
前言
这篇文章整理自网络,文末有参考来源。
.git目录

常用命令
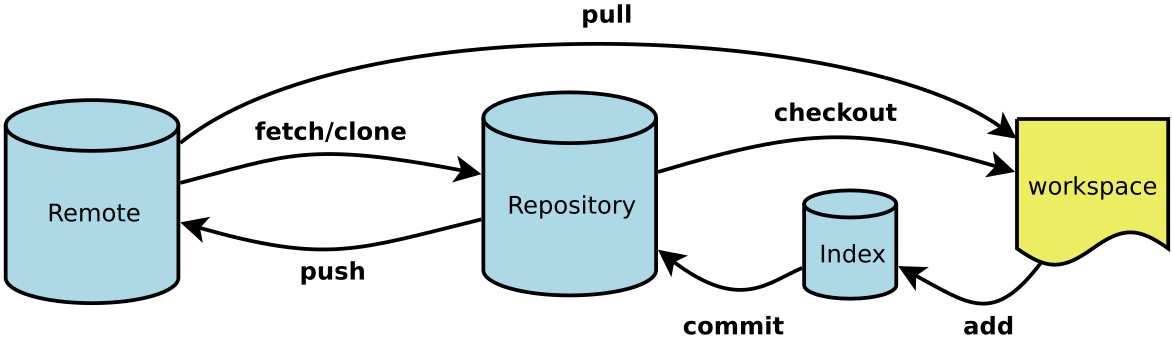
- Workspace:工作区(写代码的地方)
- Index / Stage:暂存区(add之后)
- 暂存区的优点
- review变化
- 合并冲突
- 暂存区的优点
- Repository:仓库区(或本地仓库,commit会后)
- Remote:远程仓库
新建仓库
# 在当前目录新建一个Git代码库
$ git init
# 新建一个目录,将其初始化为Git代码库
$ git init [project-name]
# 下载一个项目和它的整个代码历史
$ git clone [url]
配置
Git的设置文件为.gitconfig,它可以在用户主目录下(全局配置global),也可以在项目目录下(项目配置local)。
# 显示当前的Git配置
$ git config --list
# 编辑Git配置文件
$ git config -e [--global]
# 设置提交代码时的用户信息
$ git config [--global] user.name "[name]"
$ git config [--global] user.email "[email address]"
# 清除配置信息
git config --unset --local user.name
增加删除文件
# 添加指定文件到暂存区
$ git add [file1] [file2] ...
# 添加指定目录到暂存区,包括子目录
$ git add [dir]
# 添加当前目录的所有文件到暂存区
$ git add .
# 删除工作区文件,并且将这次删除放入暂存区
$ git rm [file1] [file2] ...
# 停止追踪指定文件,但该文件会保留在工作区
$ git rm --cached [file]
# 改名文件,并且将这个改名放入暂存区
$ git mv [file-original] [file-renamed]
代码提交
# 提交暂存区到仓库区
$ git commit -m [message]
# 提交暂存区的指定文件到仓库区
$ git commit [file1] [file2] ... -m [message]
# 提交工作区自上次commit之后的变化,直接到仓库区
$ git commit -a
# 提交时显示所有diff信息
$ git commit -v
# 使用一次新的commit,替代上一次提交
# 如果代码没有任何新变化,则用来改写上一次commit的提交信息
$ git commit --amend -m [message]
# 重做上一次commit,并包括指定文件的新变化
$ git commit --amend [file1] [file2] ...
# 修改历史的commit
# 需要注意的是,执行完下面的命令,不管是修改了文件内容,commit的message,作者,邮箱,都会影响当前commit以及以后的commit的id
git rebase -i commit_id
pick -> r
# 连续commit合并
git rebase -i commit_id
pick -> s
输入message
# rebase参数小结
pick:保留该commit
reword:保留该commit,修改信息
edit:保留commit,修改文件或者信息
squash:合并commit
fixup:合并commit,但是放弃commit信息
# 工作区恢复为暂存区
git checkout filename
git checkout *(所有的都恢复)
# 不同commit文件差异
git diff commit-id1 commit-id2 path-to-filename
# 代码暂存
git stash 把当前工作区的内容放入暂存区
git stash pop 把暂存区的内容恢复到工作区,且删除
git stash apply把暂存区的内容恢复到工作区,且保留
分支
# 列出所有本地分支
$ git branch
# 列出所有远程分支
$ git branch -r
# 列出所有本地分支和远程分支
$ git branch -a
# 新建一个分支,但依然停留在当前分支
$ git branch [branch-name]
# 新建一个分支,并切换到该分支
$ git checkout -b [branch]
# 新建一个分支,指向指定commit
$ git branch [branch] [commit]
# 新建一个分支,与指定的远程分支建立追踪关系
$ git branch --track [branch] [remote-branch]
# 切换到指定分支,并更新工作区
$ git checkout [branch-name]
# 切换到上一个分支
$ git checkout -
# 建立追踪关系,在现有分支与指定的远程分支之间
$ git branch --set-upstream [branch] [remote-branch]
# 合并指定分支到当前分支
$ git merge [branch]
$ git rebase [branch]
# 选择一个commit id,合并进当前分支
$ git cherry-pick [commit id]
# 删除分支
$ git branch -d [branch-name]
# 删除远程分支
$ git push origin --delete [branch-name]
$ git branch -dr [remote/branch]
在merge的时候,如果无法快速合并,比如这样,master和feacture都有了新的提交,且有冲突:
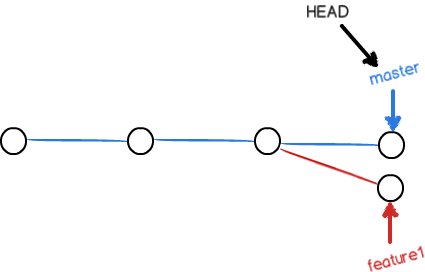
这个时候,git会把各自的commit进行合并。如果存在冲突,则需要手动解决冲突,在进行合并。

rebase:提交历史会成一条线;merge:提交历史会变成交织的网状(保留详细的merge的信息);第一幅图是merge,第二幅图是rebase。


在rebase的时候,如果遇到冲突,可以手动解决(也可以使用git checkout –theirs .,git add . / git checkout –ours . , git add .),解决好之后,可以git rebase –continue继续合并;
标签
# 列出所有tag
$ git tag
# 新建一个tag在当前commit
$ git tag [tag]
# 新建一个tag在指定commit
$ git tag [tag] [commit]
# 删除本地tag
$ git tag -d [tag]
# 删除远程tag
$ git push origin :refs/tags/[tagName]
# 查看tag信息
$ git show [tag]
# 提交指定tag
$ git push [remote] [tag]
# 提交所有tag
$ git push [remote] --tags
# 新建一个分支,指向某个tag
$ git checkout -b [branch] [tag]
查看信息
# 搜索提交历史,根据关键词 $ git log -S [keyword] # 显示某个commit之后的所有变动,每个commit占据一行 $ git log [tag] HEAD --pretty=format:%s # 显示某个commit之后的所有变动,其"提交说明"必须符合搜索条件 $ git log [tag] HEAD --grep feature # 显示某个文件的版本历史,包括文件改名 $ git log --follow [file] $ git whatchanged [file] # 显示指定文件相关的每一次diff $ git log -p [file] # 显示过去5次提交 $ git log -5 --pretty --oneline # 显示所有提交过的用户,按提交次数排序 $ git shortlog -sn # 显示指定文件是什么人在什么时间修改过 $ git blame [file] # 显示暂存区和工作区的差异 $ git diff # 显示暂存区和上一个commit的差异 $ git diff --cached [file] # 显示工作区与当前分支最新commit之间的差异 $ git diff HEAD # 显示两次提交之间的差异 $ git diff [first-branch]...[second-branch] # 显示今天你写了多少行代码 $ git diff --shortstat "@{0 day ago}" # 显示某次提交的元数据和内容变化 $ git show [commit] # 显示某次提交发生变化的文件 $ git show --name-only [commit] # 显示某次提交时,某个文件的内容 $ git show [commit]:[filename] # 显示当前分支的最近几次提交 $ git reflog
在Git中,用HEAD表示当前版本,上一个版本就是HEAD^,上上一个版本就是HEAD^^,当然往上100个版本写100个^比较容易数不过来,所以写成HEAD~100。
远程同步
# 下载远程仓库的所有变动
$ git fetch [remote]
# 显示所有远程仓库
$ git remote -v
# 显示某个远程仓库的信息
$ git remote show [remote]
# 增加一个新的远程仓库,并命名
$ git remote add [shortname] [url]
# 取回远程仓库的变化,并与本地分支合并
$ git pull [remote] [branch]
# 上传本地指定分支到远程仓库
$ git push [remote] [branch]
# 强行推送当前分支到远程仓库,即使有冲突
$ git push [remote] --force
# 推送所有分支到远程仓库
$ git push [remote] --all
撤销
# 丢弃工作区(或者暂存放到工作区) $ git checkout -- [file] # 恢复某个commit的指定文件到暂存区和工作区 $ git checkout [commit] [file] # 恢复暂存区的所有文件到工作区 $ git checkout . # 重置暂存区的指定文件,与上一次commit保持一致,但工作区不变 $ git reset [file] # 重置暂存区与工作区,与上一次commit保持一致 $ git reset --hard # 重置当前分支的指针为指定commit,同时重置暂存区,但工作区不变 $ git reset [commit] # 重置当前分支的HEAD为指定commit,同时重置暂存区和工作区,与指定commit一致 $ git reset --hard [commit] # 重置当前HEAD为指定commit,但保持暂存区和工作区不变 $ git reset --keep [commit] # 新建一个commit,用来撤销指定commit # 后者的所有变化都将被前者抵消,并且应用到当前分支 $ git revert [commit] # 暂时将未提交的变化移除,稍后再移入 $ git stash $ git stash pop
git协同工作流

中心式协同工作流
最一般的工作方式:
- 从服务器上做git pull origin master把代码同步下来。
- 改完后,git commit到本地仓库中。
- 然后git push origin master到远程仓库中,这样其他同学就可以得到你的代码了。
如果在第 3 步发现 push 失败,因为别人已经提交了,那么你需要先把服务器上的代码给 pull 下来,为了避免有 merge 动作,你可以使用 git pull –rebase 。这样就可以把服务器上的提交直接合并到你的代码中,对此,Git 的操作是这样的。
- 先把你本地提交的代码放到一边。
- 然后把服务器上的改动下载下来。
- 然后在本地把你之前的改动再重新一个一个地做 commit,直到全部成功。
如下图所示。Git 会把 Origin/Master 的远程分支下载下来(紫色的),然后把本地的 Master 分支上的改动一个一个地提交上去(蓝色的)。

如果有冲突,那么你要先解决冲突,然后做 git rebase –continue 。如下图所示,git 在做 pull –rebase 时,会一个一个地应用(apply)本地提交的代码,如果有冲突就会停下来,等你解决冲突。

功能分支协同工作流
上面的那种方式有一个问题,就是大家都在一个主干上开发程序,对于小团队或是小项目你可以这么干,但是对比较大的项目或是人比较多的团队,这么干就会有很多问题。
最大的问题就是代码可能干扰太严重。尤其是,我们想安安静静地开发一个功能时,我们想把各个功能的代码变动隔离开来,同时各个功能又会有多个开发人员在开发。
这时,我们不想让各个功能的开发人员都在 Master 分支上共享他们的代码。我们想要的协同方式是这样的:同时开发一个功能的开发人员可以分享各自的代码,但是不会把代码分享给开发其他功能的开发人员,直到整个功能开发完毕后,才会分享给其他的开发人员(也就是进入主干分支)。
因此,我们引入“功能分支”。这个协同工作流的开发过程如下。
- 首先使用 git checkout -b new-feature 创建 “new-feature”分支。
- 然后共同开发这个功能的程序员就在这个分支上工作,进行 add、commit 等操作。
- 然后通过 git push -u origin new-feature 把分支代码 push 到服务器上。
- 其他程序员可以通过git pull –rebase来拿到最新的这个分支的代码。
- 最后通过 Pull Request 的方式做完 Code Review 后合并到 Master 分支上。
GitFlow 协同工作流
在真实的生产过程中,前面的协同工作流还是不能满足工作的要求。这主要因为我们的生产过程是比较复杂的,软件生产中会有各式各样的问题,并要面对不同的环境。我们要在不停地开发新代码的同时,维护线上的代码,于是,就有了下面这些需求。
- 希望有一个分支是非常干净的,上面是可以发布的代码,上面的改动永远都是可以发布到生产环境中的。这个分支上不能有中间开发过程中不可以上生产线的代码提交。
- 希望当代码达到可以上线的状态时,也就是在 alpha/beta release 时,在测试和交付的过程中,依然可以开发下一个版本的代码。
- 最后,对于已经发布的代码,也会有一些 Bug-fix 的改动,不会将正在开发的代码提交到生产线上去。
你看,面对这些需求,前面的那些协同方式就都不行了。因为我们不仅是要在整个团队中共享代码,我们要的更是管理好不同环境下的代码不互相干扰。说得技术一点儿就是,要管理好代码与环境的一致性。
为了解决这些问题,GitFlow 协同工作流就出来了。
GitFlow 协同工作流是由 Vincent Driessen 于 2010 年在 A successful Git branching model 这篇文章介绍给世人的。这个协同工作流的核心思想如下图所示。

整个代码库中一共有五种分支。
- Master 分支。也就是主干分支,用作发布环境,上面的每一次提交都是可以发布的。
- Feature 分支。也就是功能分支,用于开发功能,其对应的是开发环境。
- Developer 分支。是开发分支,一旦功能开发完成,就向 Developer 分支合并,合并完成后,删除功能分支。这个分支对应的是集成测试环境。
- Release 分支。当 Developer 分支测试达到可以发布状态时,开出一个 Release 分支来,然后做发布前的准备工作。这个分支对应的是预发环境。之所以需要这个 Release 分支,是我们的开发可以继续向前,不会因为要发布而被 block 住而不能提交。
一旦 Release 分支上的代码达到可以上线的状态,那么需要把 Release 分支向 Master 分支和 Developer 分支同时合并,以保证代码的一致性。然后再把 Release 分支删除掉。
- Hotfix 分支。是用于处理生产线上代码的 Bug-fix,每个线上代码的 Bug-fix 都需要开一个 Hotfix 分支,完成后,向 Developer 分支和 Master 分支上合并。合并完成后,删除 Hotfix 分支。
这就是整个 GitFlow 协同工作流的工作过程。我们可以看到:
- 我们需要长期维护 Master 和 Developer 两个分支。
- 这其中的方式还是有一定复杂度的,尤其是 Release 和 Hotfix 分支需要同时向两个分支作合并。所以,如果没有一个好的工具来支撑的话,这会因为我们可能会忘了做一些操作而导致代码不一致。
- GitFlow 协同虽然工作流比较重。但是它几乎可以应对所有公司的各种开发流程,包括瀑布模型,或是快速迭代模型。
GitHub/GitLab 协同工作流
GitFlow 的问题
对于 GitFlow 来说,虽然可以解决我们的问题,但是也有很多问题。在 GitFlow 流行了一段时间后,圈内出现了一些不同的声音。
其中有个问题就是因为分支太多,所以会出现 git log 混乱的局面。具体来说,主要是 git-flow 使用git merge –no-ff来合并分支,在 git-flow 这样多个分支的环境下会让你的分支管理的 log 变得很难看。如下所示,左边是使用–no-ff 参数在多个分支下的问题。

所谓–no-ff参数的意思是——no fast forward的意思。也就是说,合并的方法不要把这个分支的提交以前置合并的方式,而是留下一个 merge 的提交。这是把双刃剑,我们希望我们的–no-ff能像右边那样,而不是像左边那样。
对此的建议是:只有 feature 合并到 developer 分支时,使用–no-ff 参数,其他的合并都不使用–no-ff参数来做合并。
另外,还有一个问题就是,在开发得足够快的时候,你会觉得同时维护 Master 和 Developer 两个分支是一件很无聊的事,因为这两个分支在大多数情况下都是一样的。包括 Release 分支,你会觉得创建的这些分支太无聊。
而你的整个开发过程也会因为这么复杂的管理变得非常复杂。尤其当你想回滚某些人的提交时,你就会发现这事似乎有点儿不好干了。而且在工作过程中,你会来来回回地切换工作的分支,有时候一不小心没有切换,就提交到了不正确的分支上,你还要回滚和重新提交,等等。
GitLab 一开始是 GitFlow 的坚定支持者,后来因为这些吐槽,以及 Hacker News 和 Reddit 上大量的讨论,GitLab 也开始不玩了。他们写了一篇 blog来创造了一个新的 Workflow——GitLab Flow,这个 GitLab Flow 是基于 GitHub Flow 来做的(参看: GitHub Flow )。
GitHub Flow
所谓 GitHub Flow,其实也叫 Forking flow,也就是 GitHub 上的那个开发方式。
- 每个开发人员都把“官方库”的代码 fork 到自己的代码仓库中。
- 然后,开发人员在自己的代码仓库中做开发,想干啥干啥。
- 因此,开发人员的代码库中,需要配两个远程仓库,一个是自己的库,一个是官方库(用户的库用于提交代码改动,官方库用于同步代码)。
- 然后在本地建“功能分支”,在这个分支上做代码开发。
- 这个功能分支被 push 到开发人员自己的代码仓库中。
- 然后,向“官方库”发起 pull request,并做 Code Review。
- 一旦通过,就向官方库进行合并。这就是 GitHub 的工作流程。
GitLab Flow
然而,GitHub Flow 这种玩法依然会有好多问题,因为其虽然变得很简单,但是没有把我们的代码和我们的运行环境给联系在一起。所以,GitLab 提出了几个优化点。
其中一个是引入环境分支,如下图所示,其包含了预发布(Pre-Production)和生产(Production)分支。

而有些时候,我们还会有不同版本的发布,所以,还需要有各种 release 的分支。如下图所示。Master 分支是一个 roadmap 分支,然后,一旦稳定了就建稳定版的分支,如 2.3.stable 分支和 2.4.stable 分支,其中可以 cherry-pick master 分支上的一些改动过去。

这样也就解决了两个问题:
-
环境和代码分支对应的问题;
-
版本和代码分支对应的问题。
协同工作流的本质
对于上面这些各式各样的工作流的比较和思考,虽然,我个人非常喜欢 GitHub Flow,在必要的时候使用上 GitLab 中的版本或环境分支。不过,我们现实生活中,还是有一些开发工作不是以功能为主,而是以项目为主的。也就是说,项目的改动量可能比较大,时间和周期可能也比较长。
我在想,是否有一种工作流,可以面对我们现实工作中的各种情况。但是,我想这个世界太复杂了,应该不存在一种一招鲜吃遍天的放之四海皆准的银弹方案。所以,我们还要根据自己的实际情况来挑选适合我们的协同工作的方式。
而代码的协同工作流属于 SCM(Software Configuration Management)的范畴,要挑选好适合自己的方式,我们需要知道软件工程配置管理的本质。
首先,我们知道软件开发的趋势一定是下面这个样子的。
- 以微服务或是 SOA 为架构的方式。一个大型软件会被拆分成若干个服务,那么,我们的代码应该也会跟着服务拆解成若干个代码仓库。这样一来,我们的每个代码仓库都会变小,于是我们的协同工作流程就会变简单。对于每个服务的代码仓库,我们的开发和迭代速度也会变得很快,开发团队也会跟服务一样被拆分成多个小团队。这样一来, GitFlow 这种协同工作流程就非常重了,而 GitHub 这种方式或是功能分支这种方式会更适合我们的开发。
- 以 DevOps 为主的开发流程。DevOps 关注于 CI/CD,需要我们有自动化的集成测试和持续部署的工具。这样一来,我们的代码发布速度就会大大加快,每一次提交都能很快地被完整地集成测试,并很快地发布到生产线上。




