
前言
索引是解决快速查找的问题。
索引是Mysql中的最为核心的概念之一。
核心概念

- 什么是索引?
- 索引是为了加速对表中数据行的检索而创建的一种分散存储的数据结构
- 为什么要索引?索引的核心是减少查找的IO次数
- 索引能极大的减少存储引擎需要扫描的数据量
- 索引可以把随机IO变成顺序IO
- 索引可以帮助我们在进行分组、排序等操作时,避免使用临时表
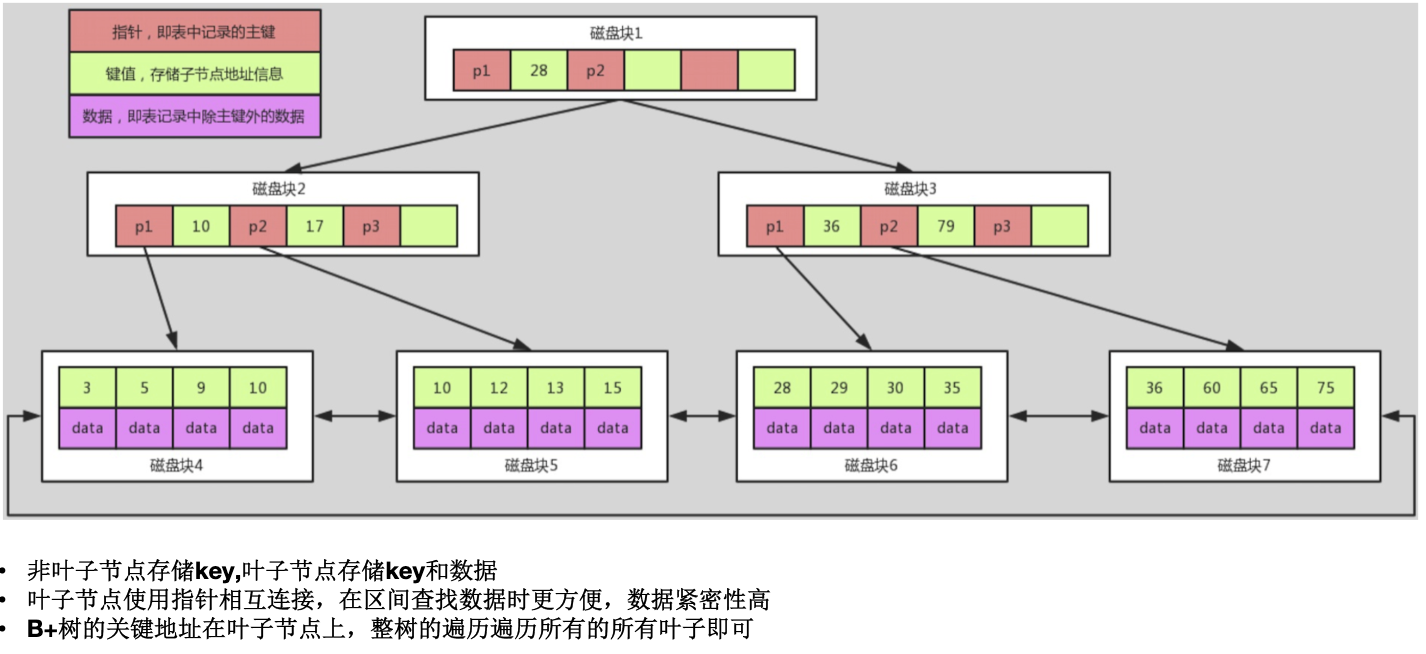
数据结构
为什么选择B+树?
索引划分
- 存储类型
- 主键索引(聚簇索引/聚集索引),PRIMARY KEY
- 二级索引(非聚集索引),SECONDARY KEY,需要回表
- 功能划分
- 唯一索引:unique key
- 联合索引
- 最左前缀匹配原则:索引项是按照索引定义里面出现的字段顺序排序的。
- 索引下推:在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
- 全文索引
- 覆盖索引:无需进行回表。索引已经覆盖了我们的查询需求。
索引下推举例:

select * from tuser where name like '张%' and age=10 and ismale=1;
<img src=”https://gitee.com/haojunsheng/ImageHost/raw/master/img/20220212155541.png” alt=”image-20220212155541394” style=”zoom:25%;” /
索引优化&慢查询优化
查询时间超过0.1秒
工具:Explain,Profile。
Profile:
- set profiling = 1;
- show profiles;
-
show profile for query id;
- 主键规范:有序主键能保证顺序io提升性能,无序主键是随机io,会导致聚簇索引的插入变成完成随机和频繁页分裂。
- good case:使用int/bitint类型自增id作为主键。
- bad case:使用uuid等无序数据作为主键。
- 使用前缀索引
- good case:大的列,只对部分进行索引
- 缺点:MySQL无法利用前缀索引做order by和group by 操作,也无法作为覆盖索引。
- 前缀区分度不高,如身份证号,解决办法
- 使用倒序存储:select * from T where id_card = reverse(‘input_id_card’)
- 使用hash
- 建立覆盖索引
- 使用区分度高的字段
- good case: 更新时间
- bad case:性别
- 尽量使用字段长度小的列作为索引
- good case: 姓名
- bad case:身份证号
- 使用Not Null的列(非空的列可以可以用0或者空串来代替)
- 最左匹配,如联合索引(a,b,c)
- 如果不是按照索引的最左列开始查找,则无法使用索引,如select * from t where b = ? and c = ?
- 不能跳过索引中的列,否则只能⽤用到索引前面的部分,如select * from t where a = ? and c = ?
- 如果查询中有某个列的范围查询,则其右边所有的列都无法用到索引优化,如select * from t where a > ? and c = ?
- 不要使用%进行前缀模糊查询,如like “%name”
- 禁止select *
- 避免使用Order by/Group by/Distinct,因为会产生临时表
- 避免索引失效
- 隐式转换,如select * from t where a = “2”,假设a是整形
- 避免在索引字段上进行运算,如select * from t where a -1= 2




