然后传给服务器,这样就不会在网上传用户名和口令了,但是,因为用户名和口令基本不会变,所以,这个MD5的字符串也是比较固定的,因此,这个认证过程在其中加入了两个事,一个是 nonce 另一个是 qop
-
首先,调用方发起一个普通的HTTP请求。比如:
GET /coolshell/admin/ HTTP/1.1 -
服务端自然不能认证能过,服务端返回401错误,并且在HTTP头里的
WWW-Authenticate包含如下信息:WWW-Authenticate: Digest realm="testrealm@host.com", qop="auth,auth-int", nonce="dcd98b7102dd2f0e8b11d0f600bfb0c093", opaque="5ccc069c403ebaf9f0171e9517f40e41" - 其中的
nonce为服务器端生成的随机数,然后,客户端做HASH1=MD5(MD5(username:realm:password):nonce:cnonce),其中的cnonce为客户端生成的随机数,这样就可以使得整个MD5的结果是不一样的。 - 如果
qop中包含了auth,那么还得做HASH2=MD5(method:digestURI)其中的method就是HTTP的请求方法(GET/POST…),digestURI是请求的URL。 - 如果
qop中包含了auth-init,那么,得做HASH2=MD5(method:digestURI:MD5(entityBody))其中的entityBody就是HTTP请求的整个数据体。 - 然后,得到
response = MD5(HASH1:nonce:nonceCount:cnonce:qop:HASH2)如果没有qop则response = MD5(HA1:nonce:HA2) - 最后,我们的客户端对服务端发起如下请求—— 注意HTTP头的
Authorization: Digest ...
GET /dir/index.html HTTP/1.0
Host: localhost
Authorization: Digest username="Mufasa",
realm="testrealm@host.com",
nonce="dcd98b7102dd2f0e8b11d0f600bfb0c093",
uri="%2Fcoolshell%2Fadmin",
qop=auth,
nc=00000001,
cnonce="0a4f113b",
response="6629fae49393a05397450978507c4ef1",
opaque="5ccc069c403ebaf9f0171e9517f40e41"
维基百科上的 Wikipedia: Digest access authentication 词条非常详细地描述了这个细节。
摘要认证这个方式会比之前的方式要好一些,因为没有在网上传递用户的密码,而只是把密码的MD5传送过去,相对会比较安全,而且,其并不需要是否TLS/SSL的安全链接。但是,别看这个算法这么复杂,最后你可以发现,整个过程其实关键是用户的password,这个password如果不够得杂,其实是可以被暴力破解的,而且,整个过程是非常容易受到中间人攻击——比如一个中间人告诉客户端需要的 Basic 的认证方式 或是 老旧签名认证方式(RFC2069)。
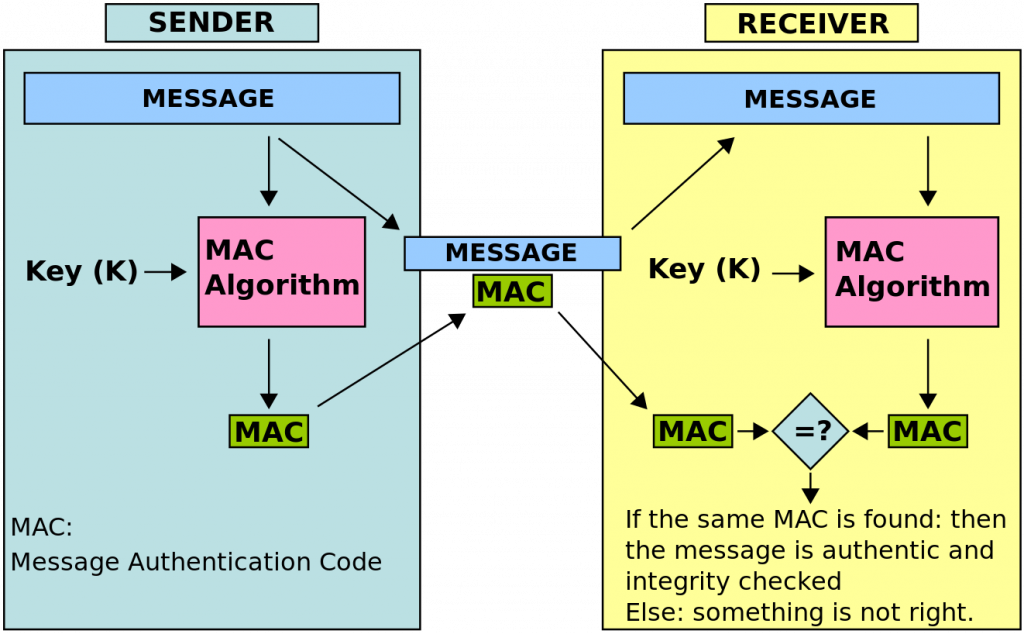
2.17.3 App Secret Key + HMAC
先说HMAC技术,这个东西来自于MAC – Message Authentication Code,是一种用于给消息签名的技术,也就是说,我们怕消息在传递的过程中被人修改,所以,我们需要用对消息进行一个MAC算法,得到一个摘要字串,然后,接收方得到消息后,进行同样的计算,然后比较这个MAC字符串,如果一致,则表明没有被修改过(整个过程参看下图)。而HMAC – Hash-based Authenticsation Code,指的是利用Hash技术完成这一工作,比如:SHA-256算法。
我们再来说App ID,这个东西跟验证没有关系,只是用来区分,是谁来调用API的,就像我们每个人的身份证一样,只是用来标注不同的人,不是用来做身份认证的。与前面的不同之处是,这里,我们需要用App ID 来映射一个用于加密的密钥,这样一来,我们就可以在服务器端进行相关的管理,我们可以生成若干个密钥对(AppID, AppSecret),并可以有更细粒度的操作权限管理。
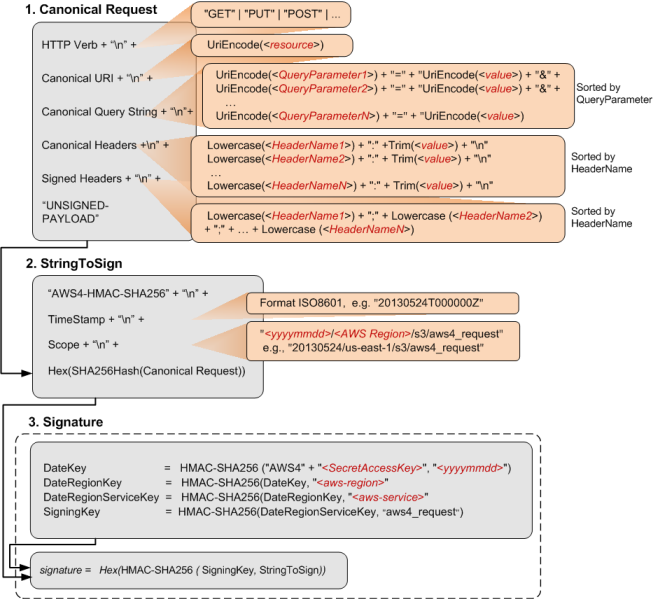
把AppID和HMAC用于API认证,目前来说,玩得最好最专业的应该是AWS了,我们可以通过S3的API请求签名文档看到AWS是怎么玩的。整个过程还是非常复杂的,可以通过下面的图片流程看个大概。基本上来说,分成如下几个步骤:
- 把HTTP的请求(方法、URI、查询字串、头、签名头,body)打个包叫
CanonicalRequest,作个SHA-256的签名,然后再做一个base16的编码 - 把上面的这个签名和签名算法
AWS4-HMAC-SHA256、时间戳、Scop,再打一个包,叫StringToSign。 - 准备签名,用
AWSSecretAccessKey来对日期签一个DataKey,再用DataKey对要操作的Region签一个DataRegionKey,再对相关的服务签一个DataRegionServiceKey,最后得到SigningKey. - 用第三步的
SigningKey来对第二步的StringToSign签名。
最后,发出HTTP Request时,在HTTP头的 Authorization字段中放入如下的信息:
Authorization: AWS4-HMAC-SHA256
Credential=AKIDEXAMPLE/20150830/us-east-1/iam/aws4_request,
SignedHeaders=content-type;host;x-amz-date,
Signature=5d672d79c15b13162d9279b0855cfba6789a8edb4c82c400e06b5924a6f2b5d7
其中的 AKIDEXAMPLE 是 AWS Access Key ID, 也就是所谓的 AppID,服务器端会根据这个AppID来查相关的 Secret Access Key,然后再验证签名。如果,你对这个过程有点没看懂的话,你可以读一读这篇文章——《Amazon S3 Rest API with curl》这篇文章里有好些代码,代码应该是最有细节也是最准确的了。
这种认证的方式好处在于,AppID和AppSecretKey,是由服务器的系统开出的,所以,是可以被管理的,AWS的IAM就是相关的管理,其管理了用户、权限和其对应的AppID和AppSecretKey。但是不好的地方在于,这个东西没有标准 ,所以,各家的实现很不一致。比如: Acquia 的 HMAC,微信的签名算法 (这里,我们需要说明一下,微信的API没有遵循HTTP协议的标准,把认证信息放在HTTP 头的 Authorization 里,而是放在body里)
2.17.4 JWT – JSON Web Tokens
JWT是一个比较标准的认证解决方案,这个技术在Java圈里应该用的是非常普遍的。JWT签名也是一种MAC(Message Authentication Code)的方法。JWT的签名流程一般是下面这个样子:
- 用户使用用户名和口令到认证服务器上请求认证。
- 认证服务器验证用户名和口令后,以服务器端生成JWT Token,这个token的生成过程如下:
- 认证服务器还会生成一个 Secret Key(密钥)
- 对JWT Header和 JWT Payload分别求Base64。在Payload可能包括了用户的抽象ID和的过期时间。
- 用密钥对JWT签名
HMAC-SHA256(SecertKey, Base64UrlEncode(JWT-Header)+'.'+Base64UrlEncode(JWT-Payload));
- 然后把
base64(header).base64(payload).signature作为 JWT token返回客户端。 - 客户端使用JWT Token向应用服务器发送相关的请求。这个JWT Token就像一个临时用户权证一样。
当应用服务器收到请求后:
- 应用服务会检查 JWT Token,确认签名是正确的。
- 然而,因为只有认证服务器有这个用户的Secret Key(密钥),所以,应用服务器得把JWT Token传给认证服务器。
- 认证服务器通过JWT Payload 解出用户的抽象ID,然后通过抽象ID查到登录时生成的Secret Key,然后再来检查一下签名。
- 认证服务器检查通过后,应用服务就可以认为这是合法请求了。
我们可以看以,上面的这个过程,是在认证服务器上为用户动态生成 Secret Key的,应用服务在验签的时候,需要到认证服务器上去签,这个过程增加了一些网络调用,所以,JWT除了支持HMAC-SHA256的算法外,还支持RSA的非对称加密的算法。
使用RSA非对称算法,在认证服务器这边放一个私钥,在应用服务器那边放一个公钥,认证服务器使用私钥加密,应用服务器使用公钥解密,这样一来,就不需要应用服务器向认证服务器请求了,但是,RSA是一个很慢的算法,所以,虽然你省了网络调用,但是却费了CPU,尤其是Header和Payload比较长的时候。所以,一种比较好的玩法是,如果我们把header 和 payload简单地做SHA256,这会很快,然后,我们用RSA加密这个SHA256出来的字符串,这样一来,RSA算法就比较快了,而我们也做到了使用RSA签名的目的。
最后,我们只需要使用一个机制在认证服务器和应用服务器之间定期地换一下公钥私钥对就好了。
这里强烈建议全文阅读 Anglar 大学的 《JSW:The Complete Guide to JSON Web Tokens》
2.17.5 OAuth 1.0
OAuth也是一个API认证的协议,这个协议最初在2006年由Twitter的工程师在开发OpenID实现的时候和社交书签网站Ma.gnolia时发现,没有一种好的委托授权协议,后来在2007年成立了一个OAuth小组,知道这个消息后,Google员工也加入进来,并完善有善了这个协议,在2007年底发布草案,过一年后,在2008年将OAuth放进了IETF作进一步的标准化工作,最后在2010年4月,正式发布OAuth 1.0,即:RFC 5849 (这个RFC比起TCP的那些来说读起来还是很轻松的),不过,如果你想了解其前身的草案,可以读一下 OAuth Core 1.0 Revision A ,我在下面做个大概的描述。
根据RFC 5849,可以看到 OAuth 的出现,目的是为了,用户为了想使用一个第三方的网络打印服务来打印他在某网站上的照片,但是,用户不想把自己的用户名和口令交给那个第三方的网络打印服务,但又想让那个第三方的网络打印服务来访问自己的照片,为了解决这个授权的问题,OAuth这个协议就出来了。
- 这个协议有三个角色:
- User(照片所有者-用户)
- Consumer(第三方照片打印服务)
- Service Provider(照片存储服务)
- 这个协义有三个阶段:
- Consumer获取Request Token
- Service Provider 认证用户并授权Consumer
- Consumer获取Access Token调用API访问用户的照片
整个授权过程是这样的:
- Consumer(第三方照片打印服务)需要先上Service Provider获得开发的 Consumer Key 和 Consumer Secret
- 当 User 访问 Consumer 时,Consumer 向 Service Provide 发起请求请求Request Token (需要对HTTP请求签名)
- Service Provide 验明 Consumer 是注册过的第三方服务商后,返回 Request Token(
oauth_token)和 Request Token Secret (oauth_token_secret) - Consumer 收到 Request Token 后,使用HTTP GET 请求把 User 切到 Service Provide 的认证页上(其中带上Request Token),让用户输入他的用户和口令。
- Service Provider 认证 User 成功后,跳回 Consumer,并返回 Request Token (
oauth_token)和 Verification Code(oauth_verifier) - 接下来就是签名请求,用Request Token 和 Verification Code 换取 Access Token (
oauth_token)和 Access Token Secret (oauth_token_secret) - 最后使用Access Token 访问用户授权访问的资源。
下图附上一个Yahoo!的流程图可以看到整个过程的相关细节。
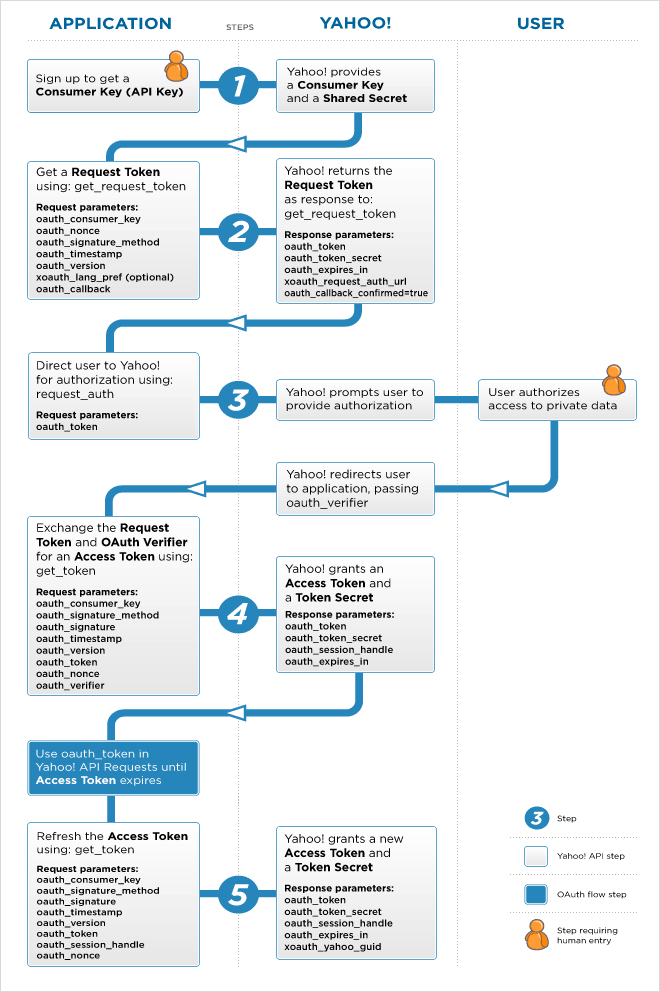
因为上面这个流程有三方:User,Consumer 和 Service Provide,所以,又叫 3-legged flow,三脚流程。OAuth 1.0 也有不需要用户参与的,只有Consumer 和 Service Provider 的, 也就是 2-legged flow 两脚流程,其中省掉了用户认证的事。整个过程如下所示:
- Consumer(第三方照片打印服务)需要先上Service Provider获得开发的 Consumer Key 和 Consumer Secret
- Consumer 向 Service Provide 发起请求请求Request Token (需要对HTTP请求签名)
- Service Provide 验明 Consumer 是注册过的第三方服务商后,返回 Request Token(
oauth_token)和 Request Token Secret (oauth_token_secret) - Consumer 收到 Request Token 后,直接换取 Access Token (
oauth_token)和 Access Token Secret (oauth_token_secret) - 最后使用Access Token 访问用户授权访问的资源。
最后,再来说一说OAuth中的签名。
- 我们可以看到,有两个密钥,一个是Consumer注册Service Provider时由Provider颁发的 Consumer Secret,另一个是 Token Secret。
- 签名密钥就是由这两具密钥拼接而成的,其中用
&作连接符。假设 Consumer Secret 为j49sk3j29djd而 Token Secret 为dh893hdasih9那个,签名密钥为:j49sk3j29djd&dh893hdasih9 - 在请求Request/Access Token的时候需要对整个HTTP请求进行签名(使用HMAC-SHA1和HMAC-RSA1签名算法),请求头中需要包括一些OAuth需要的字段,如:
- Consumer Key : 也就是所谓的AppID
- Token: Request Token 或 Access Token
- Signature Method :签名算法比如:HMAC-SHA1
- Timestamp:过期时间
- Nonce:随机字符串
- Call Back:回调URL
下图是整个签名的示意图:
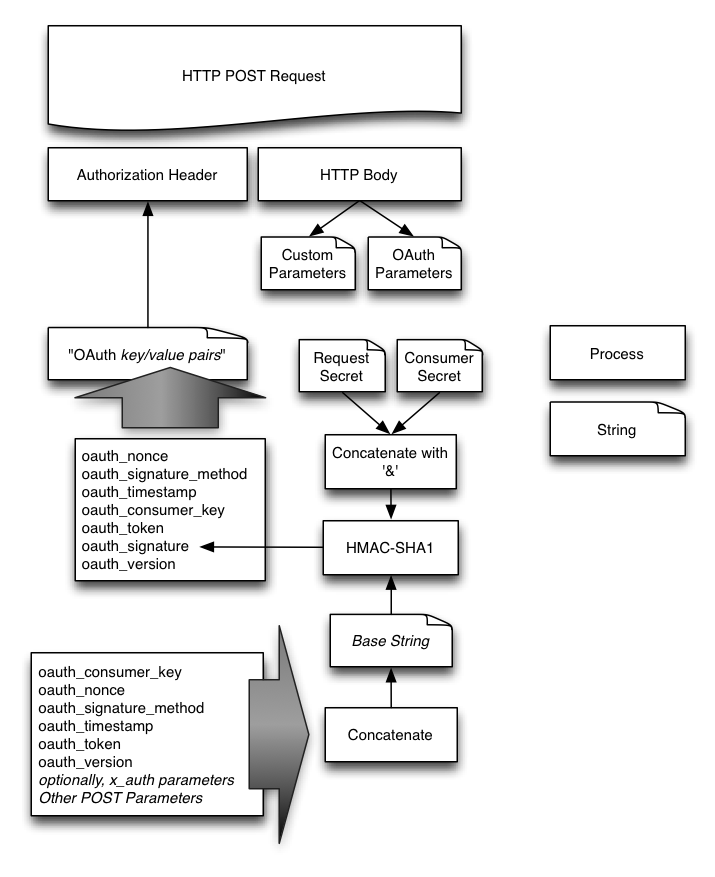
图片还是比较直观的,我就不多解释了。
2.17.6 OAuth 2.0
在前面,我们可以看到,从Digest Access, 到AppID+HMAC,再到JWT,再到OAuth 1.0,这些个API认证都是要向Client发一个密钥(或是用密码)然后用HASH或是RSA来签HTTP的请求,这其中有个主要的原因是,以前的HTTP是明文传输,所以,在传输过程中很容易被篡改,于是才搞出来一套的安全签名机制,所以,这些个认证的玩法是可以在HTTP明文协议下玩的。
这种使用签名方式大家可以看到是比较复杂的,所以,对于开发者来说,也是很不友好的,在组织签名的那些HTTP报文的时候,各种,URLEncode和Base64,还要对Query的参数进行排序,然后有的方法还要层层签名,非常容易出错,另外,这种认证的安全粒度比较粗,授权也比较单一,对于有终端用户参与的移动端来说也有点不够。所以,在2012年的时候,OAuth 2.0 的 RFC 6749 正式放出。
OAuth 2.0依赖于TLS/SSL的链路加密技术(HTTPS),完全放弃了签名的方式,认证服务器再也不返回什么 token secret 的密钥了,所以,OAuth 2.0是完全不同于1.0 的,也是不兼容的。目前,Facebook 的 Graph API 只支持OAuth 2.0协议,Google 和 Microsoft Azure 也支持Auth 2.0,国内的微信和支付宝也支持使用OAuth 2.0。
下面,我们来重点看一下OAuth 2.0的两个主要的Flow:
- 一个是Authorization Code Flow, 这个是 3 legged 的
- 一个是Client Credential Flow,这个是 2 legged 的。
2.17.6.1 Authorization Code Flow
Authorization Code 是最常使用的OAuth 2.0的授权许可类型,它适用于用户给第三方应用授权访问自己信息的场景。这个Flow也是OAuth 2.0四个Flow中我个人觉得最完整的一个Flow,其流程图如下所示。
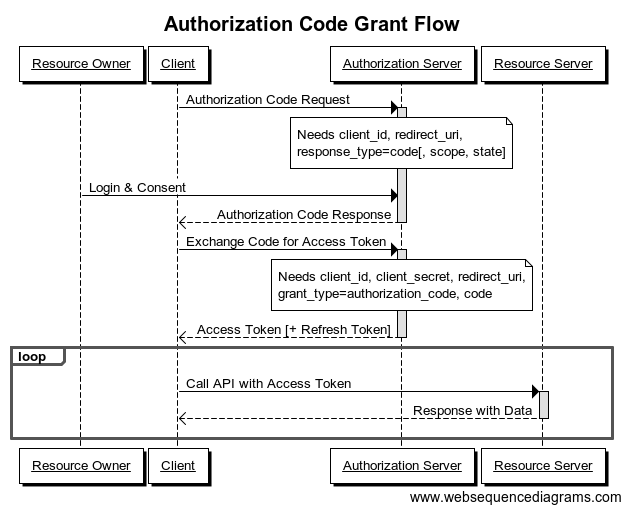
下面是对这个流程的一个细节上的解释:
1)当用户(Resource Owner)访问第三方应用(Client)的时候,第三方应用会把用户带到认证服务器(Authorization Server)上去,主要请求的是 /authorize API,其中的请求方式如下所示。
https://login.authorization-server.com/authorize?
client_id=6731de76-14a6-49ae-97bc-6eba6914391e
&response_type=code
&redirect_uri=http%3A%2F%2Fexample-client.com%2Fcallback%2F
&scope=read
&state=xcoiv98CoolShell3kch
其中:
-
client_id为第三方应用的App IDresponse_type=code为告诉认证服务器,我要走Authorization Code Flow。redirect_uri意思是我跳转回第三方应用的URLscope意是相关的权限state是一个随机的字符串,主要用于防CSRF攻击。
2)当Authorization Server收到这个URL请求后,其会通过 client_id来检查 redirect_uri和 scope是否合法,如果合法,则弹出一个页面,让用户授权(如果用户没有登录,则先让用户登录,登录完成后,出现授权访问页面)。
3)当用户授权同意访问以后,Authorization Server 会跳转回 Client ,并以其中加入一个 Authorization Code。 如下所示:
https://example-client.com/callback?
code=Yzk5ZDczMzRlNDEwYlrEqdFSBzjqfTG
&state=xcoiv98CoolShell3kch
我们可以看到,
-
- 请流动的链接是第 1)步中的
redirect_uri - 其中的
state的值也和第 1)步的state一样。
- 请流动的链接是第 1)步中的
4)接下来,Client 就可以使用 Authorization Code 获得 Access Token。其需要向 Authorization Server 发出如下请求。
POST /oauth/token HTTP/1.1
Host: authorization-server.com
code=Yzk5ZDczMzRlNDEwYlrEqdFSBzjqfTG
&grant_type=code
&redirect_uri=https%3A%2F%2Fexample-client.com%2Fcallback%2F
&client_id=6731de76-14a6-49ae-97bc-6eba6914391e
&client_secret=JqQX2PNo9bpM0uEihUPzyrh
5)如果没什么问题,Authorization 会返回如下信息。
{
"access_token": "iJKV1QiLCJhbGciOiJSUzI1NiI",
"refresh_token": "1KaPlrEqdFSBzjqfTGAMxZGU",
"token_type": "bearer",
"expires": 3600,
"id_token": "eyJ0eXAiOiJKV1QiLCJhbGciO.eyJhdWQiOiIyZDRkM..."
}
其中,
-
access_token就是访问请求令牌了refresh_token用于刷新access_tokenid_token是JWT的token,其中一般会包含用户的OpenID
6)接下来就是用 Access Token 请求用户的资源了。
GET /v1/user/pictures
Host: https://example.resource.com
Authorization: Bearer iJKV1QiLCJhbGciOiJSUzI1NiI
2.17.6.2 Client Credential Flow
Client Credential 是一个简化版的API认证,主要是用于认证服务器到服务器的调用,也就是没有用户参与的的认证流程。下面是相关的流程图。
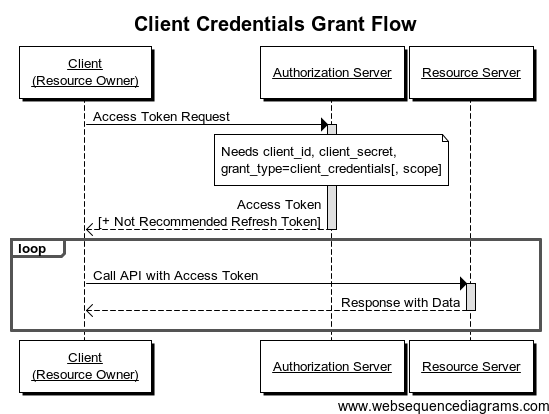
这个过程非常简单,本质上就是Client用自己的 client_id和 client_secret向Authorization Server 要一个 Access Token,然后使用Access Token访问相关的资源。
请求示例
POST /token HTTP/1.1
Host: server.example.com
Content-Type: application/x-www-form-urlencoded
grant_type=client_credentials
&client_id=czZCaGRSa3F0Mzpn
&client_secret=7Fjfp0ZBr1KtDRbnfVdmIw
返回示例
{
"access_token":"MTQ0NjJkZmQ5OTM2NDE1ZTZjNGZmZjI3",
"token_type":"bearer",
"expires_in":3600,
"refresh_token":"IwOGYzYTlmM2YxOTQ5MGE3YmNmMDFkNTVk",
"scope":"create"
}
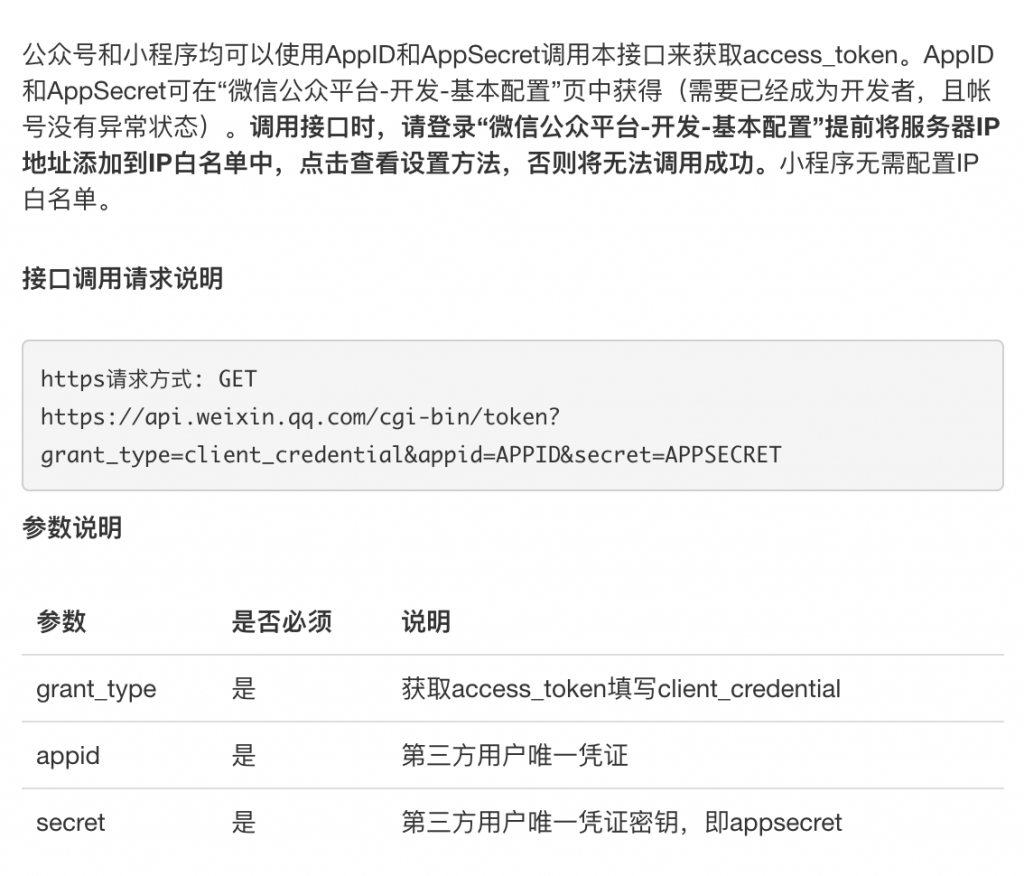
这里,容我多扯一句,微信公从平台的开发文档中,使用了OAuth 2.0 的 Client Credentials的方式(参看文档“微信公众号获取access token”),我截了个图如下所谓。我们可以看到,微信公众号使用的是GET方式的请求,把AppID和AppSecret放在了URL中,虽然这也符合OAuth 2.0,但是并不好,因为大多数网关代理会把整个URI请求记到日志中。我们只要脑补一下腾讯的网关的Access Log,里面的日志一定会有很多的各个用户的AppID和AppSecret……
2.17.7 总结
讲了这么多,我们来小结一下(下面的小结可能会有点散)
两个概念和三个术语
- 区分两个概念:Authentication(认证) 和 Authorization (授权),前者是证明请求者是身份,就像身份证一样,后者是为了获得权限。身份是区别于别人的证明,而权限是证明自己的特权。Authentication为了证明操作的这个人就是他本人,需要提供密码、短信验证码,甚至人脸识别。Authorization 则是不需要在所有的请求都需要验人,是在经过Authorization后得到一个Token,这就是Authorization。就像护照和签证一样。
- 区分三个概念:编码Base64Encode、签名HMAC、加密RSA。编码是为了更的传输,等同于明文,签名是为了信息不能被篡改,加密是为了不让别人看到是什么信息。
明白一些初衷
- 使用复杂地HMAC哈希签名方式主要是应对当年没有TLS/SSL加密链路的情况。
- JWT把
uid放在 Token中目的是为了去掉状态,但不能让用户修改,所以需要签名。 - OAuth 1.0区分了两个事,一个是第三方的Client,一个是真正的用户,其先拿Request Token,再换Access Token的方法主要是为了把第三方应用和用户区分开来。
- 用户的Password是用户自己设置的,复杂度不可控,服务端颁发的Serect会很复杂,但主要目的是为了容易管理,可以随时注销掉。
- OAuth 协议有比所有认证协议有更为灵活完善的配置,如果使用AppID/AppSecret签名的方式,又需要做到可以有不同的权限和可以随时注销,那么你得开发一个像AWS的IAM这样的账号和密钥对管理的系统。
相关的注意事项
- 无论是哪种方式,我们都应该遵循HTTP的规范,把认证信息放在
AuthorizationHTTP 头中。 - 不要使用GET的方式在URL中放入secret之类的东西,因为很多proxy或gateway的软件会把整个URL记在Access Log文件中。
- 密钥Secret相当于Password,但他是用来加密的,最好不要在网络上传输,如果要传输,最好使用TLS/SSL的安全链路。
- HMAC中无论是MD5还是SHA1/SHA2,其计算都是非常快的,RSA的非对称加密是比较耗CPU的,尤其是要加密的字符串很长的时候。
- 最好不要在程序中hard code 你的 Secret,因为在github上有很多黑客的软件在监视各种Secret,千万小心!这类的东西应该放在你的配置系统或是部署系统中,在程序启动时设置在配置文件或是环境变量中。
- 使用AppID/AppSecret,还是使用OAuth1.0a,还是OAuth2.0,还是使用JWT,我个人建议使用TLS/SSL下的OAuth 2.0。
- 密钥是需要被管理的,管理就是可以新增可以撤销,可以设置账户和相关的权限。最好密钥是可以被自动更换的。
- 认证授权服务器(Authorization Server)和应用服务器(App Server)最好分开。
2.18 消除http瓶颈之Websocket
Google 在 2010 年发布了 SPDY。想想下面的这些场景,海量的用户发布内容,为了实时的更新,客服端需要不断的和服务端进行通信,但是http存在着下面的制约:
- 一条连接上只可发送一个请求。
- 请求只能从客户端开始。客户端不可以接收除响应以外的指令。
- 请求 / 响应首部未经压缩就发送。首部信息越多延迟越大。
- 发送冗长的首部。每次互相发送相同的首部造成的浪费较多。
- 可任意选择数据压缩格式。非强制压缩发送。
然后人们提出了Ajax(Asynchronous JavaScript and XML, 异 步 JavaScript 与 XML 技 术)技术,达到局部 Web 页面替换加载的异步通信手 段。和以前的同步通信相比,由于它只更新一部分页面,响应中传输 的数据量会因此而减少,这一优点显而易见。
Ajax 的核心技术是名为 XMLHttpRequest 的 API,通过 JavaScript 脚本 语言的调用就能和服务器进行 HTTP 通信。借由这种手段,就能从已 加载完毕的 Web 页面上发起请求,只更新局部页面。
而利用 Ajax 实时地从服务器获取内容,有可能会导致大量请求产 生。另外,Ajax 仍未解决 HTTP 协议本身存在的问题。
人们又提出了Comet技术,一旦服务器端有内容更新了,Comet 不会让请求等待,而是直接给客户端返回响应。这是一种通过延迟应答,模拟实现服务器端向客户端 推送(Server Push)的功能。通常,服务器端接收到请求,在处理完毕后就会立即返回响应,但为 了实现推送功能,Comet 会先将响应置于挂起状态,当服务器端有内 容更新时,再返回该响应。因此,服务器端一旦有更新,就可以立即 反馈给客户端。
内容上虽然可以做到实时更新,但为了保留响应,一次连接的持续时 间也变长了。期间,为了维持连接会消耗更多的资源。另外,Comet 也仍未解决 HTTP 协议本身存在的问题。
总结下:由拉变成了推。
我们可以看到,Ajax和Comet技术仍然存在着问题,我们推出了SPDY协议,想要消除http的瓶颈。我们来看下,SPDY 没有完全改写 HTTP 协议,而是在 TCP/IP 的应用层与运输层之 间通过新加会话层的形式运作。同时,考虑到安全性问题,SPDY 规 定通信中使用 SSL。
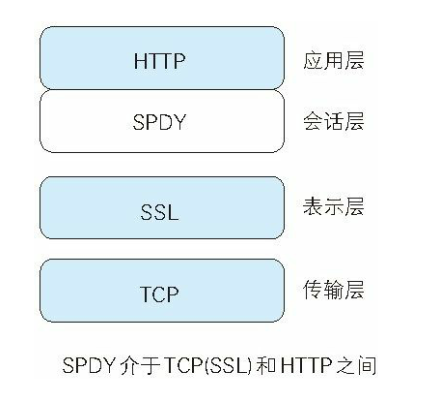
我们可以看到,使用 SPDY 后,HTTP 协议额外获得以下功能:
- 多路复用流
- 通过单一的 TCP 连接,可以无限制处理多个 HTTP 请求。所有请求 的处理都在一条 TCP 连接上完成,因此 TCP 的处理效率得到提高。
- 赋予请求优先级
- SPDY 不仅可以无限制地并发处理请求,还可以给请求逐个分配优先 级顺序。这样主要是为了在发送多个请求时,解决因带宽低而导致响 应变慢的问题。
- 压缩HTTP首部
- 压缩 HTTP 请求和响应的首部。这样一来,通信产生的数据包数量和发送的字节数就更少了。
- 推送功能
- 支持服务器主动向客户端推送数据的功能。这样,服务器可直接发送数据,而不必等待客户端的请求。
- 服务器提示功能
- 服务器可以主动提示客户端请求所需的资源。由于在客户端发现资源 之前就可以获知资源的存在,因此在资源已缓存等情况下,可以避免发送不必要的请求。
我们可以看到SPDY的确发挥了很大的作用,但是真的这么完美吗?
Web 的内容端不必做什么特别改动,而 Web 浏 览器及 Web 服务器都要为对应 SPDY 做出一定程度上的改动。有好 几家 Web 浏览器已经针对 SPDY 做出了相应的调整。另外,Web 服 务器也进行了实验性质的应用,但把该技术导入实际的 Web 网站却 进展不佳。因为 SPDY 基本上只是将单个域名( IP 地址)的通信多路复用,所 以当一个 Web 网站上使用多个域名下的资源,改善效果就会受到限 制。
由于上面问题的存在,我们引入了「使用浏览器进行全双工通信的 WebSocket」。
利用 Ajax 和 Comet 技术进行通信可以提升 Web 的浏览速度。但问题 在于通信若使用 HTTP 协议,就无法彻底解决瓶颈问题。WebSocket 网络技术正是为解决这些问题而实现的一套新协议及 API。当时筹划将 WebSocket 作为 HTML5 标准的一部分,而现在它却逐渐 变成了独立的协议标准。WebSocket 通信协议在 2011 年 12 月 11 日, 被 RFC 6455 - The WebSocket Protocol 定为标准。
我们先来看下Websocket的设计与功能:
WebSocket,即 Web 浏览器与 Web 服务器之间全双工通信标准。其 中,WebSocket 协议由 IETF 定为标准,WebSocket API 由 W3C 定为 标准。仍在开发中的 WebSocket 技术主要是为了解决 Ajax 和 Comet 里 XMLHttpRequest 附带的缺陷所引起的问题。
我们来看下这个协议:
一旦 Web 服务器与客户端之间建立起 WebSocket 协议的通信连接, 之后所有的通信都依靠这个专用协议进行。通信过程中可互相发送 JSON、XML、HTML 或图片等任意格式的数据。由于是建立在 HTTP 基础上的协议,因此连接的发起方仍是客户端, 而一旦确立 WebSocket 通信连接,不论服务器还是客户端,任意一方 都可直接向对方发送报文。我们来看其特点:
-
推送功能:支持由服务器向客户端推送数据的推送功能。这样,服务器可直接发 送数据,而不必等待客户端的请求。
-
减少通信量:只要建立起 WebSocket 连接,就希望一直保持连接状态。和 HTTP 相 比,不但每次连接时的总开销减少,而且由于 WebSocket 的首部信息 很小,通信量也相应减少了。为了实现 WebSocket 通信,在 HTTP 连接建立之后,需要完成一 次“握手”(Handshaking)的步骤。
-
握手·请求:为了实现 WebSocket 通信,需要用到 HTTP 的 Upgrade 首部字段,告知服务器通信协议发生改变,以达到握手的目的。
GET /chat HTTP/1.1 Host: server.example.com Upgrade: websocket Connection: Upgrade Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ== Origin: http://example.com Sec-WebSocket-Protocol: chat, superchat Sec-WebSocket-Version: 13- Sec-WebSocket-Key 字段内记录着握手过程中必不可少的键值。 Sec-WebSocket-Protocol 字段内记录使用的子协议。子协议按 WebSocket 协议标准在连接分开使用时,定义那些连接 的名称。
-
握手·响应:对于之前的请求,返回状态码 101 Switching Protocols 的响应。
HTTP/1.1 101 Switching Protocols Upgrade: websocket Connection: Upgrade Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo= Sec-WebSocket-Protocol: chat- Sec-WebSocket-Accept 的字段值是由握手请求中的 Sec- WebSocket-Key 的字段值生成的。成功握手确立 WebSocket 连接之后,通信时不再使用 HTTP 的数 据帧,而采用 WebSocket 独立的数据帧。
-
-
WebSocket API
-
var socket = new WebSocket('ws://game.example.com:12010 socket.onopen = function () { setInterval(function() { if (socket.bufferedAmount == 0) socket.send(getUpdateData()); }, 50); };
-
2.19 静态服务器到动态服务器
最初我们看到的内容都是别人编写好的html,当然静态的html不能满足我们的需求,我们希望服务器可以返回动态的内容。第一个解决方案是CGI,CGI(Common Gateway Interface,通用网关接口)是指 Web 服务器在接收到客户端发送过来的请求后转发给程序的一组机制。 比如php等语言。标准是RFC3875。
当然,CGI没有一家独大,Java推出了Servlet(Server+Applet,表示轻量服务程序)。
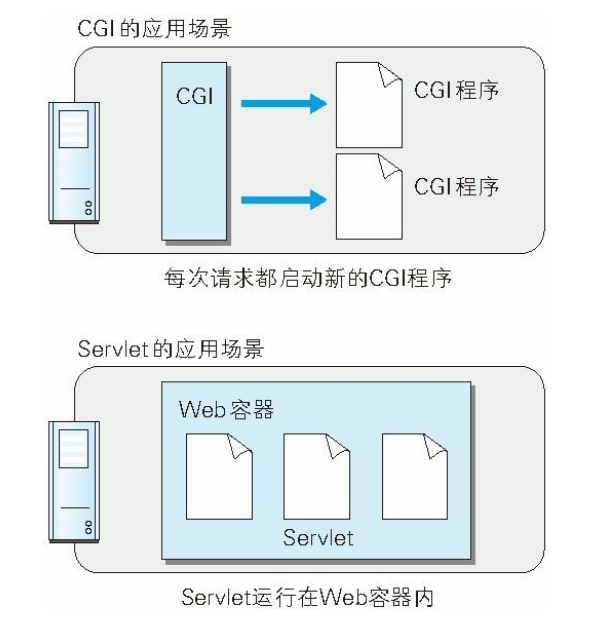
我们可以看到CGI,由于每次接到请求,程序都要跟着启动一次。因此 一旦访问量过大,Web 服务器要承担相当大的负载。而 Servlet 运行 在与 Web 服务器相同的进程中,因此受到的负载较小。
3. HTTP幂等性概念和应用
基于HTTP协议的Web API是时下最为流行的一种分布式服务提供方式。无论是在大型互联网应用还是企业级架构中,我们都见到了越来越多的SOA或RESTful的Web API。为什么Web API如此流行呢?我认为很大程度上应归功于简单有效的HTTP协议。HTTP协议是一种分布式的面向资源的网络应用层协议,无论是服务器端提供Web服务,还是客户端消费Web服务都非常简单。再加上浏览器、Javascript、AJAX、JSON以及HTML5等技术和工具的发展,互联网应用架构设计表现出了从传统的PHP、JSP、ASP.NET等服务器端动态网页向Web API + RIA(富互联网应用)过渡的趋势。Web API专注于提供业务服务,RIA专注于用户界面和交互设计,从此两个领域的分工更加明晰。在这种趋势下,Web API设计将成为服务器端程序员的必修课。然而,正如简单的Java语言并不意味着高质量的Java程序,简单的HTTP协议也不意味着高质量的Web API。要想设计出高质量的Web API,还需要深入理解分布式系统及HTTP协议的特性。
幂等性定义
本文所要探讨的正是HTTP协议涉及到的一种重要性质:幂等性(Idempotence)。在HTTP/1.1规范中幂等性的定义是:
Methods can also have the property of “idempotence” in that (aside from error or expiration issues) the side-effects of N > 0 identical requests is the same as for a single request.
从定义上看,HTTP方法的幂等性是指一次和多次请求某一个资源应该具有同样的副作用。幂等性属于语义范畴,正如编译器只能帮助检查语法错误一样,HTTP规范也没有办法通过消息格式等语法手段来定义它,这可能是它不太受到重视的原因之一。但实际上,幂等性是分布式系统设计中十分重要的概念,而HTTP的分布式本质也决定了它在HTTP中具有重要地位。
分布式事务 vs 幂等设计
为什么需要幂等性呢?我们先从一个例子说起,假设有一个从账户取钱的远程API(可以是HTTP的,也可以不是),我们暂时用类函数的方式记为
bool` `withdraw(account_id, amount);
withdraw的语义是从account_id对应的账户中扣除amount数额的钱;如果扣除成功则返回true,账户余额减少amount;如果扣除失败则返回false,账户余额不变。值得注意的是:和本地环境相比,我们不能轻易假设分布式环境的可靠性。一种典型的情况是withdraw请求已经被服务器端正确处理,但服务器端的返回结果由于网络等原因被掉丢了,导致客户端无法得知处理结果。如果是在网页上,一些不恰当的设计可能会使用户认为上一次操作失败了,然后刷新页面,这就导致了withdraw被调用两次,账户也被多扣了一次钱。如图1所示:
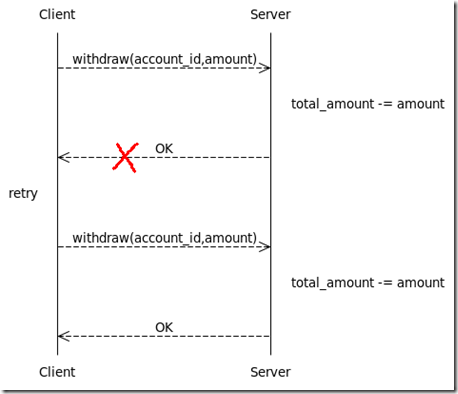
图1
这个问题的解决方案一是采用分布式事务,通过引入支持分布式事务的中间件来保证withdraw功能的事务性。分布式事务的优点是对于调用者很简单,复杂性都交给了中间件来管理。缺点则是一方面架构太重量级,容易被绑在特定的中间件上,不利于异构系统的集成;另一方面分布式事务虽然能保证事务的ACID性质,而但却无法提供性能和可用性的保证。
另一种更轻量级的解决方案是幂等设计。上面的withdraw显然不满足幂等性,但我们可以一些技巧将它变成幂等的,比如:
int` `create_ticket();` `bool` `idempotent_withdraw(ticket_id, account_id, amount);
create_ticket的语义是获取一个服务器端生成的唯一的处理号ticket_id,它将用于标识后续的操作。idempotent_withdraw和withdraw的区别在于关联了一个ticket_id,一个ticket_id表示的操作至多只会被处理一次,每次调用都将返回第一次调用时的处理结果。这样,idempotent_withdraw就符合幂等性了,客户端就可以放心地多次调用。
基于幂等性的解决方案中一个完整的取钱流程被分解成了两个步骤:1.调用create_ticket()获取ticket_id;2.调用idempotent_withdraw(ticket_id, account_id, amount)。虽然create_ticket不是幂等的,但在这种设计下,它对系统状态的影响可以忽略,加上idempotent_withdraw是幂等的,所以任何一步由于网络等原因失败或超时,客户端都可以重试,直到获得结果。如图2所示:
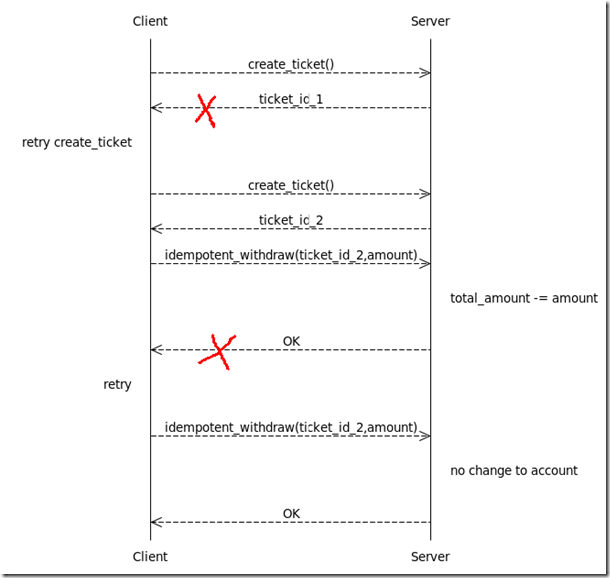
和分布式事务相比,幂等设计的优势在于它的轻量级,容易适应异构环境,以及性能和可用性方面。在某些性能要求比较高的应用,幂等设计往往是唯一的选择。
HTTP的幂等性
HTTP协议本身是一种面向资源的应用层协议,但对HTTP协议的使用实际上存在着两种不同的方式:一种是RESTful的,它把HTTP当成应用层协议,比较忠实地遵守了HTTP协议的各种规定;另一种是SOA的,它并没有完全把HTTP当成应用层协议,而是把HTTP协议作为了传输层协议,然后在HTTP之上建立了自己的应用层协议。本文所讨论的HTTP幂等性主要针对RESTful风格的,不过正如上一节所看到的那样,幂等性并不属于特点的协议,它是分布式系统的一种特性;所以,不论是SOA还是RESTful的Web API设计都应该考虑幂等性。下面将介绍HTTP GET、DELETE、PUT、POST四种主要方法的语义和幂等性。
HTTP GET方法用于获取资源,不应有副作用,所以是幂等的。比如:GET http://www.bank.com/account/123456,不会改变资源的状态,不论调用一次还是N次都没有副作用。请注意,这里强调的是一次和N次具有相同的副作用,而不是每次GET的结果相同。GET http://www.news.com/latest-news这个HTTP请求可能会每次得到不同的结果,但它本身并没有产生任何副作用,因而是满足幂等性的。
HTTP DELETE方法用于删除资源,有副作用,但它应该满足幂等性。比如:DELETE http://www.forum.com/article/4231,调用一次和N次对系统产生的副作用是相同的,即删掉id为4231的帖子;因此,调用者可以多次调用或刷新页面而不必担心引入错误。
比较容易混淆的是HTTP POST和PUT。POST和PUT的区别容易被简单地误认为“POST表示创建资源,PUT表示更新资源”;而实际上,二者均可用于创建资源,更为本质的差别是在幂等性方面。在HTTP规范中对POST和PUT是这样定义的:
The POST method is used to request that the origin server accept the entity enclosed in the request as a new subordinate of the resource identified by the Request-URI in the Request-Line. …… If a resource has been created on the origin server, the response SHOULD be 201 (Created) and contain an entity which describes the status of the request and refers to the new resource, and a Location header.
The PUT method requests that the enclosed entity be stored under the supplied Request-URI. If the Request-URI refers to an already existing resource, the enclosed entity SHOULD be considered as a modified version of the one residing on the origin server. If the Request-URI does not point to an existing resource, and that URI is capable of being defined as a new resource by the requesting user agent, the origin server can create the resource with that URI.
POST所对应的URI并非创建的资源本身,而是资源的接收者。比如:POST http://www.forum.com/articles的语义是在http://www.forum.com/articles下创建一篇帖子,HTTP响应中应包含帖子的创建状态以及帖子的URI。两次相同的POST请求会在服务器端创建两份资源,它们具有不同的URI;所以,POST方法不具备幂等性。
而PUT所对应的URI是要创建或更新的资源本身。比如:PUT http://www.forum/articles/4231的语义是创建或更新ID为4231的帖子。对同一URI进行多次PUT的副作用和一次PUT是相同的;因此,PUT方法具有幂等性。
在介绍了几种操作的语义和幂等性之后,我们来看看如何通过Web API的形式实现前面所提到的取款功能。很简单,用POST /tickets来实现create_ticket;用PUT /accounts/account_id/ticket_id&amount=xxx来实现idempotent_withdraw。值得注意的是严格来讲amount参数不应该作为URI的一部分,真正的URI应该是/accounts/account_id/ticket_id,而amount应该放在请求的body中。这种模式可以应用于很多场合,比如:论坛网站中防止意外的重复发帖。
总结
上面简单介绍了幂等性的概念,用幂等设计取代分布式事务的方法,以及HTTP主要方法的语义和幂等性特征。其实,如果要追根溯源,幂等性是数学中的一个概念,表达的是N次变换与1次变换的结果相同,有兴趣的读者可以从Wikipedia上进一步了解。




